
来源:arxiv
编辑:白峰
【新智元导读】离线强化学习方法可以帮我们弥合强化学习研究与实际应用之间的差距。近日,Google和DeepMind推出的RL Unplugged使从离线数据集中学习策略成为可能,从而克服了现实世界中与在线数据收集相关的问题,包括成本,安全性等问题。
?
最近,Google Brain和DeepMind联合提出了一个称为RL Unplugged的基准,以评估和比较离线RL方法。RL Unplugged包含来自多个领域的数据,包括游戏(例如Atari基准测试)和模拟的电机控制等(例如DM Control Suite)。RL Unplugged为每个任务域提出了详细的评估方法,对监督学习和离线RL方法进行了广泛的分析,数据集包括部分或完全可观察的任务域,使用连续或离散的动作,并且具有随机性和非平稳性等,能很好地评估强化学习智能体的性能。
近年来,强化学习(RL)取得了重要突破,包括击败《星际争霸II》和DOTA人类玩家的长程决策(2019年),机器人的高维运动控制等(Akkaya等人,2019年)。但是,这些成功很大程度上取决于智能体与环境的反复在线交互。尽管在模拟方面取得了成功,但在现实中很难推广。发电厂,机器人,医疗保健系统或自动驾驶汽车的运行成本很高,这些场景下的试验可能会带来危险的后果。? ? ? ? ? ? ?在实时 RL 中,算法在线收集学习经验
? ? ? ?
? ? ? ?在实时 RL 中,算法在线收集学习经验
? ? ? ? ? ? ? ?在离线 RL 中,经验都是离线收集因此离线强化学习再度兴起。离线RL可以从离线的数据中学习新策略,而无需与环境进行任何真实的交互。RL 算法从这些离线数据集学习的能力,对于我们未来构建机器学习系统的方式有巨大的潜在影响。
? ? ? ?在离线 RL 中,经验都是离线收集因此离线强化学习再度兴起。离线RL可以从离线的数据中学习新策略,而无需与环境进行任何真实的交互。RL 算法从这些离线数据集学习的能力,对于我们未来构建机器学习系统的方式有巨大的潜在影响。之前,对 RL 进行离线基准测试的方法仅限于一个场景: 数据集来自某个随机或先前训练过的策略,算法的目标是提高原策略的性能。 这种方法的问题是,现实世界的数据集不可能由单一的 RL 训练的策略产生,而且这种方法不能泛化到其他的场景。?
缺乏基线让算法评估变得困难。在当前的离线RL研究中,实际应用领域的重要属性,高维感知流(例如图像),不同的动作空间等覆盖不全,非平稳性和随机性不足,使得现存的基准很难评估离线RL算法的实用性。因此,比较算法并确保其可重复性显得尤为重要,RL Unplugged的目的就是通过提出通用的基准,数据集,评估协议和代码来解决这些问题。具有强大基准的大型数据集一直是机器学习成功的主要因素。例如计算机视觉中最常使用的数据集ImageNet和COCO等,而强化学习中主要使用游戏数据,其中模拟器为在线RL智能体(例如AlphaGo)提供了丰富的数据,而缺少明确基准的数据集会阻碍RL的发展。? ? ? ? ? ? ? ?现实世界中的RL问题都需要通用的算法解决方案,并且可以在各种挑战中展现出强大的性能。我们的基准套件旨在涵盖一系列属性,以确定学习问题的难度并影响解决方案策略的选择。RL Unplugged的初始版本中包含了广泛的任务域,包括Atari游戏和模拟机器人任务。尽管所用环境的性质不同,RL Unplugged还是为数据集提供了统一的API。任何数据集中的每个条目都由状态(st),动作(at),奖励(rt),下一个状态(st + 1)和下一个动作(at + 1)组成。对于序列数据,还提供了将来的状态,动作和奖励,从而可以训练需要内存的任务。RL Unplugged的主要贡献:(i)统一的数据集API(ii)各种离线环境(iii)离线RL研究的评估协议(iv)参考基准。RL Unplugged中的数据集可将各种在线RL研究转为离线的,而无需处理RL的探索组件。?? ? ??
? ? ? ?现实世界中的RL问题都需要通用的算法解决方案,并且可以在各种挑战中展现出强大的性能。我们的基准套件旨在涵盖一系列属性,以确定学习问题的难度并影响解决方案策略的选择。RL Unplugged的初始版本中包含了广泛的任务域,包括Atari游戏和模拟机器人任务。尽管所用环境的性质不同,RL Unplugged还是为数据集提供了统一的API。任何数据集中的每个条目都由状态(st),动作(at),奖励(rt),下一个状态(st + 1)和下一个动作(at + 1)组成。对于序列数据,还提供了将来的状态,动作和奖励,从而可以训练需要内存的任务。RL Unplugged的主要贡献:(i)统一的数据集API(ii)各种离线环境(iii)离线RL研究的评估协议(iv)参考基准。RL Unplugged中的数据集可将各种在线RL研究转为离线的,而无需处理RL的探索组件。?? ? ?? 动作空间包括具有离散和连续动作空间以及可变动作维度(最多56个维度)的任务。观察空间包括可以从MDP的低维自然状态空间解决的任务,还包括由高维图像组成的任务(例如Atari 2600)等。部分可见性和对内存的需求部分,包括以特征向量完整表示MDP状态的任务,以及需要智能体整合不同长度范围内的信息来估计状态的任务。探索难度包括的任务因探索难度的不同而有所变化,可调整的属性有动作空间的大小,奖励的稀疏性或学习问题的范围。为了更好地反映现实系统中遇到的困难,我们还包括「现实世界中的RL挑战」任务,涵盖了动作延迟,随机过渡动态性和非平稳性等方面的内容。RL Unplugged引入了涵盖不同任务的数据集。例如,在Atari 2600上,使用的大型数据集是通过对多个种子进行策略外智能体培训而生成的。相反,对于RWRL套件,使用了来自固定的次优策略的数据。在严格的离线设置中,不允许进行环境交互。这使得超参数调整(包括确定何时停止训练过程)变得困难。这是因为我们无法采用由不同的超参数获得的策略,并在环境中运行它们来确定哪些策略获得更高的奖励。理想情况下,离线RL将仅使用离线数据来评估由不同的超参数获得的策略, 我们将此过程称为离线策略选择。在RL Unplugged中,我们想评估两种设置下的离线RL性能。? ? ? ?
动作空间包括具有离散和连续动作空间以及可变动作维度(最多56个维度)的任务。观察空间包括可以从MDP的低维自然状态空间解决的任务,还包括由高维图像组成的任务(例如Atari 2600)等。部分可见性和对内存的需求部分,包括以特征向量完整表示MDP状态的任务,以及需要智能体整合不同长度范围内的信息来估计状态的任务。探索难度包括的任务因探索难度的不同而有所变化,可调整的属性有动作空间的大小,奖励的稀疏性或学习问题的范围。为了更好地反映现实系统中遇到的困难,我们还包括「现实世界中的RL挑战」任务,涵盖了动作延迟,随机过渡动态性和非平稳性等方面的内容。RL Unplugged引入了涵盖不同任务的数据集。例如,在Atari 2600上,使用的大型数据集是通过对多个种子进行策略外智能体培训而生成的。相反,对于RWRL套件,使用了来自固定的次优策略的数据。在严格的离线设置中,不允许进行环境交互。这使得超参数调整(包括确定何时停止训练过程)变得困难。这是因为我们无法采用由不同的超参数获得的策略,并在环境中运行它们来确定哪些策略获得更高的奖励。理想情况下,离线RL将仅使用离线数据来评估由不同的超参数获得的策略, 我们将此过程称为离线策略选择。在RL Unplugged中,我们想评估两种设置下的离线RL性能。? ? ? ? (左)在线策略选择进行评估的流程(右)离线策略选择进行评估的流程在线策略选择进行评估(左),可以在线方式与环境互动来评估不同的超参数配置,让我们能够隔离评估离线RL方法的性能,但是它在许多现实环境中都是不可行的,因此,它对当前离线RL方法的实用性过于乐观。离线策略选择进行评估(右)并不受欢迎,但它确实很重要,因为它表明不完善的策略选择的鲁棒性,这更能反映离线RL对于实际问题的响应情况。但是它也有缺点,即存在许多设计选择,包括用于离线策略选择的数据,选择哪种离线策略评估算法等问题。两种方法的优劣还无定论,因此RL Unplugged的基准可使用在线和离线策略选择两种方法进行评估。对于每个任务域,RL Unplugged都对所包含的任务进行了详细描述,指出哪些任务是针对在线和离线策略选择的,并提供了相应的数据描述。
(左)在线策略选择进行评估的流程(右)离线策略选择进行评估的流程在线策略选择进行评估(左),可以在线方式与环境互动来评估不同的超参数配置,让我们能够隔离评估离线RL方法的性能,但是它在许多现实环境中都是不可行的,因此,它对当前离线RL方法的实用性过于乐观。离线策略选择进行评估(右)并不受欢迎,但它确实很重要,因为它表明不完善的策略选择的鲁棒性,这更能反映离线RL对于实际问题的响应情况。但是它也有缺点,即存在许多设计选择,包括用于离线策略选择的数据,选择哪种离线策略评估算法等问题。两种方法的优劣还无定论,因此RL Unplugged的基准可使用在线和离线策略选择两种方法进行评估。对于每个任务域,RL Unplugged都对所包含的任务进行了详细描述,指出哪些任务是针对在线和离线策略选择的,并提供了相应的数据描述。DM Control Suite,是在MuJoCo中实现的一组控制任务。
DM Locomotion,是涉及类人动物的运动任务。
Atari 2600,街机学习环境(ALE)套件,包含57套Atari 2600游戏(Atari57)。
Real-world Reinforcement Learning Suite,包括高维状态和动作空间,较大的系统延迟,系统约束,多目标,处理非平稳性和部分可观察性等任务。
RL Unplugged为连续(DM Control Suite,DM Locomotion)和离散动作(Atari 2600)任务提供了基线模型。一些算法仅适用于离散或连续动作空间,因此我们仅在它们适合的任务中提供了评估算法。?? ? ??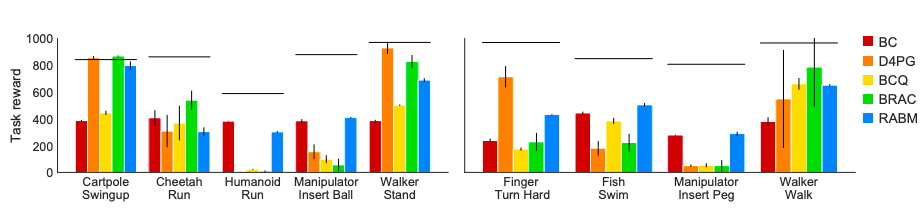 DM Control Suite Baselines.?(左)使用在线策略选择进行评估的结果(右)使用离线策略选择进行评估的结果D4PG,BRAC和RABM在较轻松的任务( Cartpole swingup.)中表现较好。但是BC和RABM在较艰巨的任务(Humanoid run)上表现最佳。展望未来,RL Unplugged将随着RL研究社区和DeepMind贡献的数据集逐渐发展壮大,离线学习也会在强化学习中占据自己的一席之地。https://arxiv.org/pdf/2006.13888v1.pdf
DM Control Suite Baselines.?(左)使用在线策略选择进行评估的结果(右)使用离线策略选择进行评估的结果D4PG,BRAC和RABM在较轻松的任务( Cartpole swingup.)中表现较好。但是BC和RABM在较艰巨的任务(Humanoid run)上表现最佳。展望未来,RL Unplugged将随着RL研究社区和DeepMind贡献的数据集逐渐发展壮大,离线学习也会在强化学习中占据自己的一席之地。https://arxiv.org/pdf/2006.13888v1.pdf?

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




