
5年Python功力,总结了10个开发技巧



如何在运行状态查看源代码?
#?demo.py
import?inspect
def?add(x,?y):
????return?x?+?y
print("===================")
print(inspect.getsource(add))
$?python?demo.py
===================
def?add(x,?y):
????return?x?+?y

如何关闭异常自动关联上下文?
try:
????print(1?/?0)
except?Exception?as?exc:
????raise?RuntimeError("Something?bad?happened")
Traceback?(most?recent?call?last):
??File?"demo.py",?line?2,?in?<module>
????print(1?/?0)
ZeroDivisionError:?division?by?zero
During?handling?of?the?above?exception,?another?exception?occurred:
Traceback?(most?recent?call?last):
??File?"demo.py",?line?4,?in?<module>
????raise?RuntimeError("Something?bad?happened")
RuntimeError:?Something?bad?happened
__context__属性。这就是 Python 默认开启的自动关联异常上下文。from?语法会有个限制,就是第二个表达式必须是另一个异常类或实例。),来表明你的新异常是直接由哪个异常引起的。try:
????print(1?/?0)
except?Exception?as?exc:
????raise?RuntimeError("Something?bad?happened")?from?exc
Traceback?(most?recent?call?last):
??File?"demo.py",?line?2,?in?<module>
????print(1?/?0)
ZeroDivisionError:?division?by?zero
The?above?exception?was?the?direct?cause?of?the?following?exception:
Traceback?(most?recent?call?last):
??File?"demo.py",?line?4,?in?<module>
????raise?RuntimeError("Something?bad?happened")?from?exc
RuntimeError:?Something?bad?happened
with_traceback()方法为异常设置上下文__context__属性,这也能在traceback更好的显示异常信息。try:
????print(1?/?0)
except?Exception?as?exc:
????raise?RuntimeError("bad?thing").with_traceback(exc)
raise...from None,从下面的例子上看,已经没有了原始异常$?cat?demo.py
try:
????print(1?/?0)
except?Exception?as?exc:
????raise?RuntimeError("Something?bad?happened")?from?None
$
$?python?demo.py
Traceback?(most?recent?call?last):
??File?"demo.py",?line?4,?in?<module>
????raise?RuntimeError("Something?bad?happened")?from?None
RuntimeError:?Something?bad?happened
(PythonCodingTime)

最快查看包搜索路径的方式
>>>?import?sys
>>>?from?pprint?import?pprint???
>>>?pprint(sys.path)
['',
?'/usr/local/Python3.7/lib/python37.zip',
?'/usr/local/Python3.7/lib/python3.7',
?'/usr/local/Python3.7/lib/python3.7/lib-dynload',
?'/home/wangbm/.local/lib/python3.7/site-packages',
?'/usr/local/Python3.7/lib/python3.7/site-packages']
>>>?
[wangbm@localhost?~]$?python?-c?"print('\n'.join(__import__('sys').path))"
/usr/lib/python2.7/site-packages/pip-18.1-py2.7.egg
/usr/lib/python2.7/site-packages/redis-3.0.1-py2.7.egg
/usr/lib64/python27.zip
/usr/lib64/python2.7
/usr/lib64/python2.7/plat-linux2
/usr/lib64/python2.7/lib-tk
/usr/lib64/python2.7/lib-old
/usr/lib64/python2.7/lib-dynload
/home/wangbm/.local/lib/python2.7/site-packages
/usr/lib64/python2.7/site-packages
/usr/lib64/python2.7/site-packages/gtk-2.0
/usr/lib/python2.7/site-packages
[wangbm@localhost?~]$?python3?-m?site
sys.path?=?[
????'/home/wangbm',
????'/usr/local/Python3.7/lib/python37.zip',
????'/usr/local/Python3.7/lib/python3.7',
????'/usr/local/Python3.7/lib/python3.7/lib-dynload',
????'/home/wangbm/.local/lib/python3.7/site-packages',
????'/usr/local/Python3.7/lib/python3.7/site-packages',
]
USER_BASE:?'/home/wangbm/.local'?(exists)
USER_SITE:?'/home/wangbm/.local/lib/python3.7/site-packages'?(exists)
ENABLE_USER_SITE:?True

将嵌套 for 循环写成单行
list1?=?range(1,3)
list2?=?range(4,6)
list3?=?range(7,9)
for?item1?in?list1:
????for?item2?in?list2:
???????for?item3?in?list3:
???????????print(item1+item2+item3)
from?itertools?import?product
list1?=?range(1,3)
list2?=?range(4,6)
list3?=?range(7,9)
for?item1,item2,item3?in?product(list1,?list2,?list3):
????print(item1+item2+item3)
$?python?demo.py
12
13
13
14
13
14
14
15

如何使用 print 输出日志
>>>?with?open('test.log',?mode='w')?as?f:
...?????print('hello,?python',?file=f,?flush=True)
>>>?exit()
$?cat?test.log
hello,?python

如何快速计算函数运行时间
import?time
start?=?time.time()
#?run?the?function
end?=?time.time()
print(end-start)
import?time
import?timeit
def?run_sleep(second):
????print(second)
????time.sleep(second)
#?只用这一行
print(timeit.timeit(lambda?:run_sleep(2),?number=5))
2
2
2
2
2
10.020059824

利用自带的缓存机制提高效率
@functools.lru_cache(maxsize=None,?typed=False)
maxsize:最多可以缓存多少个此函数的调用结果,如果为None,则无限制,设置为 2 的幂时,性能最佳 typed:若为 True,则不同参数类型的调用将分别缓存。
from?functools?import?lru_cache
@lru_cache(None)
def?add(x,?y):
????print("calculating:?%s?+?%s"?%?(x,?y))
????return?x?+?y
print(add(1,?2))
print(add(1,?2))
print(add(2,?3))
calculating:?1?+?2
3
3
calculating:?2?+?3
5
def?fib(n):
????if?n?<?2:
????????return?n
????return?fib(n?-?2)?+?fib(n?-?1)
import?timeit
def?fib(n):
????if?n?<?2:
????????return?n
????return?fib(n?-?2)?+?fib(n?-?1)
print(timeit.timeit(lambda?:fib(40),?number=1))
#?output:?31.2725698948
import?timeit
from?functools?import?lru_cache
@lru_cache(None)
def?fib(n):
????if?n?<?2:
????????return?n
????return?fib(n?-?2)?+?fib(n?-?1)
print(timeit.timeit(lambda?:fib(500),?number=1))
#?output:?0.0004921059880871326

在程序退出前执行代码的技巧
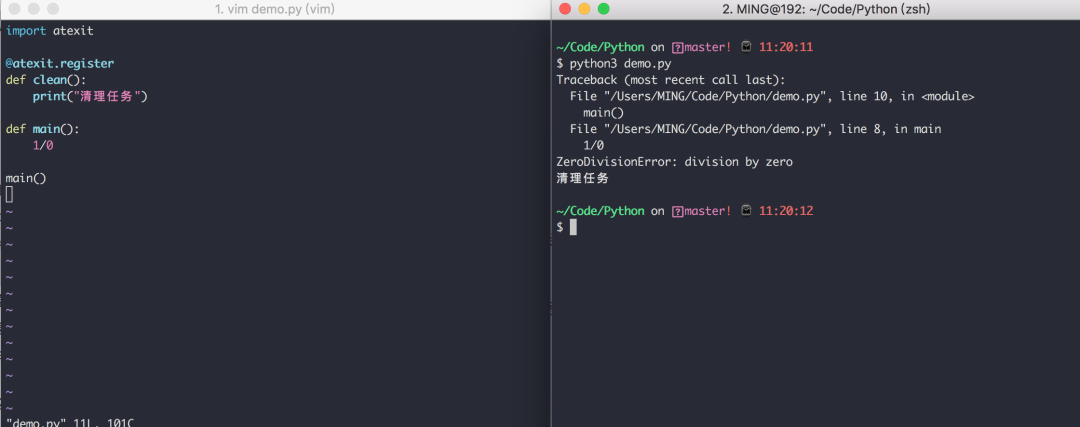
clean()函数有参数,那么你可以不用装饰器,而是直接调用atexit.register(clean_1, 参数1, 参数2, 参数3='xxx')。如果程序是被你没有处理过的系统信号杀死的,那么注册的函数无法正常执行。 如果发生了严重的 Python 内部错误,你注册的函数无法正常执行。 如果你手动调用了 os._exit(),你注册的函数无法正常执行。

实现类似 defer 的延迟调用
import?"fmt"
func?myfunc()?{
????fmt.Println("B")
}
func?main()?{
????defer?myfunc()
????fmt.Println("A")
}
A
B
import?contextlib
def?callback():
????print('B')
with?contextlib.ExitStack()?as?stack:
????stack.callback(callback)
????print('A')
A
B

如何流式读取数G超大文件
#?一次性读取
with?open("big_file.txt",?"r")?as?fp:
????content?=?fp.read()
def?read_from_file(filename):
????with?open(filename,?"r")?as?fp:
????????yield?fp.readline()
def?read_from_file(filename,?block_size?=?1024?*?8):
????with?open(filename,?"r")?as?fp:
????????while?True:
????????????chunk?=?fp.read(block_size)
????????????if?not?chunk:
????????????????break
????????????yield?chunk
from?functools?import?partial
def?read_from_file(filename,?block_size?=?1024?*?8):
????with?open(filename,?"r")?as?fp:
????????for?chunk?in?iter(partial(fp.read,?block_size),?""):
????????????yield?chunk
推荐阅读
?全网唯一秃头数据集:20万张人像,网罗各类秃头
你点的每个“在看”,我都认真当成了AI

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675