
我为什么用ES做Redis监控,不用Prometheus或Zabbix?
Redis 当下很流行,也很好用,无论是在业务应用系统,还是在大数据领域都有重要的地位;但 Redis 也很脆弱,用不好,问题多多。

图片来自 Pexels
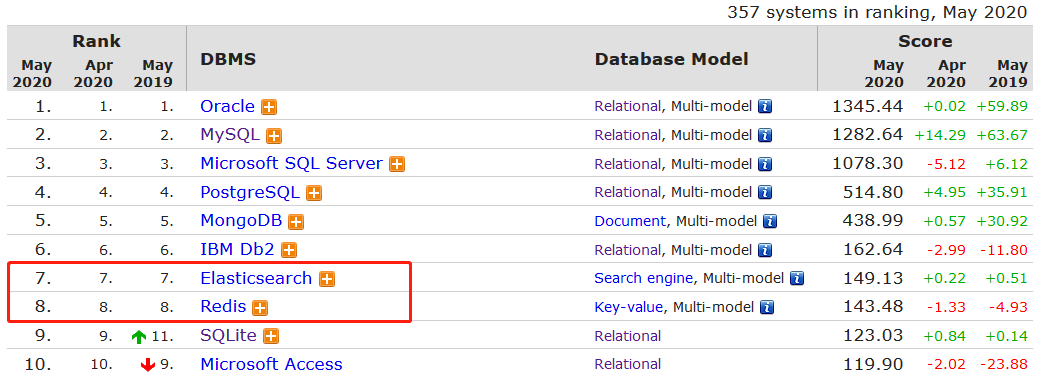
Redis 热度排名
Redis 要想用得好,需要整体掌握三个层面:
开发层面
架构层面
运维层面
Redis 监控体系有哪些方面?
构建 Redis 监控体系我们做了哪些工作?
Redis 监控体系应该细化到什么程度?
为什么使用 ELK 构建监控体系?
需求背景
项目描述
公司业务范围属于车联网行业,有上百万级的真实车主用户,业务项目围绕车主生活服务展开,为了提高系统性能,引入了 Redis 作为缓存中间件。
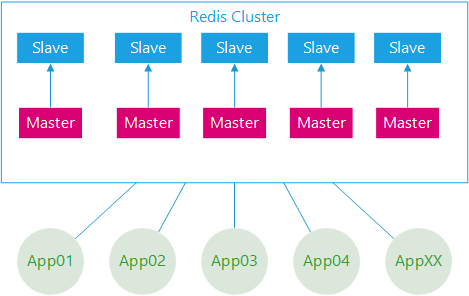
部署架构采用 Redis-Cluster 模式。
后台应用系统有几十个,应用实例数超过二百个。
所有应用系统共用一套缓存集群。
集群节点数几十个,加上容灾备用环境,节点数量翻倍。
集群节点内存配置较高。
问题描述
集群节点崩溃。
集群节点假死。
某些后端应用访问集群响应特别慢。
Redis 集群使用的热度问题?
哪些应用占用的 Redis 内存资源多?
哪些应用占用 Redis 访问数最高?
哪些应用使用 Redis 类型不合理?
应用系统模块使用 Redis 资源分布怎么样?
应用使用 Redis 集群的热点问题?
监控体系
服务端
应用端
服务端与应用端联合分析
服务端
服务端首先是操作系统层面,常用的 CPU、内存、网络 IO,磁盘 IO,服务端运行的进程信息等
Redis 运行进程信息,包括服务端运行信息、客户端连接数、内存消耗、持久化信息 、键值数量、主从同步、命令统计、集群信息等;
Redis 运行日志,日志中会记录一些重要的操作进程,如运行持久化时,可以有效帮助分析崩溃假死的程序。
应用端
联合分析
解决方案
服务端系统
系统指标信息收集配置样例如下:

服务端集群
server:Redis 服务器的一般信息
clients:客户端的连接部分
memory:内存消耗相关信息
persistence:RDB 和 AOF 相关信息
stats:一般统计
replication:主/从复制信息
cpu:统计 CPU 的消耗 command
stats:Redis 命令
统计 cluster:Redis 集群信息
keyspace:数据库的相关统计
Redis 集群的主从关系信息,MetricBeats 表达不出来。
Redis 集群的一些统计信息,永远是累计增加的,如命令数,如果要获取命令数的波峰值,则无法得到;
Redis 集群状态信息变化,MetricBeats 是无法动态的,如集群新增节点、下线节点等。
所以这里参考了 CacheCloud 产品(搜狐团队开源),我们自定义设计开发了 Agent,定时从 Redis 集群采集信息,并在内部做一些统计数值的简单计算,转换成 Json,写入到本地文件,通过 Logstash 采集发送到 Elasticsearch。
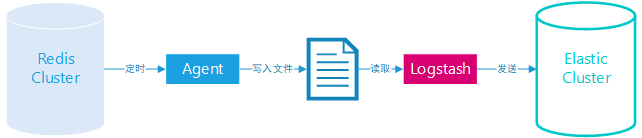
服务端日志
Redis 服务端运行日志采集很简单,直接通过 Elastic-Stack 家族的 Filebeat 产品,其中有 Redis 模块,配置一下 Elastic 服务端,日志文件地址即可。
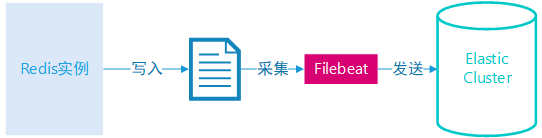
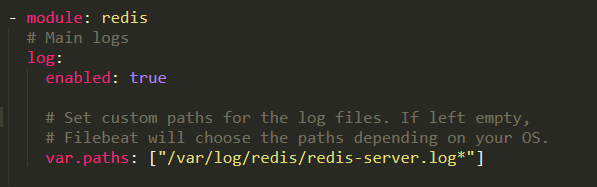
Redis 运行日志采集配置:
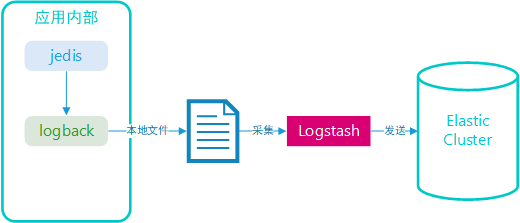
应用端
应用端采集的数据格式如下:
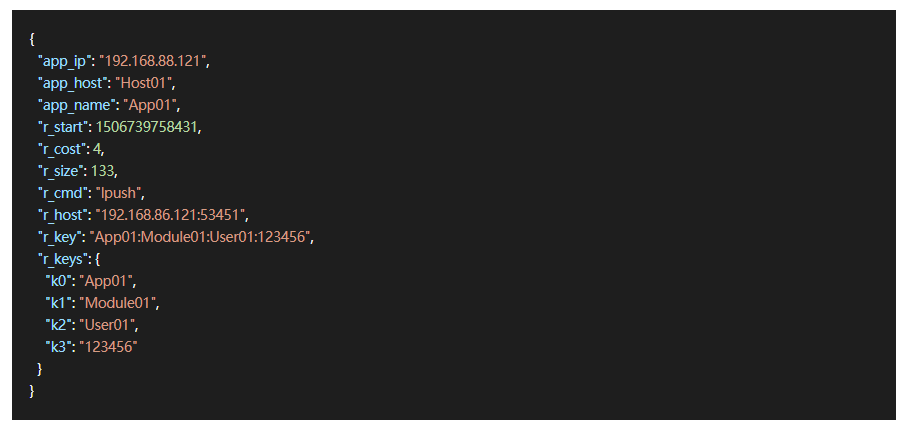
r_host:访问 Redis 集群的服务器地址与端口,其中某一台 ip:port。
r_cmd:执行命令类型、如 get、set、hget、hset 等各种。
r_start:执行命令开始时间。
r_cost:时间消耗。
r_size:获取键值大小或者设置键值大小。
r_key:获取键值名称。
r_keys:键值的二级拆分,数组的长度不限制。这里有必要强调一下,所有应用系统共用的是一套集群,所以应用系统的键值都是有规范的,按照特殊符号分割,如:"应用名称_系统模块_动态变量_xxx“,主要便于我们区分。
类 Connection.java 文件,统计开始,记录命令执行开始时间;统计结束,记录命令结束时间、时间消耗等,并写入到日志流中。
类 JedisClusterCommand 文件,获取键的地方 key,方便之后分析应用键的行为。
在类 Connection.java 文件中有两处:
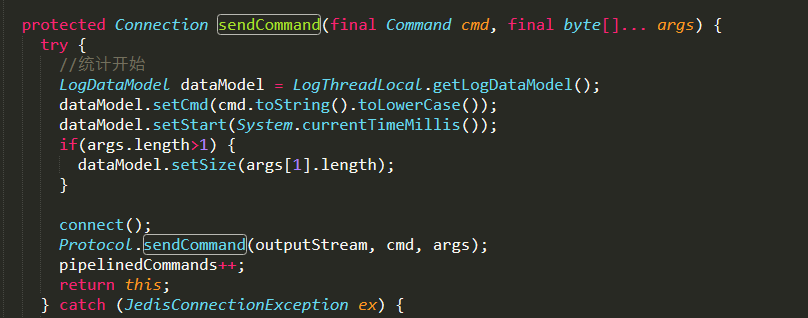
类Connection.java 文件埋点代码的地方

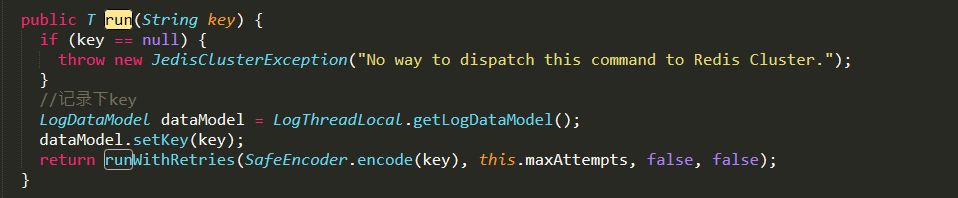
应用端都会使用 Logback 写入日志文件,同时为了更加精准,应用端写入日志时还需要获取应用端的一些信息,如下:
app_ip:应用端部署在服务器上的 IP 地址。
app_host:应用端部署在服务器上的服务器名称。
自定义一个 Layout,自动获取应用端的 IP 地址与服务器名称:


日志分析
Redis 服务端的日志分析比较简单,常规的一些指标而已,创建好关键的图表,容易看出问题。重点讨论应用端的日志分析。

应用端部分键值太大,居然超过 1MB,这种键值访问一次消耗时间很大,会严重造成阻塞。
部分应用居然使用 Redis 当成数据库使用。
有将 List 类型当成消息队列使用,一次存取几十万的数据。
某些应用对于集群的操作频次特别高,几乎占用了一半以上。
还有很多,就不一一描述了。
后续方案
应用端、误用的使用全部要改掉。
服务端,按照应用的数据,进行一些拆分,拆分出一些专用的集群,特定为一些应用使用或者场景。
开发者,后续有新业务模块需要接入 Redis 需要告知架构师们评审。
结语
作者:李猛
简介:数据技术专家,Elastic-Stack 产品深度用户,ES 认证工程师,对 Elastic-Stack 开发、架构、运维有深入体验;实践过多种 ES 项目,最暴力的大数据分析应用,最复杂的业务系统应用。
编辑:陶家龙
出处:转载自微信公众号 DBAplus 社群(ID:dbaplus),本文根据李猛老师在〖deeplus 直播第 220 期〗线上分享演讲内容整理而成。

精彩文章推荐:
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675