

三星的SARC(三星奥斯汀研发中心)CPU开发团队发表了一篇题为“三星Exynos CPU架构的演变”的论文,介绍了该团队在其8年的发展过程中所做的努力,及其定制Arm的一些关键特征。此外,报告中首次披露M6 CPU内核设计。
在ISCA(国际计算机体系结构研讨会)会议中,三星的SARC(三星奥斯汀研发中心)CPU开发团队发表了一篇题为“三星Exynos CPU架构的演变”的论文,详细介绍了该团队在其8年的发展过程中所做的努力,并介绍了其定制Arm的一些关键特征。CPU内核范围从Exynos M1到最新的Exynos M5 CPU以及未发布的M6设计。作为背景,三星的SARC CPU团队成立于2011年,以开发定制的CPU内核,然后三星LSI将其部署到其Exynos SoC中,从2015年在Galaxy S7中发布的第一代Exynos 8890开始一直最新的用于Galaxy S20的M5内核Exynos 990。目前,SARC已完成M6微体系结构,SARC在2019年10月传出CPU团队解散的消息之前,就已经完成了M6微架构。在ISCA的论文中三星将开发团队的一些被认为值得保留的想法公布在公众面前,基本上反应了8年来的开发历程。本文提供了三星定制CPU内核之间的微体系结构差异的总体概览表:
披露内容涵盖了设计的一些众所周知的特征,如三星在HotChips 2016的最初M1 CPU微体系结构的深挖以及在HotChips 2018的最新M3所披露的那样。它使我们可以洞悉我们在S10和S20评测中测得的新M4和M5微体系结构,并让我们对未来的M6有了初步的了解。三星设计的一个关键特征是多年来,他们都是基于2011年开发的M1内核蓝图RTL为基础,多年来不断改进内核的功能模块。但到了M3,内核的设计发生了很大的变化。他们从几个方面大幅扩展了内核,例如从4宽设计到6宽中核。三星设计的主要特征是多年来,它基于2011年以M1内核开始的RTL为基础,并且多年来不断改进内核的功能模块。到M3的设计发生了很大的变化,从几个方面大幅扩展了内核,例如从4-wide设计到6-wide中核。之前尚未公开的新披露内容将涉及新的M5和M6内核。对于M5,三星对内核的缓存层进行了较大的更改,例如用新的更大的共享缓存替换了私有L2缓存,以及公开了L3结构从3组设计到2组的变化。具有较少延迟的Bank设计。就微体系结构而言,正在开发中的尚未发布的M6内核似乎是一个更大的飞跃。SARC团队在这里进行了较大的改进,例如将L1指令和数据缓存从64KB增加到128KB,这是目前苹果的CPU核心从A12开始才实现的设计选择。据说L2的带宽能力提高了一倍,最高可达64B /周期,L3的带宽也将从3MB增加到4MB。M6可能是8-wide解码核心,据我们所知,这将是我们所知道的最宽的商业微体系结构-至少在解码方面。有趣的是,即使内核要宽得多,整数执行单元也不会做太多改变,只是看到一个复杂的管道增加了第二个整数除法能力,而加载/存储管道将保持与上一个相同。具有1个加载单元,1个存储单元和1个1加载/存储单元的M5。在浮点/ SIMD 流水线上,我们将看到具有FMAC功能的第四个单元。TLB可能会发生一些大变化,例如L1 DTLB从48页增加到128页,而主TLB从4K页增加到8K页(32MB覆盖)。自M3以来,M6也是第一次,将增加内核的无序窗口,并使用更大的整数和浮点物理寄存器文件,以及从以下时间开始增加ROB(重排序缓冲区):228至256。SARC内核的一个主要弱点似乎仍然存在于M5和即将推出的M6内核中,这是其更深层次的流水线阶段导致相对昂贵的16周期错误预测损失的结果,远高于Arm的最新设计(11级)周期。这篇论文更深入地介绍了分支预测器设计,展示了基于核的可缩放哈希感知器设计。这些年来,设计一直在不断改进,提高了分支的准确性,从而不断降低了MPKI(mis-predictsper kilo-instructions)。如下的一个有趣的表格显示的是分支预测器在前端所占用的存储结构数量,单位为Kbytes: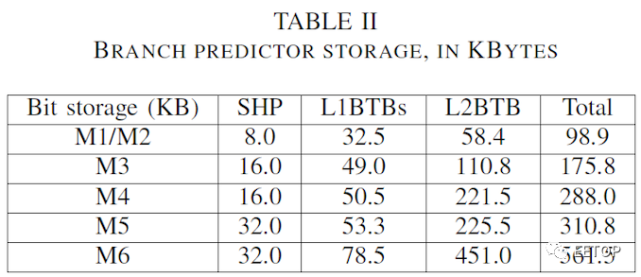
本文进一步详细介绍了内核的预取方法,包括M5代的μOP缓存的引入,以及团队对内核的安全漏洞(如Spectre)的抵御。本文进一步描述了SARC团队为改善各代产品的内存延迟所做的努力。在M4核心中,团队采用了负载-负载级联机制,将后续负载的有效L1周期延迟从4个周期减少到3个周期。M4还引入了带有新接口的路径旁路,从CPU核心直接到内存控制器,避免了通过互连的流量,这解释了我们在Exynos 9820中看到的更大的延迟改进。M5引入了推测性高速缓存查找旁路,同时向互连和高速缓存标签发出了一个请求,这可能节省了高速缓存未命中的等待时间,因为内存请求已经在进行中。通过数代迭代发展,平均负载延迟不断得到改善,从M1上的14.9个周期下降到M6上的8.3个周期。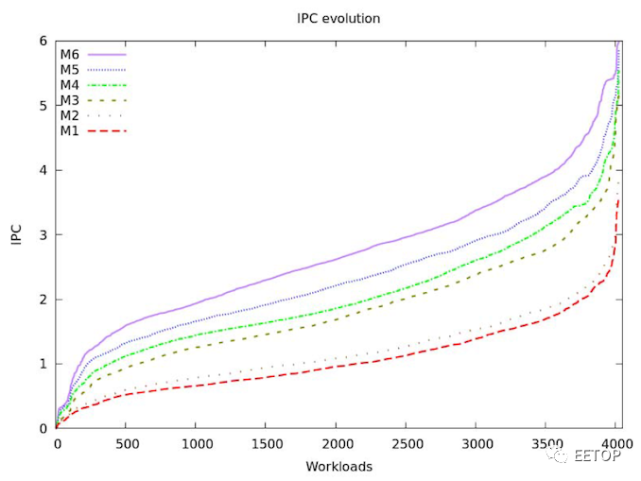
在IPC改进方面,SARC团队在过去的8年中已设法平均每年获得20%的改进。如图所示,M3特别是IPC的一大飞跃。M5与我们在基准测试中看到的大致相关,大约提高了15-17%。据披露,M6的IPC平均值为2.71,而M1的平均值为1.06,此处的图表通常似乎表明与M5相比提高了20%。在会议的问答环节中,论文的主持人布莱恩·格雷森(Brian Grayson)回答了有关自研架构计划取消的问题。团队在每一代产品的性能和效率改进方面一直都是按计划进行的。据说,团队最大的困难是对未来的设计变更非常小心,因为团队永远没有资源完全从头开始或完全重写代码块。事后看来,团队在过去会对一些设计方向做出不同的选择。这种串行化的设计方法与Arm的定位形成了鲜明的对比,Arm有多个跃迁设计中心和CPU团队,让他们可以做一些类似于Cortex-A76这样的接地气的重新设计的事情。对于即将到来的M7等核心,团队有很多改进的想法,但据说取消该计划的决定来自于三星的高层。与Arm的设计相比,SARC的CPU核心从来就没有那么强的竞争力,在功耗效率、性能和面积使用方面都有所下降。由于Arm上周发布了最新的Cortex-X1以获得全面的性能,因此在我看来SARC的M6设计可能会遇到与之竞争的问题。

点击在看,即刻变好看

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/








 腾讯数码
腾讯数码
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




