
superscan之被动扫描
前言
阅读本文大约需要<20>分钟,建议饭后阅读
本文是superscan被动扫描实现过程分享,对于漏扫技术不做深入讨论,抛砖引玉,交流提升
superscan采用k8s+openfaas作为底层基础设施,本文也描述了单机docker环境的实现方法以适应大多数读者
本文内容涉及到Elasticsearch DSL、 HTTP、 DNS、k8s、faas等基础知识, 参考文档见文章末尾的
参考引用。talk is cheap, show me the code
关于superscan
??????? superscan 是宜信安全部研发的集空间测绘、威胁发现于一体的综合性威胁监控平台。不仅关注传统威胁,更加关注来自网络空间,各个角度全方位的威胁。目前已经实现了域名、主机、服务、CMS、组件、webserver六类数据的24小时监控;实现了包含主机、网站、组件、源代码、信息泄漏、假冒、舆情7类威胁发现。本文介绍的被动扫描属于威胁发现里的网站威胁部分,除了被动扫描,superscan也支持主动扫描的方式来检测网站安全。
关于被动扫描
????????被动扫描的概念是相对于主动扫描的。主动扫描的URL、参数来源是通过爬虫遍历网站结构得到的,被动扫描则省略了这个步骤。被动扫描通过浏览器代理、MITM代理、流量等获取URL、参数。获取到URL、参数之后的扫描过程主动、被动扫描并什么大差异。相对于主动扫描,被动扫描来自于实际的用户请求,能够获取到更真实的网站参数,避免主动扫描爬虫的缺陷。本文中的被动扫描请求参数是来自于自研的流沙平台。
??????? PS:我们不生产流量,我们只是流量的搬运工。
思路 & 设计
数据流图
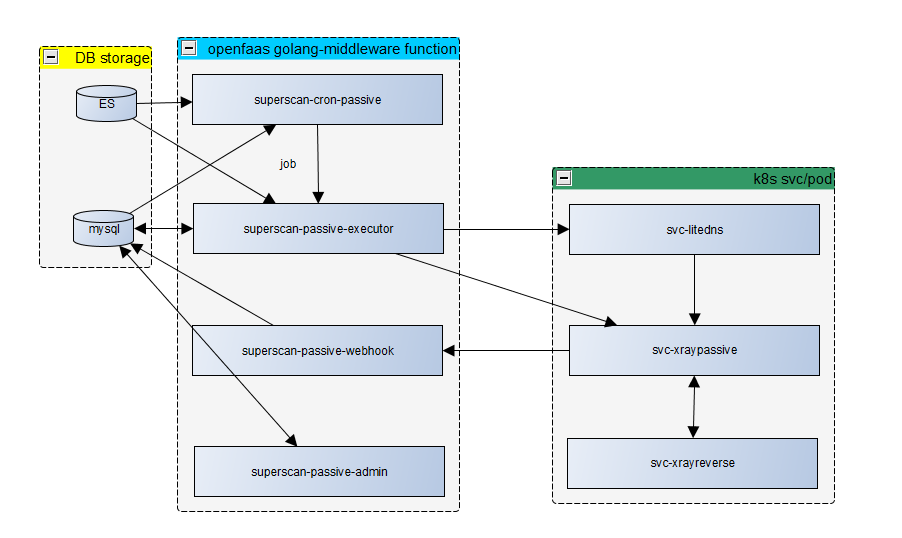
下文中每个功能模块用[<module name>]表示
[superscan-cron-passive]
周期性运行,发现新增域名,根据网站配置创建executor任务,相当于任务的起始入口
输入: 从MYSQL中加载配置,从ES中获取新增域名;
输出: 将新增域名保存到MYSQL中,根据域名配置创建executor任务
[superscan-passive-executor]
输入: 接收superscan-cron-passive发送来的任务, 从mysql中加载配置,根据任务和配置拉取ES中的请求数据
输出: 配置litedns
[superscan-passive-admin]
UI后端接口
读取网站域名信息
配置扫描参数
[superscan-passive-webhook]
IN: 接收xraypassive检出的漏洞
输出: 将接收到的漏洞信息写入MYSQL
[svc-xraypassive]
IN: xray工作在代理模式(listen), 捕获流量并进行扫描。
输出: 将扫描结果通过http发送给 superscan-passive-webhook
[svc-xrayreverse]
xray反连(reverse)服务
输入输出为xray盲打服务之间通信
[svc-litedns]
面向svc-xraypassive提供DNS解析服务
输入: 解析配置,解析请求
输出: 解析结果
[其他]
????????litedns后端使用redis作为解析持久化的缓存,属于litedns内部实现,故在上图中略去不表
superscan-passive-executor 在URL处理和去重时使用了redis缓存来减少对mysql的压力,属于编程技巧,也略去不表
superscan-passive-admin 实现了被动扫描管理的后端接口,可以通过k8s ingress或者node port的方式实现接口暴露。
[数据模式设计]
数据库:
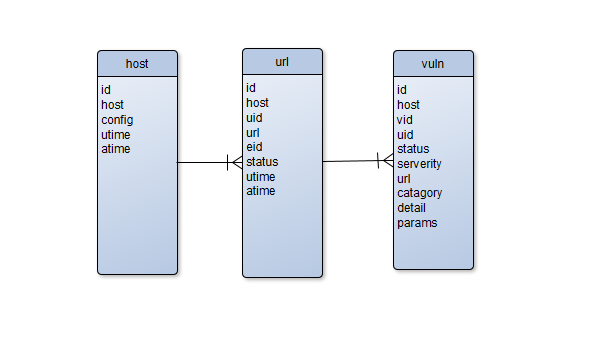
任务:
type ExecutorJob struct {
Host string `json:"host"`
IPs []string `json:"ips"`
Id int64 `json:"id"`
Start int64 `json:"start"`
End int64 `json:"end"`
}
[UI设计]
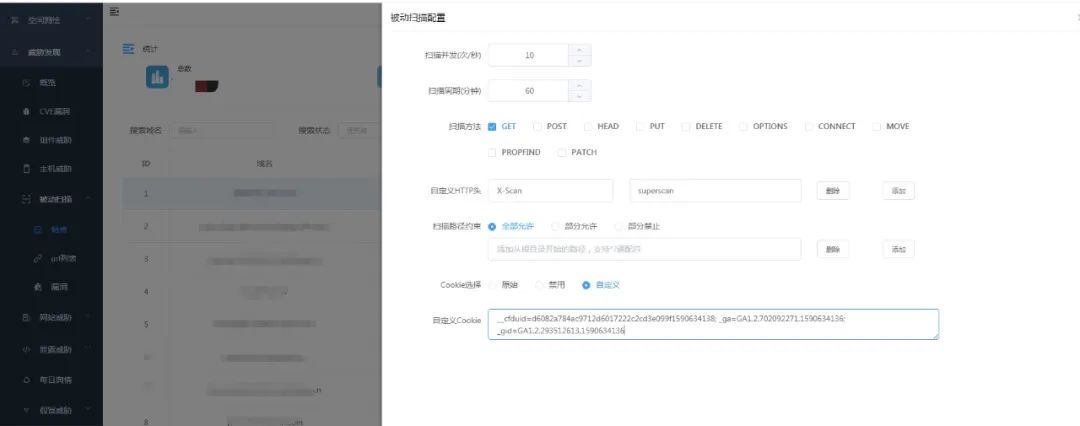

细节 & 实现
??????? passive被动扫描开发语言采用golang,底层使用了k8s+openfaas,对于被动扫描来说,底层实现有多种多样,k8s和openfaas并不是必须的。
在上图中superscan-cron-passive发送给superscan-passive-executor的任务,是数据驱动的,可以通过消息队列、celery等模式替代。
superscan-cron-passive本身的定时执行也可以用crontab的模式或者代码实现定时任务。下文中使用k8s和openfaas的部署配置只详细描述一次,其他重复地方省略处理。
[流量源Elasticsearch]
????????在流沙平台的文章中我们介绍了,使用packetbeat从镜像流量中采集HTTP协议数据,经kafka缓存,后使用自研<摆渡程序>做加工处理后存储Elasticsearch。流量采集的位置肯定是SSL卸载之后的位置,这时可能有两种情况,SSL卸载之后还有1-2n级的7层转发,例如nginx;在这个转发之前获取到的流量中ip字段指向的是7层转发设备(程序)的地址,之后获取到的应用的实际IP。不管是在之前还是之后,我们都可以通过得到的这个ip访问到目标网站。
????????在流沙平台的文章中我们分享了不同的采集点通过标记(beat.name字段)区分流量来源,例如生产环境、测试环境、办公网等。对于被动扫描来说建议先在测试环境和办公网进行测试、实验,不要直接使用生产环境的流量。一是生产环境的流量过大,开销大,二是对生产环境的扫描可能对正在运行的业务系统造成不良影响。
????????我们对packetbeat做了改造,并且在后续的数据处理中数据做了加工,所以在本文中看到的http数据结构和packetbeat直接输出的有些不同,请大家自行理解字段对应关系。
[svc-litedns]
litedns使用golang开发,支持upstream,支持通过http配置dns,支持缓存,通过redis支持持久化。
原本的域名解析指向的是公网出口ip,litedns的作用是给[svc-xraypassive]提供域名解析服务,将要扫描的域名的解析指向实际中的内网ip字段(即上一节中的ip字段)
源码:?https://github.com/chennqqi/litedns
k8s部署:
apiVersion: apps/v1
kind: Deployment
metadata:
name: litedns
spec:
selector:
matchLabels:
app: litedns
strategy:
type: Recreate
replicas: 1
template:
metadata:
labels:
app: litedns
spec:
nodeSelector:
role: node
terminationGracePeriodSeconds: 3
containers:
- name: litedns
image: superscan/litedns
ports:
- containerPort: 8080
name: http
- containerPort: 53
name: udp
protocol: UDP
env:
- name: GIN_MODE
value: release
---
kind: Service
apiVersion: v1
metadata:
name: svc-litedns
spec:
sessionAffinity: ClientIP
clusterIP: 10.254.0.3 # headless 模式 会返回多个A记录, 否则返回clusterIP
selector:
app: litedns
ports: #port不能省略
- name: http
port: 8080
targetPort: 8080
- name: udp
port: 53
targetPort: 53
protocol: UDP
说明: k8s svc的clusterIP可以选择固定IP,none自动分配,headless几种模式。对于litedns应当使用固定分配IP模式,因为/etc/resovle.conf中配置nameserver使用的是IP, 10.254.0.3可以任意指定,只要不是k8s中已分配IP即可。
单机环境部署:
docker run -d --name=litedns -p53:53/udp -p8080:8080 superscan/litedns:latest
53/udp端口是DNS服务端口
8080/tcp端口是http的控制端口
[svc-xraypassive]
FROM centos:7
ARG version=0.21.0
WORKDIR /app
ADD https://github.com/chaitin/xray/releases/download/${version}/xray_linux_amd64.zip /app
RUN yum install -y unzip && \
unzip xray_linux_amd64.zip && \
mv xray_linux_amd64 xray && \
rm -f xray_linux_amd64.zip
ADD config.yaml /app/config.yaml
EXPOSE 8080
USER app
CMD ["/app/xray", "--config", "/app/config.yaml", "webscan", "--listen", "0.0.0.0:8080", "--webhook-output", "http://gateway.openfaas.svc.cluster.local:8080/function/superscan-passive-webhook" ]
说明关于config.yaml参考https://xray.cool/xray/#/configration/mitm 进行配置
--webhook-output?参数"http://gateway.openfaas.svc.cluster.local:8080/function/superscan-passive-webhook?为
superscan-passive-webhook通过openfaas网关访问的地址。这里如果是在单机环境修改为单击环境的地址即可
k8s部署:
apiVersion: apps/v1
kind: Deployment
metadata:
name: xraypassive
spec:
selector:
matchLabels:
app: xraypassive
strategy:
type: Recreate
replicas: 3
template:
metadata:
labels:
app: xraypassive
spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 10.254.0.3
options:
- name: ndots
value: "5"
nodeSelector:
role: node
terminationGracePeriodSeconds: 10
containers:
- name: xraypassive
image: superscan/xraypassive
ports:
- containerPort: 8080
name: http
---
kind: Service
apiVersion: v1
metadata:
name: svc-xraypassive
spec:
sessionAffinity: ClientIP
clusterIP: headless # headless 模式 会返回多个A记录, 否则返回clusterIP
selector:
app: xraypassive
ports: #port不能省略
- name: http
port: 8080
targetPort: 8080
单机环境:
docker run -d --name=litedns --dns=10.254.0.3 -p8080:8080 superscan/xraypassive:latest
在k8s中通过dnsConfig来制定xraypassive使用的DNS地址,在单机docker环境中使用--dns来指定xray使用的DNS地址
这里ClusterIP使用headless,这样在kube-dns解析svc-xraypassive时会返回多个pod的ip地址,我们在superscan-passive-executor时根据IP来进行网站的分配,可以让我们做到同一个网站流量路由到通过一个xraypassive实例上,不同网站分配到不同的xraypassive上
[svc-xrayreverse]
Dockefile和配置类似于[svc-xraypassive], 关于reverse模式请参考https://xray.cool/xray/#/configration/reverse进行配置
[svc-xrayreverse]部署比较简单,1个实例即可。
[superscan-cron-passive]
1.周期性运行,从流量发现新域名,这部分是复用superscan的空间测绘-域名发现中从流量中发现域名资产的代码。
Elasticsearch聚合查询语法如下
GET <index>/_search
{
"aggregations": {
"hosts": {
"aggregations": {
"ips": {
"terms": {
"field": "ip"
}
}
},
"terms": {
"field": "request.host",
"size": 2048
}
}
},
"query": {
"bool": {
"filter": [
{
"range": {
"unix_time": {
"from": <start>,
"include_lower": true,
"include_upper": false,
"to": <end>
}
}
},
{
"term": {
"beat.name": "<测试区/办公网>"
}
}
],
"must": {
"terms": {
"response.code": [
"200",
"201",
"202",
"203",
"204",
"205",
"206",
"207",
"300",
"301",
"302",
"303",
"304",
"305",
"306",
"307"
]
}
}
}
},
"size": 0
}
更新网站域名、URL信息。
这里我们只取请求<400的情况, 一次聚合取到了全部的request.host和其内网ip, 在第一聚合结果hosts的doc_count表示每个host的的数量,可以更新到域名站点表里,表示当前域名请求量的大小,提供给运营人员决策是否要扫描该站点
2.创建任务, 被动扫描扫描哪个网站要经过人工运营和确认,也在扫描之前跟业务人员沟通一下,避免安全部门接锅。
我们在一次Elasticsearch聚合中已经获取到了域名和后端IP,根据域名在配置(mysql)查询当前域名是否被配置为需要被进行扫描
任务定义:
{
"host": "<host>",
"start": <start unix time>,
"end": <end unix time>
"backends" [ "xx", "yy" ]
}
backends表示获取到的ip列表
openfaas部署:
superscan-cron-passive:
lang: golang-middleware
handler: ./superscan-cron-passive
image: ${DOCKER_USER:-superscan}/superscan-cron-passive:latest
readonly_root_filesystem: true
build_options:
- timezone
environment_file:
- conf.yml
annotations:
topic: cron-function
schedule: "*/10 * * * *"
labels:
com.openfaas.scale.zero: "false"
com.openfaas.scale.min: 1 # replicas fixed 1
schedule配置语法同crontab, 注意openfaas的crontab支持是第三方扩展https://github.com/zeerorg/cron-connector
k8s部署:
使用?kind: CronJob?方式来部署
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cron-passive
spec:
schedule: "*/10 * * * *"
failedJobsHistoryLimit: 1
successfulJobsHistoryLimit: 3
jobTemplate:
spec:
template:
spec:
containers:
- name: cron-passive
image: superscan/cron-passive
# ...其他配置....#
k8s的Cronjob schedule配置语法同crontab
单机环境:
可以使用crontab或者也可以使用?https://github.com/robfig/cron
[superscan-passive-executor]
由[superscan-cron-passive]发送到任务驱动执行,本质上是个执行任务的worker模型。
1.根据任务,从Elasticsearch中拉取流量,并进行去重
Elasticsearch请求查询语法如下:
GET <index>/_search?scroll=1m
{
"source": [
"request.*", "ip"
]
"query": {
"bool": {
"filter": [
{
"range": {
"unix_time": {
"from": <start>,
"include_lower": true,
"include_upper": false,
"to": <end>
}
}
},
{
"term": {
"request.host": "<host>"
}
}
],
"must": {
"terms": {
"response.code": [
"200",
"201",
"202",
"203",
"204",
"205",
"206",
"207",
"300",
"301",
"302",
"303",
"304",
"305",
"306",
"307"
]
}
}
}
},
"size": 0
}
GET _search/scroll
{
"scroll": "1m",
"scroll_id" : "<scroll_id>"
}
关于请求去重算法可以开一个很大的篇幅讨论,这里我给一个最简单的实现,去重算法可以根据实际情况不断改进。hash=murmur64(method+url+strings.Join(sort(params),",")),将方法、url、排序后的参数进行murmur64 hash。你有什么好的去重方法可以留言分享
2.获取到请求将其还原成request结构。在这一步我们可以实现按照用户配置进行请求过滤:
只允许扫描GET,允许配置扫描方法
只允许扫描某些目录,禁止扫描某些目录
自定义header,自定义cookie,清除cookie等操作
3.配置并发送请求给xraypassive
配置[svc-litedns]解析地址,使[svc-xraypassive]可以将域名解析到内网ip。
获取[svc-xraypassiv]实例地址,按照实例ip配置http代理,将同一个域名下的请求发送到同一个[svc-xraypassive]实例。
这里给出一个简单的路由算法
proxy_ip = sort(hosts)[ hash(host) % len(hosts) ]
按照域名取模,将实例ip排序,按照余数取值
openfaas部署:
superscan-passive-executor:
lang: golang-middleware
handler: ./superscan-passive-executor
image: ${DOCKER_USER:-superscan}/superscan-passive-executor:latest
readonly_root_filesystem: true
labels:
com.openfaas.scale.min: 1 # replicas fixed 1
com.openfaas.scale.max: 12
实例数量可以配置为1-N,或者让openfaas做auto-scale
这里分享个小技巧,在发送请求时将请求的唯一编号通过添加到header中,这样在[superscan-passive-webhook]中提取该编码就可以将请求和漏洞关联起来
[superscan-passive-webhook]
接收[svc-xraypassive]发送来的状态推送、漏洞推送,将漏洞记录并入库。
这个模块我们可以实现一个用户体验上的需求。一个漏洞的状态有
新发现 首次发现,同一请求不再扫描
已确认 人工确认漏洞存在,同一请求不再扫描
已忽略 人工确认为误报, 同一请求不再扫描
已修复 业务已将漏洞修复,一般是已确认之后进行修复,修复后状态变更为已修复,扫描
重新打开 已修复的漏洞下次扫描时再次发现后状态变更为重新打开
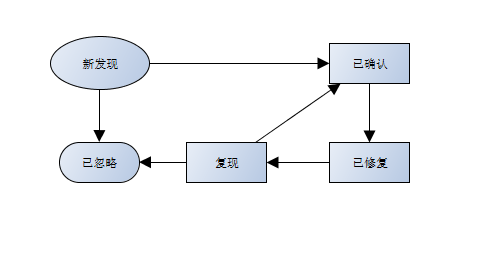
这个重新打开的状态,可以用来跟踪修复情况,还有修复后回滚导致的漏洞复现问题。
在[superscan-passive-executor]中可以过滤掉新发现、已确认、已忽略三种状态的请求,减少不必要的扫描
[其他]
[superscan-passive-admin]是在openfaas中实现的管理后端,有多种方式可以将接口暴露出去。
1.通过k8s ingress直接将openfaas的网关暴露出去,推荐
2.通过k8s node port暴露网关,不推荐
3.本系统中,整个superscan的web管理后端接口已经通过k8s ingress暴露出去了,而且有完善的认证、鉴权机制,所以最后通过管理程序做了反向代理来实现将[superscan-passive-admin]服务暴露到k8s外部,使用的包为golang的[net/http/httputil]https://pkg.go.dev/net/http/httputil?tab=doc#NewSingleHostReverseProxy包
经验总结
1.建议优先在测试环境和办公网流量基础上进行实践;
2.[superscan-cron-passive]每次请求得到的域名,不仅仅用来发现新网站域名,对于已有网站数据也要进行相关状态更新,提供给运营人员辅助决策是否要决定对已有站点进行检测。
3.[superscan-cron-passive]每次请求间隔不宜过长,过长导致cookie/token失效;不宜过短,频繁请求没有必要。
4.[svc-xraypassive]使用headless模式,通过客户端的负载实现同一个网站流量路由到通过一个xraypassive实例上,不同网站分配到不同的xraypassive实例上
5.被动扫描扫描哪个网站要经过人工确认,也在扫描之前跟业务人员沟通一下,避免影响业务正常运行。
6.在进行扫描时除了去重,也要维护同一个请求不要重复扫描,要设置一个扫描间隔
7.可以过滤掉新发现、已确认、已忽略三种状态的请求,减少不必要的扫描
8.在Elasticsearch中拉取请求流量时,过滤掉由[svc-xraypassive]发出的请求
9.通过自定header将请求和漏洞关联起来
10.通过自定义DNS来让xray扫描内网
11.尽量使用测试账号,正式账号尽量不要使用GET/HEAD之外的方法进行扫描
12.过滤掉扫描器发出的流量,可以在xray配置文件中自定义特殊header标记
优点
1.可能出现性能瓶颈的地方都支持1->N的扩展
2.开发简单
3.部署简单,所有实例都可以一键部署
4.支持cookie/token和自定义header
5.支持过滤请求方法、路径、指定域名
缺点 && TODO
1.登录功能,根据配置的测试帐号通过登录接口实现自动登录
2.xray为黑盒,扩展性有限; 目前xray只支持单个host的请求频率,不支持配置指定任意host的请求频率,也不支持动态配置;每次修改配置需要重启xray
3.URL去重算法还有优化空间
4.依赖于流量平台
5.token认证模式下有效期跟踪问题
FAQ
1.为什么使用xray做被动扫描?
??????? xray天然支持代理模式,可以快速集成到被动扫描中,且扫描效果不错。在这套方案下,实现一个类似于xray的扫描替换掉xray也是很容易的。但是这就成了另一个话题了,如何做扫描器和扫描调优的问题了,也是对开篇说道本文不对扫描器实现做深入讨论的回应。一开始也尝试过w3af等开源扫描器,也尝试过自己开发,最后综合从精力耗费、维护成本的角度考虑,选择了xray的方案,而且xray也有商业版本,有后续升级的空间。
2.packetbeat和elk的版本?
? ? ? ? 与流沙平台的版本统一使用v5.6, packetbeat部分做过改造,处理了标准json库http编码的问题,处理了压缩的问题;编码的问题对于请求有影响,而压缩的问题仅适用于返回体,对本文内容无影响。
3.没有流量怎么使用被动扫描?
????????没有流量就创造流量,简单可以搭建MITM代理,基于python开发的mitmproxy是个很好的解决方案;测试人员、办公网人员访问测试网站时通过搭建的MITM代理访问,在mitmproxy上获取请求,将请求转到到被动扫描上。在镜像流量上可以通过配置、改造packetbeat,只保留请求,将接收到的请求经过过滤、去重之后投递到被动扫描中,从而简化前置要求。
参考引用
openfaas 官方文档
https://docs.openfaas.com/
kubernetes 官方文档
https://kubernetes.io/docs/
elasticsearch query dsl
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/query-dsl.html
elasticsearch 聚合查询
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/search-aggregations.html
elasticsearch scroll查询
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/search-request-scroll.html
golang-middleware function源码
https://github.com/openfaas-incubator/golang-http-template
openfaas cron-connector源码
https://github.com/zeerorg/cron-connector
litedns 源码
https://github.com/chennqqi/litedns
kubernetes Cronjob
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
murmurhash
http://en.wikipedia.org/wiki/MurmurHash
k8s service clusterIP配置
https://kubernetes.io/zh/docs/concepts/services-networking/service/
k8s ingress
https://kubernetes.io/zh/docs/concepts/services-networking/ingress/
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 宜信安全应急响应中心
宜信安全应急响应中心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675