

来源 | 微软研究院AI头条(ID: MSRAsia)
编者按:基于深度学习的端到端语音合成技术进展显著,但经典自回归模型存在生成速度慢、稳定性和可控性差的问题。去年,微软亚洲研究院和微软 Azure 语音团队联合浙江大学提出了快速、鲁棒、可控的语音合成系统 FastSpeech,近日研究团队又将该技术升级,提出了 FastSpeech 2 和 FastSpeech 2s,在提升语音合成质量的同时,大大简化了训练流程,减少了训练时间,加快了合成速度。
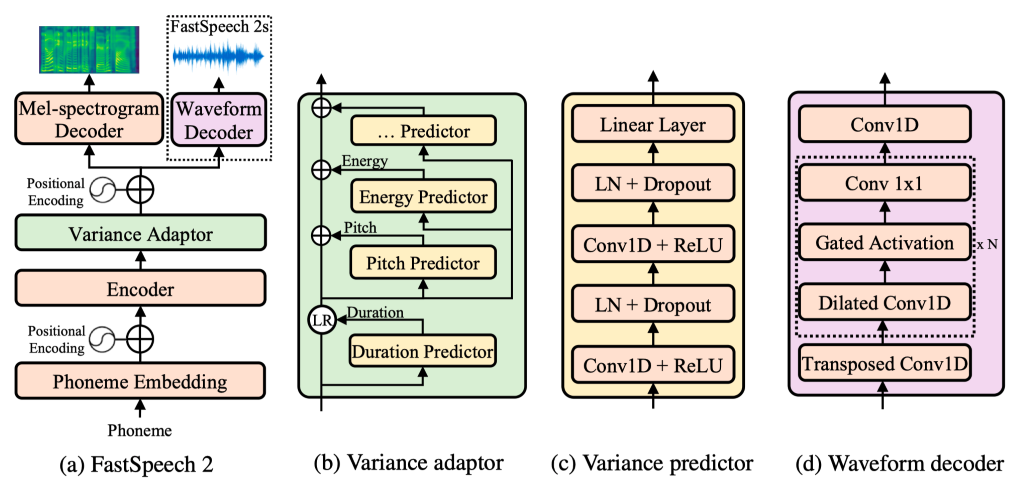
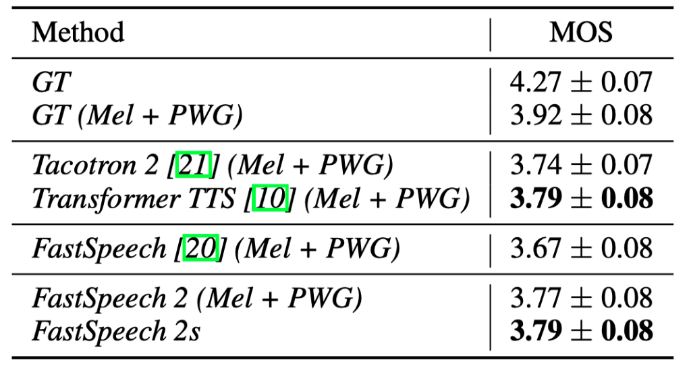
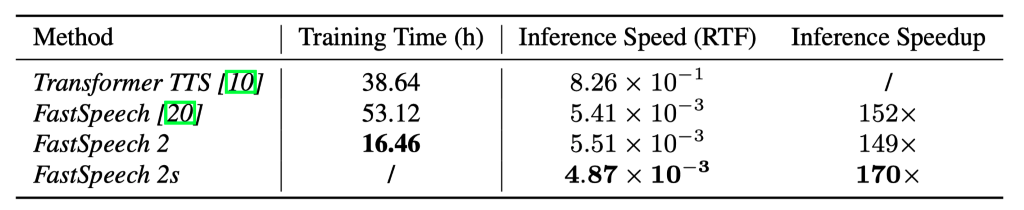
近年来,以 FastSpeech 为代表的非自回归语音合成(Text to Speech, TTS)模型相比传统的自回归模型(如 Tacotron 2)能极大提升合成速度,提升语音鲁棒性(减少重复吐词、漏词等问题)与可控性(控制速率和韵律),同时达到相匹配的语音合成质量。但是,FastSpeech 还面临以下几点问题:为了解决上述问题,微软亚洲研究院和微软 Azure 语音团队联合浙江大学提出了FastSpeech 的改进版 FastSpeech 2,它抛弃了 Teacher-Student 知识蒸馏框架降低训练复杂度,直接用真实的语音数据作为训练目标避免信息损失,同时引入了更精确的时长信息和语音中的其它可变信息(包括音高(Pitch)和音量(Energy)等)来提高合成的语音质量。基于 FastSpeech 2,我们还提出了加强版 FastSpeech 2s 以支持完全端到端的从文本到语音波形的合成,省略了梅尔频谱的生成过程。实验结果表明,FastSpeech 2 和 2s 在语音质量方面优于 FastSpeech,同时大大简化了训练流程减少了训练时间,还加快了合成的速度。FastSpeech 2 和 2s 的样例音频网址已经公开在:https://speechresearch.github.io/fastspeech2/论文公开在:https://arxiv.org/pdf/2006.04558.pdf图1:FastSpeech 2 和 2s 模型框架。图1(b)中的 LR 表示 FastSpeech 中的序列长度适配操作,图1(c)中的 LN 表示层归一化,可变信息预测器(variance predictor)包括时长、音高和能量预测器。FastSpeech 2 的模型架构如图1(a)所示,它沿用 FastSpeech 中提出的 Feed-Forward Transformer(FFT)架构,但在音素编码器和梅尔频谱解码器中加入了一个可变信息适配器(Variance Adaptor),从而支持在 FastSpeech 2 和 2s 中引入更多语音中变化的信息,例如时长、音高、音量(频谱能量)等,来解决语音合成中的一对多映射问题(文本到语音合成中,一条文本可以对应到多条可变的语音,这些可变信息包括语音时长、音高、音量等。FastSpeech 通过知识蒸馏降低语音训练目标的变化性来缓解一对多映射问题,但也造成了训练目标的信息损失。FastSpeech 2 通过引入对应的可变信息作为解码器输入,使输入输出信息尽量匹配,来解决这个问题)。可变信息适配器(Variance Adaptor)可变信息适配器如图1(b)所示,包含了多种可变信息的预测器。在本工作中引入了时长预测器、音高预测器和能量预测器。在训练时,模型直接使用可变信息的真实值,与编码器的输出融合,作为解码器的输入,同时训练预测器使其拟合真实的可变信息。在推理阶段,模型使用预测器预测的可变信息。可变信息预测器如图1(c)所示,由 ReLU 激活的2层一维卷积网络组成,每个网络后加上 Layer Norm 和 Dropout,以及最后输出标量的线性层。这个模块堆叠在音素编码器之上,并与 FastSpeech 2 模型共同训练,使用均方误差(MSE)作为损失函数。可变信息预测器的输出是对应的可变信息序列。其中音高预测器的输出是梅尔频谱对应的音高序列,能量预测器的输出是梅尔频谱的能量序列,而时长预测器的输出是音素的时长序列,与 FastSpeech 中的时长信息提取方式(使用自回归 Teacher 模型提取时长信息)不同,FastSpeech 2 使用一种开源的文字语音对齐工具(Montreal Forced Aligner, MFA)来提取更精准的时长信息。在 FastSpeech 2 的基础上,我们提出了 FastSpeech 2s 以实现完全端到端的文本到语音波形的合成。FastSpeech 2s 引入了一个波形解码器,如图1(d)所示,它以可变信息适配器的输出隐层序列为输入,以波形为输出。在训练时,为了帮助可变信息预测器的训练,梅尔频谱解码器及其训练损失函数被保留。在生成阶段,将梅尔频谱解码器丢弃后,使其成为一个文本到波形的端到端系统。为了验证 FastSpeech 2 和 2s 的有效性,我们从声音质量、训练和生成速度、可变信息分析、可控制性几个方面来进行评估和分析。我们选用 LJSpeech 数据集进行实验,LJSpeech 包含13100个英语音频片段和相应的文本,音频的总长度约为24小时,并对测试样本作了权威的 MOS 测试,每个样本至少被20个英语母语评测者评测。MOS 指标用来衡量声音接近人声的自然度和音质。对比我们的方法与以下语音样本:1) GT(Ground Truth),真实音频数据;2) GT (Mel + PWG),用 Parallel WaveGAN(PWG)作为声码器(Vocoder)将真实梅尔频谱转换得到的音频;3) Tacotron 2 (Mel + PWG);4) Transformer TTS (Mel + PWG);5) FastSpeech(Mel + PWG)。从结果(如表1所示)中可以看出,FastSpeech 2 和 2s 的音质优于 FastSpeech,这证明了利用真实语音目标来训练模型的优势,同时也显示了通过提供额外的可变信息(音高、能量和更准确的音素时长)以解决一对多映射的有效性。我们将 FastSpeech 2 和 2s 与具有相似参数量的 FastSpeech 的训练速度和合成语音速度作对比(结果如表2所示)。可以看出,在训练速度上,由于 FastSpeech 2 去除了蒸馏的过程,该模型可以实现3倍的训练加速。在合成语音速度上,它可以在单卡上实现近205倍实时的毫秒级的端到端语音合成。在波形生成速度上,比自回归的 Transformer TTS 提速将近170倍。表2: FastSpeech 2 和 2s 与 FastSpeech 的训练速度和合成速度作对比。RTF 代表合成1秒的音频需要的时间。训练和测试的时间统计均在 36 Intel Xeon CPU,256GB内存和单张 V100 GPU 上进行,批大小分别是48和1。?FastSpeech 2 可以在模型中调节语速、音高和能量。这里展示音高调节效果,通过实验发现,将音高降低到 0.75x 或者升高到 1.5x,生成的语音均很清晰且不失真(结果如图2所示)。图2:音高调节实验。红色曲线代表修改后的基频曲线。对应的文本是:“They discarded this for a more completely Roman and far less beautiful letter.”?我们也比较了模型中一些重要组件和方法(包括引入音高、能量和更准确的时长信息)对生成音质效果的影响,通过 CMOS 的结果来衡量影响程度。由表3和表4可以看出,这些组件和方法确实有助于模型效果的提高。表3:从 Teacher 模型和 MFA 得到的 Duration 对比未来,我们将在 FastSpeech 2 中尝试引入更多的可变信息来提高并行语音合成的音质,并且尝试更加轻量的模型,从而进一步提升生成语音的速度。我们一直致力于语音方面的研究,包括文本到语音合成、低资源语音合成与识别、语音翻译、歌声及音乐合成等。欢迎关注我们语音方面的研究工作:https://speechresearch.github.io/
[1] FastSpeech: Fast, Robust and Controllable Text to Speechpaper: https://arxiv.org/pdf/1905.09263.pdfdemo: https://speechresearch.github.io/fastspeech/article (Chinese): https://mp.weixin.qq.com/s/aHupAjPNFdUdaG9Uof_obQarticle (English): https://www.microsoft.com/en-us/research/blog/fastspeech-new-text-to-speech-model-improves-on-speed-accuracy-and-controllability/[2] FastSpeech 2: Fast and High-Quality End-to-End Text to Speechpaper: https://arxiv.org/pdf/2006.04558.pdfdemo: https://speechresearch.github.io/fastspeech2/
本文作者:任意、胡晨旭、谭旭、秦涛、赵晟、赵洲、刘铁岩
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/















 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




