
什么是Python的迭代器和生成器?(附代码)
迭代器:一次一个!

Python数据科学:
https://courses.analyticsvidhya.com/courses/introduction-to-data-science?utm_source=blog&utm_medium=python-iterators-and-generators
这是我们要介绍的内容:
什么是可迭代对象?
什么是Python迭代器?
在Python中创建一个迭代器
熟悉Python中的生成器
实现Python中的生成器表达式
为什么你应该使用迭代器?
什么是可迭代对象?
#?iterables??sample?=?['data?science',?'business?analytics',?'machine?learning']??for?i?in?sample:??????print(i)

什么是Python迭代器?
sample?=?['data?science',?'business?analytics',?'machine?learning']??#?generating?an?iterator??it?=?sample.__iter__()??print(it)??#?iterables?do?not?have?__next__()?method??sample.__next__()??
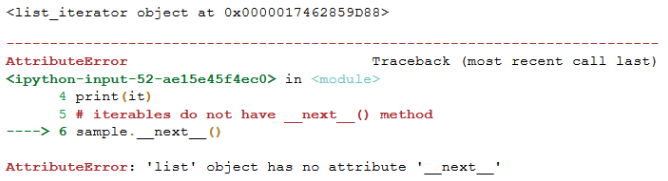
sample?=?['data?science',?'business?analytics',?'machine?learning']??#?generating?an?iterator??it?=?sample.__iter__()??print(it.__next__())??print(it.__next__())??print(it.__next__())?

sample?=?['data?science',?'business?analytics',?'machine?learning']??it?=?sample.__iter__()??itit?=?it.__iter__()??print(type(itit))??print(itit.__next__())??print(itit.__next__())??print(itit.__next__())??

sample?=?['statistics',?'linear?algebra',?'probability']????#?iterator??it?=?iter(sample)????#?next?values??print(next(it))??print(next(it))??print(next(it))

print(next(it))??
sample?=?['statistics',?'linear?algebra',?'probability']??it?=?iter(sample)??while?True:??????#?this?will?execute?till?an?error?is?raised??????try:??????????val?=?next(it)??????#?when?we?reach?end?of?the?list,?error?is?raised?and?we?break?out?of?the?loop??????except?StopIteration:??????????break??????print(val)?

在Python中创建一个迭代器
class?Sequence():??????def?__init__(self):??????????self.num?=?2??????def?__iter__(self):??????????return?self??????def?__next__(self):??????????val?=?self.num??????????self.num?+=?2??????????return?val?
__init __()方法是类构造函数,调用类时会首先执行该函数。它用于分配程序执行期间类最初所需的任何值。我在这里设置num变量的初始值为2;
iter()和next()方法使这个类变成了迭代器;
iter()方法返回迭代器对象并对迭代进行初始化。由于类对象本身是迭代器,因此它返回自身;
next()方法从迭代器中返回当前值,并改变下一次调用的状态。我们将num变量的值加2,因为我们只打印偶数。
it?=?Sequence()??print(next(it))??print(next(it))??print(next(it))??print(next(it))??print(next(it))?
?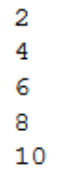
class?Sequence():??????def?__init__(self):??????????self.num?=?2??????def?__iter__(self):??????????return?self??????def?__next__(self):??????????val?=?self.num??????????if?val>=10:??????????????raise?StopIteration??????????self.num?+=?2??????????return?val????
it?=?Sequence()??for?i?in?it:???????print(i)

熟悉Python中的生成器
#?fibonacci?sequence?using?a?generator???def?fib():?????????prev,?curr?=?0,?1??????#?infinite?loop??????while?prev<5:??????????value?=?prev??????????#?Calculate?the?next?number?in?the?sequence.?Using?Tuple?unpacking.??????????prev,?curr?=?curr,?prev?+?curr??????????#?yield?the?value??????????yield?value??
#?generator?object??gen=fib()??print(gen)??#?values??print(next(gen))??print(next(gen))??print(next(gen))??print(next(gen))??print(next(gen))??

print(next(gen))
实现Python中的生成器表达式
squared_gen?=?(x*x?for?x?in?range(2,5))??print(squared_gen)
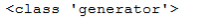
for?i?in?squared_gen:??????print(i)?
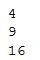
为什么你应该使用迭代器?
import?sys??#?list?comprehension??mylist?=?[i?for?i?in?range(10000000)]??print('Size?of?list?in?memory',sys.getsizeof(mylist))??#?generator?expression??mygen?=?(i?for?i?in?range(10000000))??print('Size?of?generator?in?memory',sys.getsizeof(mygen)

file?=?"Greetings.txt"??#?generator?expression??lines?=?(line?for?line?in?open(file))??print(lines)??#?print?lines??print(next(lines))??print(next(lines))??print(next(lines))?

import?pandas?as?pd????#?pandas?dataframe??df?=?pd.read_csv('./Black?Friday.csv',?chunksize=10)????#?print?first?chunk?of?data??next(df)
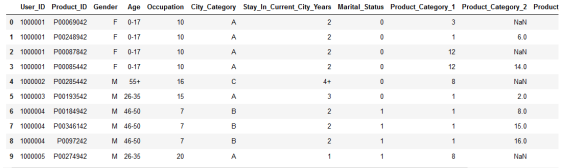
#?print?second?chunk?of?data??next(df)??
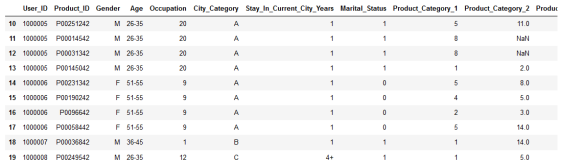
结语
本文转自:数据派THU ;获授权;
END
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675