
推荐 :决策树VS随机森林--应该使用哪种算法?(附代码&链接)

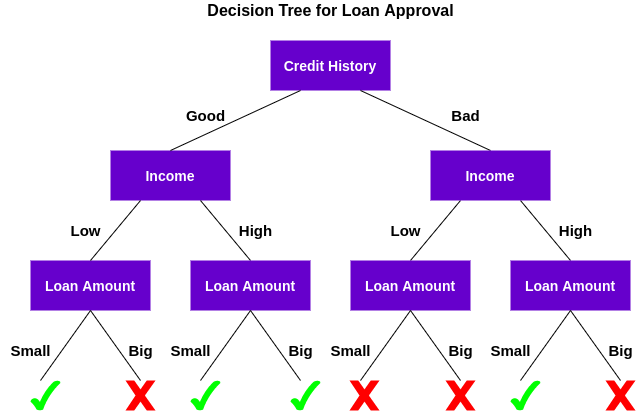
决策树简介
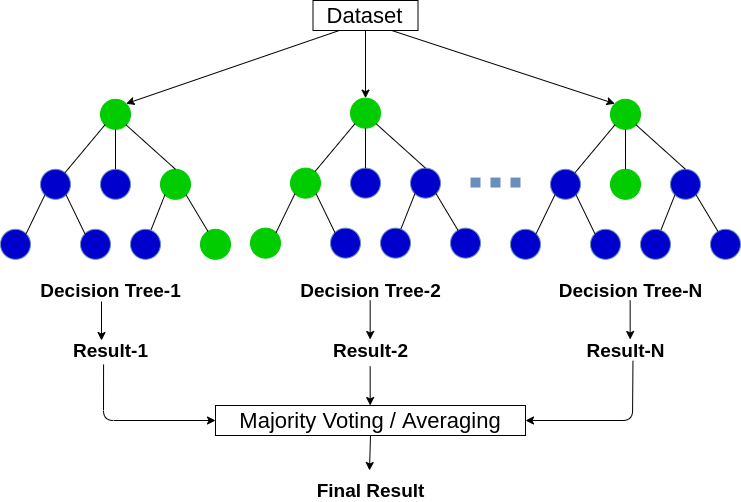
随机森林概览
随机森林和决策树的冲突(代码)
为什么随机森林优于决策树?
决策树vs随机森林——你应该在何时选择何种算法?
基于树的算法:从零开始的完整教程(R & Python)
https://www.analyticsvidhya.com/blog/2016/04/tree-based-algorithms-complete-tutorial-scratch-in-python/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
从决策树开始(免费课程)
https://courses.analyticsvidhya.com/courses/getting-started-with-decision-trees?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
注:本文的想法是比较决策树和随机森林。因此,我不会详细解释基本概念,但是我将提供相关链接以便于你可以进一步探究。

从零开始构建一个随机森林&理解真实世界的数据产品
https://www.analyticsvidhya.com/blog/2018/12/building-a-random-forest-from-scratch-understanding-real-world-data-products-ml-for-programmers-part-3/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
随机森林超参数调优——一个初学者的指南
https://www.analyticsvidhya.com/blog/2020/03/beginners-guide-random-forest-hyperparameter-tuning/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
集成学习的综合指南(使用Python代码)
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-for-ensemble-models/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
如何在机器学习中建立集成模型?( R代码)
注:你可以去DataHack(https://datahack.analyticsvidhya.com/contest/all/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm?)平台并在不同在线机器学习竞赛中与他人竞争,并且有机会获得令人兴奋的奖品。

https://www.analyticsvidhya.com/blog/2016/07/practical-guide-data-preprocessing-python-scikit-learn/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
# Data Preprocessing and null values imputation# Label Encodingdf['Gender']=df['Gender'].map({'Male':1,'Female':0})df['Married']=df['Married'].map({'Yes':1,'No':0})df['Education']=df['Education'].map({'Graduate':1,'Not Graduate':0})df['Dependents'].replace('3+',3,inplace=True)df['Self_Employed']=df['Self_Employed'].map({'Yes':1,'No':0})df['Property_Area']=df['Property_Area'].map({'Semiurban':1,'Urban':2,'Rural':3})df['Loan_Status']=df['Loan_Status'].map({'Y':1,'N':0})#Null Value Imputationrev_null=['Gender','Married','Dependents','Self_Employed','Credit_History','LoanAmount','Loan_Amount_Term']df[rev_null]=df[rev_null].replace({np.nan:df['Gender'].mode(),np.nan:df['Married'].mode(),np.nan:df['Dependents'].mode(),np.nan:df['Self_Employed'].mode(),np.nan:df['Credit_History'].mode(),np.nan:df['LoanAmount'].mean(),np.nan:df['Loan_Amount_Term'].mean()})rfc_vs_dt-2.py hosted with ? by GitHub

第三步:创造训练集和测试集
现在,让我们以80:20的比例进行训练集和测试集的划分:
X=df.drop(columns=['Loan_ID','Loan_Status']).valuesY=df['Loan_Status'].valuesX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 42)rfc_vs_dt-3.py hosted with ? by GitHub
让我们一眼所划分的训练集和测试集:
print('Shape of X_train=>',X_train.shape)print('Shape of X_test=>',X_test.shape)print('Shape of Y_train=>',Y_train.shape)print('Shape of Y_test=>',Y_test.shape)rfc_vs_dt-4.py hosted with ? by GitHub

#?Building?Decision?Treefrom sklearn.tree import DecisionTreeClassifierdt = DecisionTreeClassifier(criterion = 'entropy', random_state = 42)dt.fit(X_train, Y_train)dt_pred_train = dt.predict(X_train)rfc_vs_dt-5.py hosted with ? by GitHub
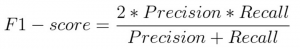
https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm

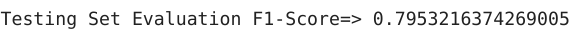
# Evaluation on Training setdt_pred_train = dt.predict(X_train)print('Training Set Evaluation F1-Score=>',f1_score(Y_train,dt_pred_train))rfc_vs_dt-6.py hosted with ? by GitHub# Evaluating on Test setdt_pred_test = dt.predict(X_test)print('Testing Set Evaluation F1-Score=>',f1_score(Y_test,dt_pred_test))rfc_vs_dt-7.py hosted with ? by GitHub

?#?Building??Random?Forest?Classifierfrom sklearn.ensemble import RandomForestClassifierrfc = RandomForestClassifier(criterion = 'entropy', random_state = 42)rfc.fit(X_train,?Y_train)# Evaluating on Training setrfc_pred_train = rfc.predict(X_train)print('Training Set Evaluation F1-Score=>',f1_score(Y_train,rfc_pred_train))rfc_vs_dt-8.py hosted with ? by GitHubf1 score random forest# Evaluating on Test setrfc_pred_test = rfc.predict(X_test)print('Testing Set Evaluation F1-Score=>',f1_score(Y_test,rfc_pred_test))rfc_vs_dt-9.py hosted with ? by GitHub
feature_importance=pd.DataFrame({'rfc':rfc.feature_importances_,'dt':dt.feature_importances_},index=df.drop(columns=['Loan_ID','Loan_Status']).columns)feature_importance.sort_values(by='rfc',ascending=True,inplace=True)index = np.arange(len(feature_importance))fig, ax = plt.subplots(figsize=(18,8))rfc_feature=ax.barh(index,feature_importance['rfc'],0.4,color='purple',label='Random Forest')dt_feature=ax.barh(index+0.4,feature_importance['dt'],0.4,color='lightgreen',label='Decision Tree')ax.set(yticks=index+0.4,yticklabels=feature_importance.index)ax.legend()plt.show()rfc_vs_dt-10.py hosted with ? by GitHub

https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html#sklearn.ensemble.BaggingClassifier?
https://www.analyticsvidhya.com/blog/2019/08/decoding-black-box-step-by-step-guide-interpretable-machine-learning-models-python/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm
本文转自:数据派THU ;获授权;
END
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

![修老虎 在吗,来一点周末甜妹er,喜欢的扣1,不喜欢的说出10条理由[拳头]](https://imgs.knowsafe.com:8087/img/aideep/2021/10/11/327421afe2a83be9dbbff9db53422873.jpg?w=250)




 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675