
面试问Redis集群,被虐的不行了......
上一篇我们讲解了 Redis 哨兵的工作原理,哨兵主要针对单节点故障无法自动恢复的解决方案,集群主要针对单节点容量、并发问题、线性可扩展性的解决方案。

图片来自 Pexels
本篇我将讲解 Redis 集群的工作原理,文末有你们想要的设置 SSH 背景哦!
本文主要围绕如下几个方面介绍集群:
集群简介
集群作用
配置集群
手动、自动故障转移
故障转移原理
本文实现环境:
CentOS?7.3
Redis 4.0
Redis 工作目录 /usr/local/redis
所有操作均在虚拟机模拟进行
集群简介
同时数据量能达到这个地步写数据量也会很大,容易造成缓冲区溢出,造成从节点无限的进行全量复制导致主从无法正常工作。
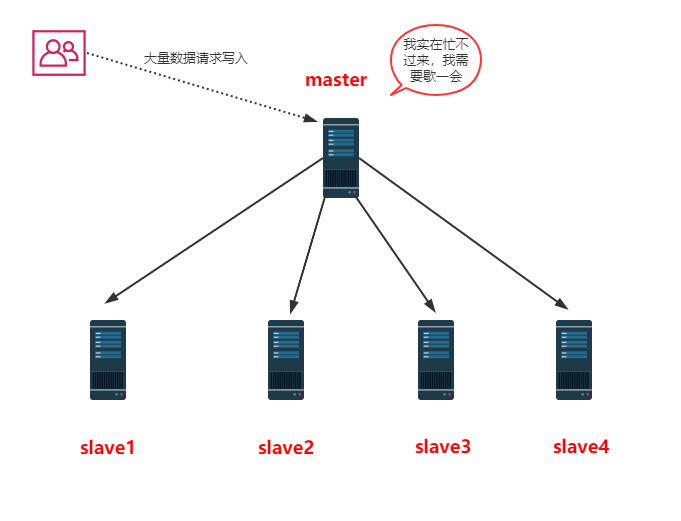
如下图:当有大量请求写入时,不再会单一的向一个主节点发送指令,而会把指令进行分流到各个主节点,达到分担内存、避免大量请求的作用。
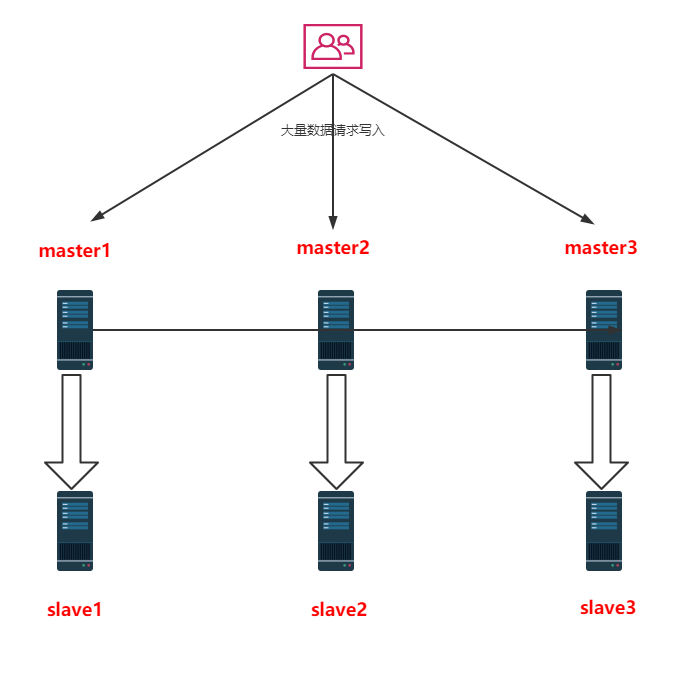
集群作用
分散单机的存储能力,同时也可以很方便的实现扩展。
分流单机的访问请求。
提高系统的可用性。
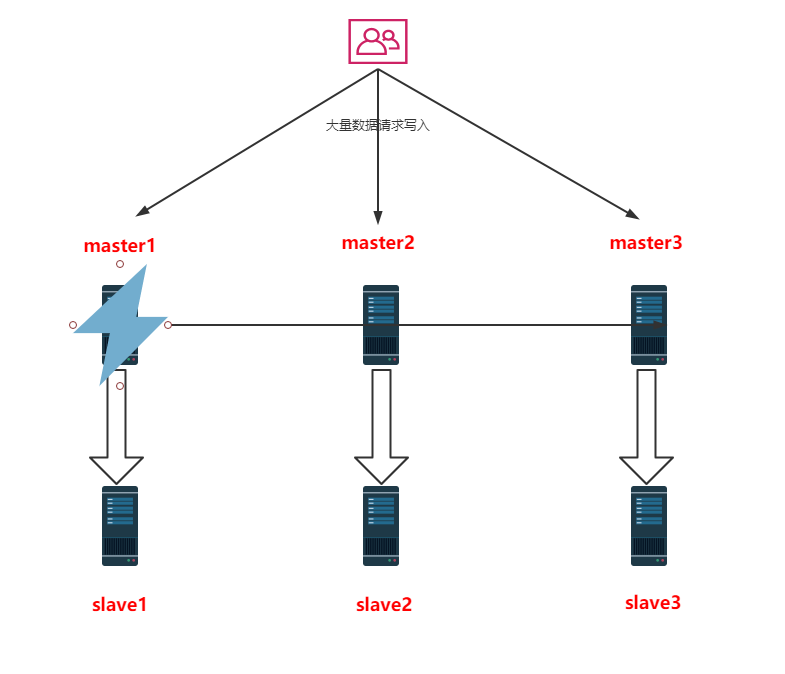
如何理解提高系统的可用性这句话,我们看下图,当 master1 宕机后对系统的影响不会那么大,仍然可以提供正常的服务。
集群存储结构
存储结构
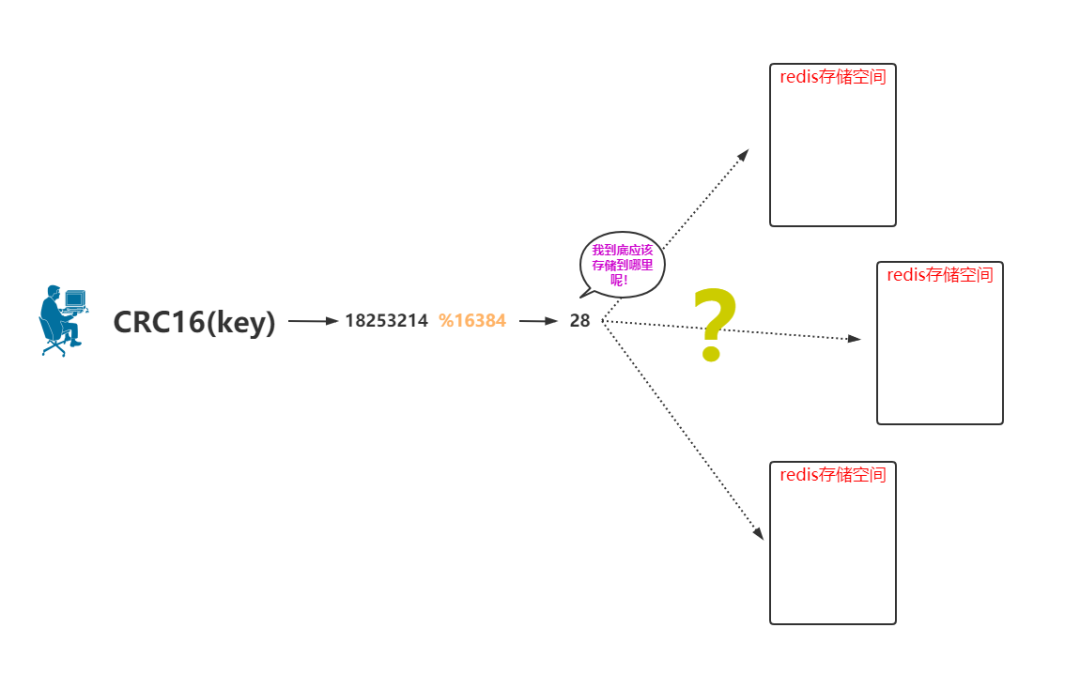
单机的存储是当用户发起请求后直接把 key 存储到自己的内存即可。?
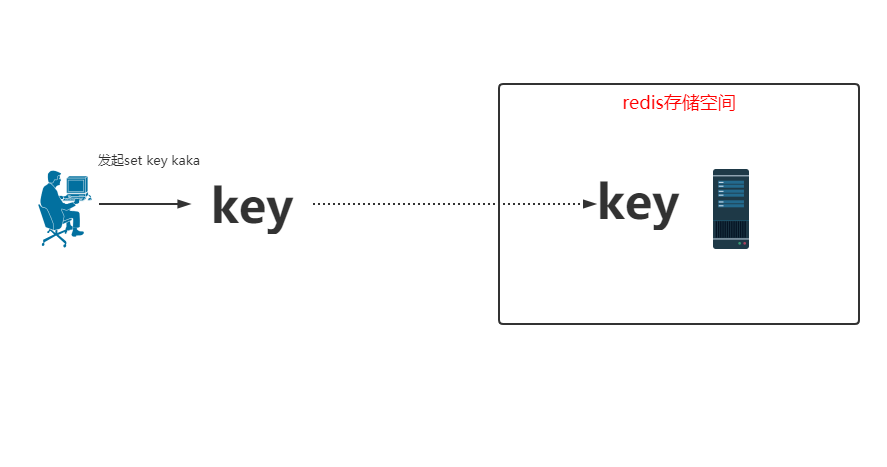
通过 CRC16(key) 会计算出来一个值。
用这个值取模 16384,会得到一个值,我们就先认为是 28。
这个值 28 就是 key 保存的空间位置。
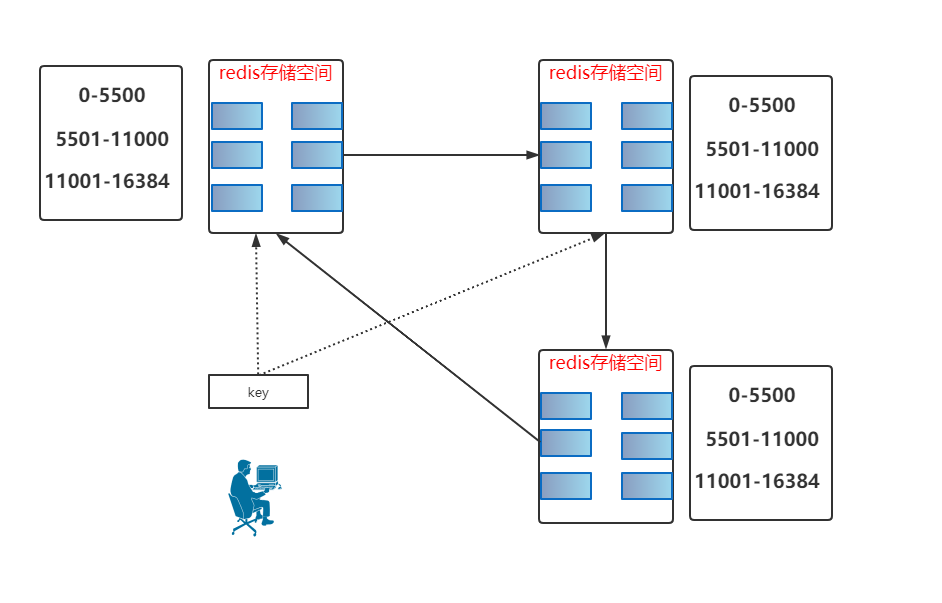
那么现在问题来了,这个 key 到底应该存储在哪个 Redis 存储空间里边呢?
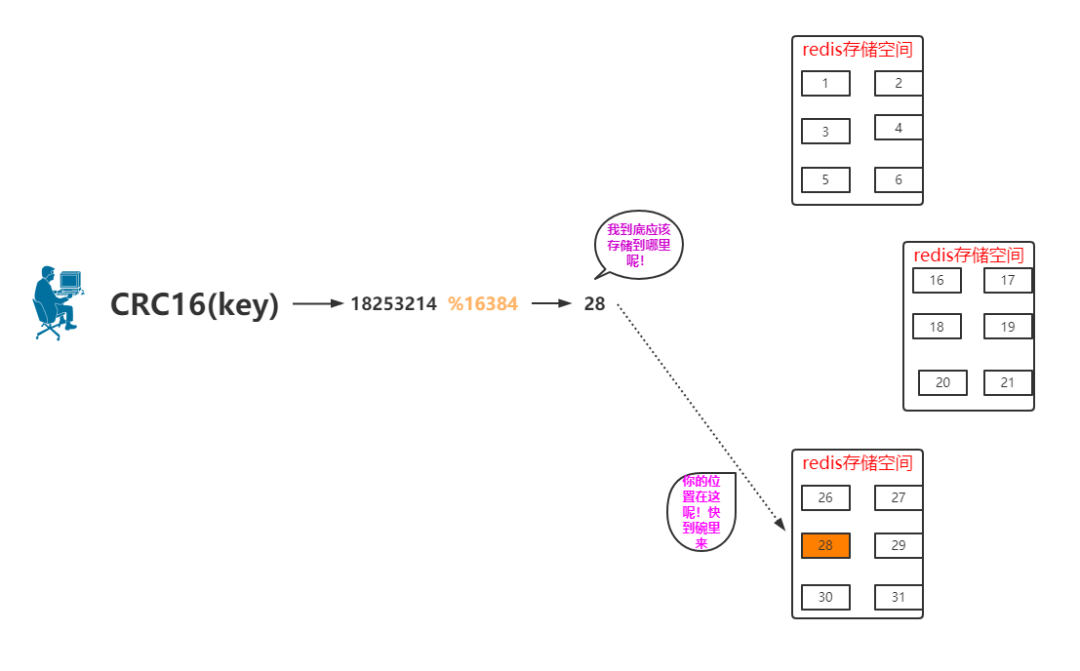
箭头指向的 28 是指的 28 会存储在这个区域里,这个房子有可能会存储 29、30、31 等。
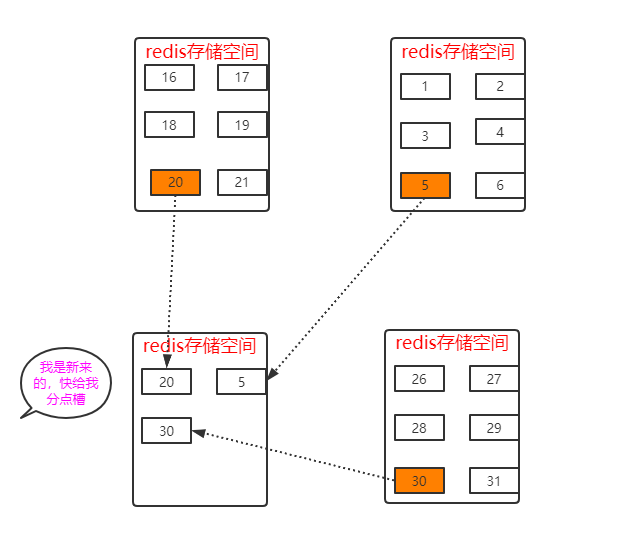
所谓的增节点或去节点就是改变槽所存储的位置不同。
通讯设计
0-5500
5501-11000
11001-16384
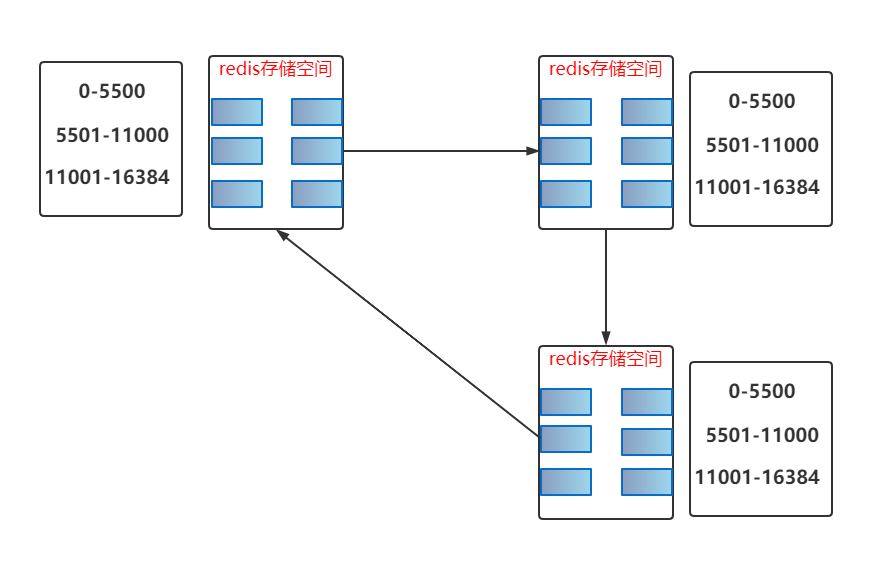
然后重发 key 指令,如下图:
配置集群
①修改配置文件
如下图:
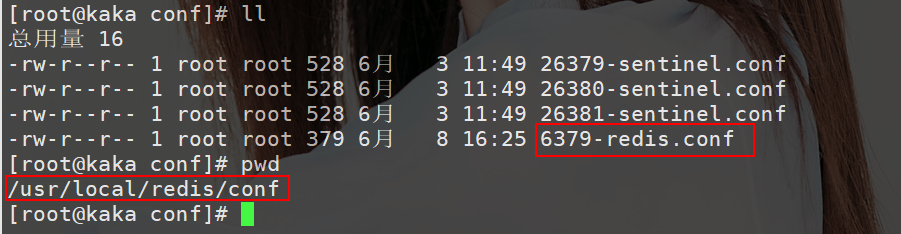
cluster-enabled yes:开启集群模式。
cluster-config-file nodes-6379.conf:集群配置文件。
clustre-node-timeout 10000:节点超时时间,这里为了方便测试设置为 10s。

②构建 6 个节点的配置文件并全启动
给大家提供一个命令可以很方便的替换文件:
sed?'s/6379/6380/g'?6379-redis.conf?>?6380-redis.conf
按照这样的方式创建出来 6 个不同端口的配置文件:

随便打开一个配置文件查看,检测是否替换成功:

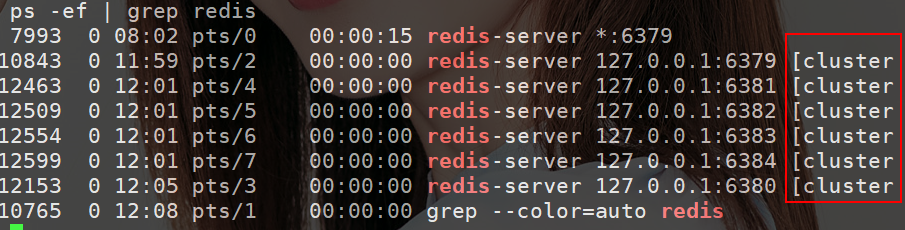
为了查看日志信息方便,全部使用前台启动。并且查看服务是否都正常启动,执行命令:
ps?-ef?|?grep?redis
可以看到启动后多了个 cluster 标识,代表着都是集群的一个节点。
③安装 Ruby
执行命令:
wget?https://cache.ruby-lang.org/pub/ruby/2.7/ruby-2.7.1.tar.gz
解压(根据自己下载的版本来解压):
tar?-xvzf?ruby-2.7.1.tar.gz
安装:
./configure?|?make?|?make?install
这三个指令一气呵成,查看 ruby 和 gem 版本:ruby -v。

④启动集群
如果按照步骤走,这里会出现一个错误,如下图:

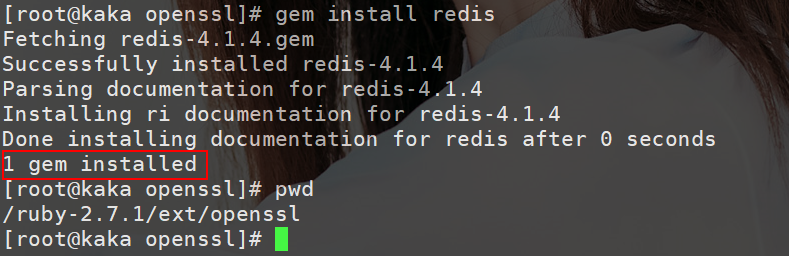
执行 gem install redis,很不幸的是在这里也会出现错误:

然后再执行 gem install redis 就 OK:
./redis-trib.rb?create?--replicas?1?127.0.0.1:6379?127.0.0.1:6380?127.0.0.1:6381?127.0.0.1:6382?127.0.0.1:6383?127.0.0.1:6384

信息解读:创建集群,并且给 6 个节点分配哈希槽,后三个节点配置为前三个节点的从节点。

显示每个节点的哈希槽信息和节点 ID,最后一步需要输入 yes:
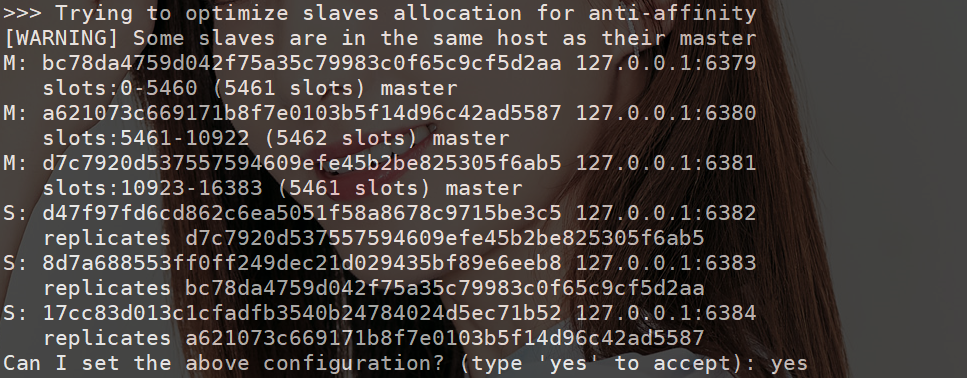
来到 data 目录下查看配置文件的变化。配置文件主要信息是每个主节点分的槽:


查看主机点的运行日志:这里给的主要信息 cluster status changed:ok 集群状态正常。

⑤集群设置与获取数据
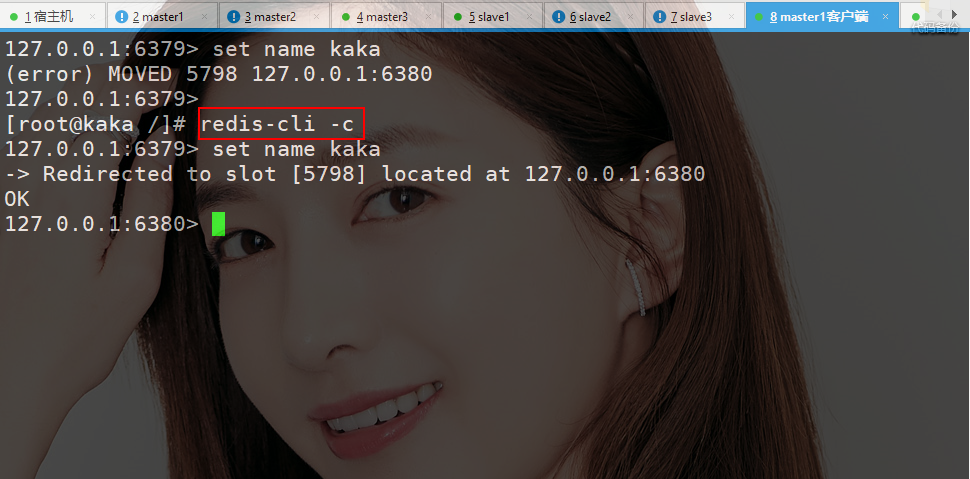
当直接设置数据会报错,并且把 name 这个 key 进行转化后的槽位置为 5798 并且给出了 ip 地址和端口号。?

需要使用命令 redis-cli -c,在进行设置值的时候提示说重定向到 5798 的这个槽。
接下来进行获取数据,会自动的切换节点:

故障转移
①集群从节点下线
总结:从节点下线对集群没有影响。

当端口 6383 上线后,所有的节点会把 fail 的标记清除,如下图:

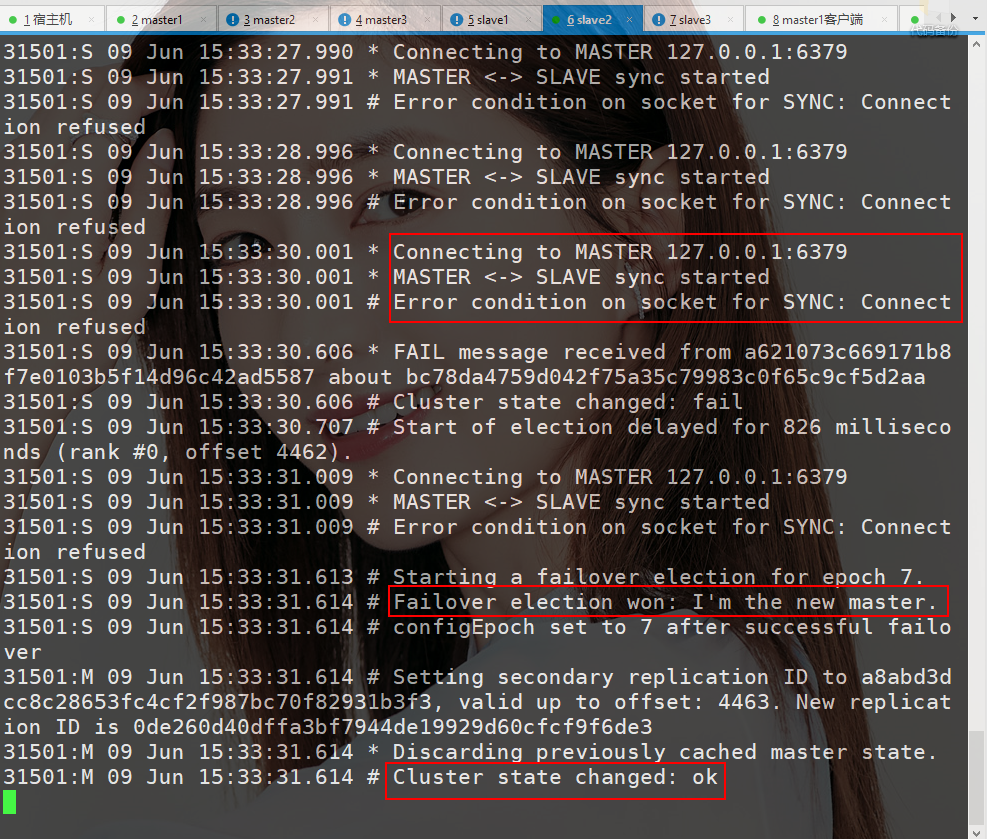
②集群主节点下线
直到时间到期后,开始故障转移。这时 6383 在故障转移选举中胜任,翻身奴隶把歌唱,成为了主节点。
此时在查看一下集群的节点信息,命令 cluster nodes。会发现这里竟然存在四个主节点,但是其中一个主节点时下线状态:
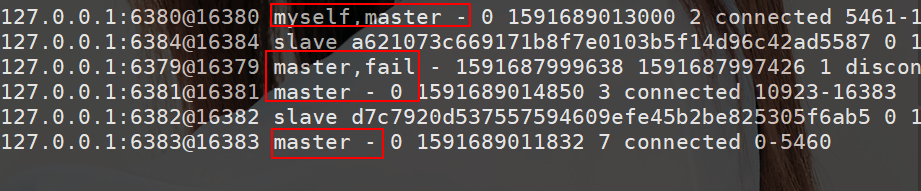
6379 原主节点上线:6379 上线后,同样所有的节点也会清除 fail 信息。并且节点信息也会改变,此时的 6379 改变为 6383 的从节点。

③新增主节点
再新增俩个端口 6385 和 6386:

注意:虽说 6385 已经成为集群中的节点了,但是跟其它节点有区别。它没有数据,也就是没有哈希槽。

最后一步询问是否从所有节点中转移:我使用的是 all。使用指令:cluster nodes 查看,6385 的这个节点就已经拥有三个范围的哈希槽了。

主节点已经新增好了,接下来就需要给 6385 这个主节点配置一个从节点 6386,命令如下:
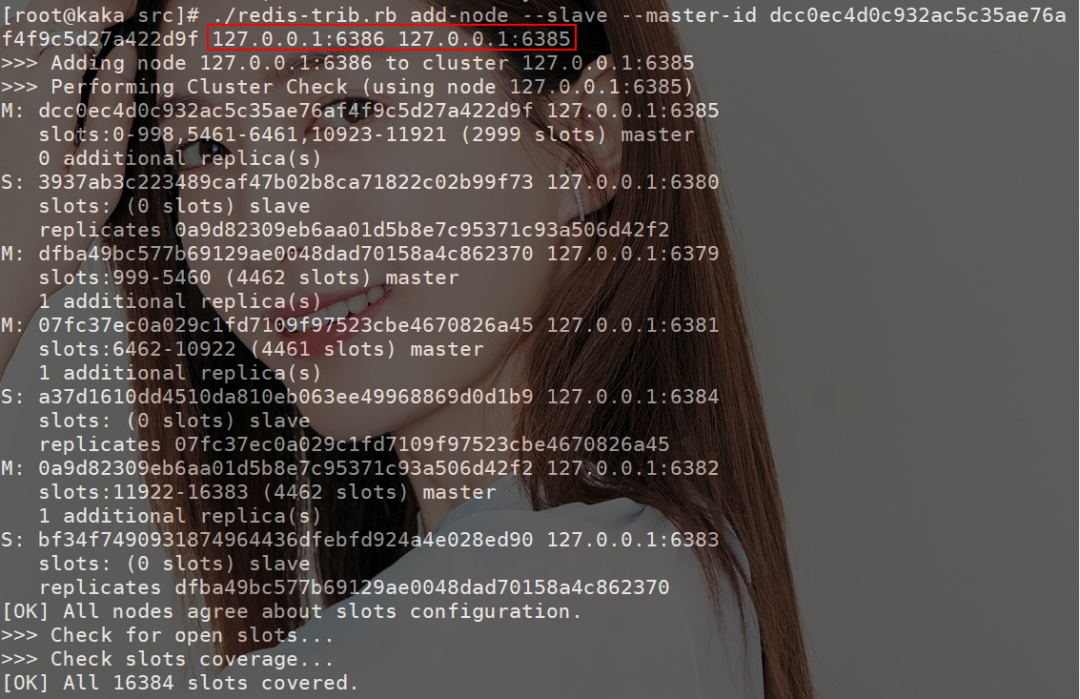
./redis-trib.rb?add-node?--slave?--master-id?dcc0ec4d0c932ac5c35ae76af4f9c5d27a422d9f?127.0.0.1:6386?127.0.0.1:6385
master-id 是 6385 的 id,第一个参数为新节点的 ip+端口,第二个为指定的主节点 ip+端口。
④手动故障迁移
当客户端在旧的 master 上解锁后,重新连接到新的主节点上。?

故障转移原理篇
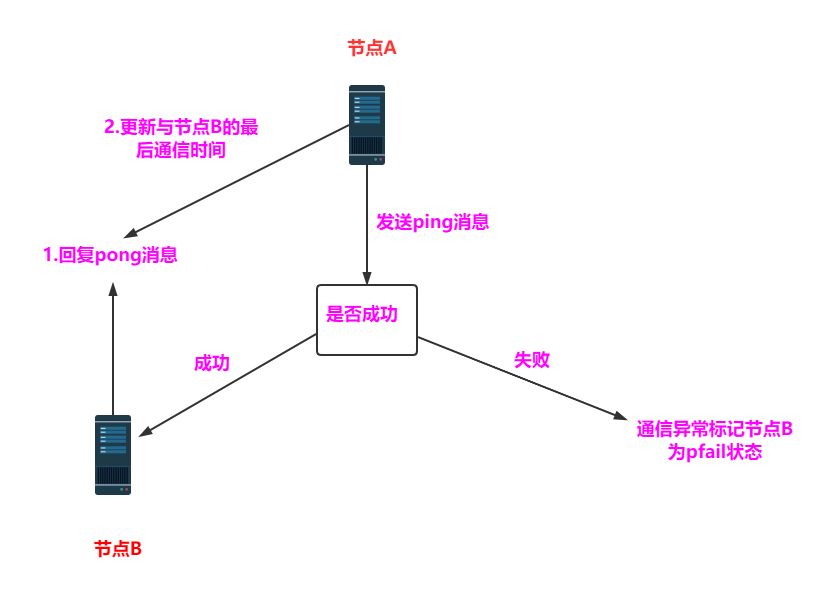
①故障发现到确认
当一个哨兵发现主节点有问题时也会标记主节点客观下线(s_down)。突然发现跑题了,尴尬......
②故障恢复(从节点从此翻身奴隶把歌唱)
福利:你们想要的 SSH 的背景
为了满足大家的要求,我忍痛说一下如何设置亮瞎的背景,我使用的工具是xsheel。
打开工具选择选项?:

接着到查看有个窗口透明就可以设置 xsheel 透明了。?

简介:从业三年,从搬砖一样的生活方式换成了现在有“单”而居的日子。当然这个单不是单身的单!虽然极尽苛刻的技术学习但也远不及客户千奇百怪的要求。进入了朝九晚六,虽然躲过了风吹日晒,但是仍然很享受那些熬得只剩下黑眼圈的日子。坚持学习、坚持写博、坚持分享是咔咔从业以来一直所秉持的信念。希望在诺大互联网中咔咔的文章能带给你一丝丝帮助。
编辑:陶家龙
征稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐:
我为什么用ES做Redis监控,不用Prometheus或Zabbix?
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





![肉肉煲 小姐姐好漂亮[捂嘴笑R] #美丽坏女人 #涞觅ootd- 小红书](https://imgs.knowsafe.com:8087/img/aideep/2026/4/4/6c4ded2b933039c262897f50f42a561d.webp?w=250)
 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675