
三万英尺看分布式存储中本地存储引擎
最近几年存储介质得到了高速发展,单位存储介质的性能越来越高,从原来的机械硬盘不足 100 IOPS 到现在的 NVMe SSD 一块就能达到 50W IOPS,但与之形成反差的是 CPU 的速度提升并没有那么多,根据 Red Hat 的相关数据统计,存储介质由原来的单盘几十 IOPS 到现在的单盘 50 万 IOPS,但是 CUP 的主频增长的速度相对并没有那么快,而不同的存储介质每个 IO 需要的 CPU 时钟周期也各不相同,如在 HDD 中一个 IO 需要 2000 万时钟周期,在 NMVE 设备中只需要 6000 时钟周期。
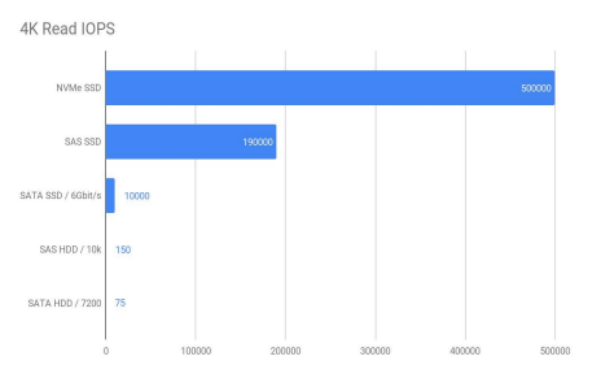
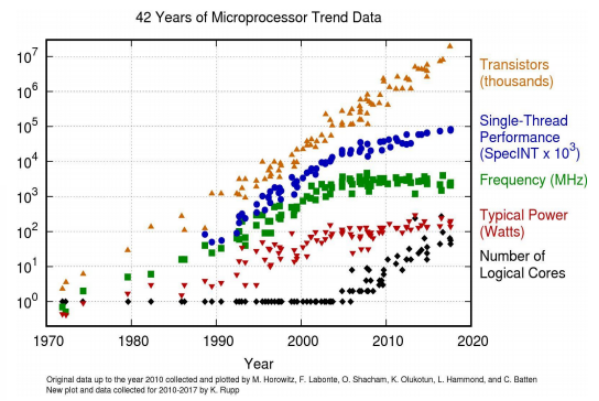
(▲图表及数据均来源于 Red Hat)
With a cpu clocked at 3ghz you can afford:
HDD: ~20 million cycles/IO
SSD: 300,000 cycles/IO
NVMe: 6000 cycles/IO?
在这样的背景下,对于存储软件来说能否发挥出存储介质的高性能,其关键是如何高效利用 CPU,其中,单核 CPU 能够提供的 IOPS,是存储系统的一个关键指标。
而分布式存储作为当前存储系统的一个重要分支,其软件定义的特征,能够更好更快地适配新硬件的发展,成为了存储领域的热点。
我们先简单地聊聊分布式存储中开源领域在适配新硬件的进展,而说到开源的分布式存储,我们一定会想到明星开源项目 Ceph,它在国内外都被广泛使用,其良好的扩展性和稳定性也获得大家一致认可。
在 Ceph 的迭代发展中,其本地存储引擎 ObjectStore 也经过了两代的发展,由最初的 FileStore,到现在广泛使用的 BlueStore,但是这些存储引擎对于高性能的存储介质(如 NVMe SSD 等)都存在一定的不足。
所以社区也在 2018 年提出了新一代本地存储引擎 SeaStore,对细节感兴趣的读者可以访问 https://docs.ceph.com/docs/master/dev/seastore/。
下面笔者根据个人的理解对 SeaStore 的设计做一个简单解读。
SeaStore 的设计目标
1.面向 NVMe 设计,不考虑 PEME 和 HDD。
2.使用 SPDK 实现用户态 IO。
3.使用 Seastar 框架进行基于 future&promise 的编程方式实现 run-to-completion。
4.结合 Seastar 的网络消息层实现读写路径上的零(最小)拷贝。
对于目标 1、2,面向 NVMe 的设计,笔者认为主要是指当前的 NVMe 设备是可以使用用户态驱动的,即可以不通过系统内核,使用 Polling 模型能够明显降低 IO 延时。
同时对于 NVMe 设备来说,由于其 erase-before-write 特性带来的 GC 问题需要被高效解决,理论上通过 discard 作为一种 hint 机制可以让上层软件启发底层闪存去安排 GC,但实际上大部分闪存设备的 discard 实现的并不理想,因此需要上层软件的介入。
对于目标 3、4,是从如何降低 CPU 的角度去考虑底层存储设计的,如上文中也提到对于高性能的分布式存储,CPU 会成为系统瓶颈,如何提高 CPU 的有效使用率是一个重点考虑的问题。
目标 3 中采用 run-to-completion 的方式能够避免线程切换和锁的开销,从而有效提高 CPU 的使用率,Intel 曾经发布报告说明,在 Block Size 为 4KB 的情况下,单线程利用 SPDK 能够提供高达 1039 万 IOPS,充分说明了使用单线程异步编程的方式能够有效提升 CPU 的使用率。
而目标 4 则需要充分结合网络模型,一致性协议等,实现零拷贝,来降低在模块中内存拷贝次数。
基于 SeaStore 的设计目标,具体的设计方案中主要考虑了通过 segment 的数据布局来实现的 NMVE 设备的 GC 优化,以及上层如果控制 GC 时的相关处理,同时在文档中也提到了用 B-tree 的方式实现元数据的存储,而没有采用类似 bluestore 中使用 RocksDB 来存储元数据的方式。
但是笔者认为,这个设计对于实现的难度可能比较高,当前的 rados 不仅仅是存储数据还有大量的元数据存储的功能。
如 OMAP 和 XATTR,这些小的 KV 信息实际如果采用新写一个 B-tree 的方式进行存储,那相当于需要实现一个专有的小型 KV 数据库,这个功能实现难度会非常大,而类似直接使用简单的 B-tree 存储元数据就会落入类型 XFS 等文件系统存储元数据的困境,不能存储大量 xattr 的问题。
上文中只是简单的描述的 Ceph 对下一代存储引擎的设计构思,如果想等到具体的开源来实现估计还需要个 3 到 5 年的开发周期。
而我们对高性能分布式存储的需求又非常热切,所以我们存储团队就独立设计了一个全新的存储引擎来满足高性能分布式存储的需求。
下面我们简单介绍深信服企业级分布式存储 EDS 团队在高性能本地存储的实践之路。
PFStore 设计与实现
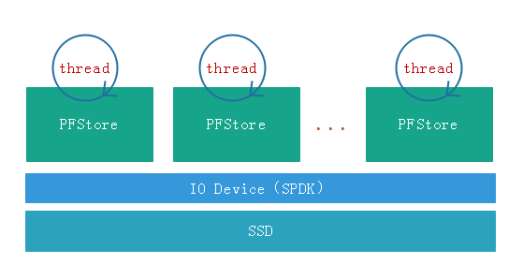
PFStore(Phoenix Fast Store)是 EDS 团队自研的基于 SPDK 的用户态本地存储引擎,它的核心架构如下图所示。
在系统中主要有数据管理和元数据管理两大核心模块,下面介绍一下两大核心模块的职责和技术特点:
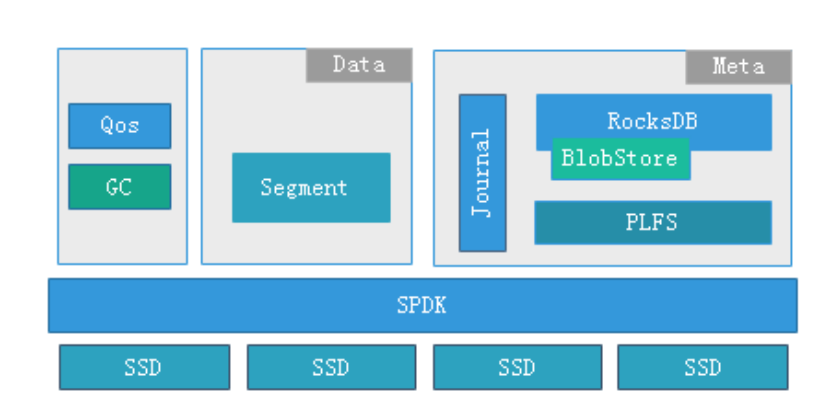
数据管理模块职责:它是一个 segment 空间管理的基础单元,所有的数据都是以追加写入的,即底层的 SSD 都是顺序写入的,这样能够尽可能发挥每块 SSD 的性能,降低 SSD 本身 GC 带来的开销。
同时整个 store 的系统都是基于 SPDK 的中 spdk_thread 编程模型实现的,整个 IO 过程全部在一个独立线程中完成,所以不会有线程切换和锁的开销。
当然全异步的编程方式会导致开发的难度比较高,所以我们研发内部也提炼了一套基于状态机的异步编程方式,在各个子系统都采用一个子状态机,这样既保证了系统的高性能,也保证了系统的可维护性和可扩展性。
元数据管理模块职责:对于我们元数据的存储,我们借鉴了 Ceph 中 ?BlueStore 的 Rocksdb 方式,也是采用一个简化的用户态文件系统 PLFS 来对接 Rocksdb。
而采用这样的方式,也是因为我们重点考查了 LSM 和 B-tree 的存储结构的不同及能够带来的收益,对于存储引擎中频繁的数据写入,相对简洁的元数据管理(本地存储引擎提供的对象存储接口,元数据层次是平铺的),采用 LSM 有利于提升系统写性能。
下面分别介绍一下本地存储引擎的技术特点。
元数据引擎技术特点:
①使用自研 Journal,替换 RocksDB 的 WAL,这样我们的元数据的修改都是增量地写入到 Journal 中,在后期定时刷盘时才写入到 RocksDB 中。
这个改进是基于下面几点方面的原因:
PLStore 是全异步的编程模型,而 RocksDB 的接口是同步的,会阻塞整个 IO 路径,性能比较差。
Journal 的数据是增量更新的,这样能够实现聚合的方式写入,降低元数据写入次数。
Journal 不仅仅记录了 Object 的元数据更新,还承载了分布式一致性协议中的 LOG 功能(类似 Ceph 中的 PGLOG),而多个功能融合能够减少数据的写入次数。
②改进 RocksDB 的 compact 处理,在数据聚合时在内存中建立一个基于 B-tree 的位置索引,这样在 RocksDB 的数据读取时,可以直接通过索引获得数据的位置信息,然后利用位置信息直接通过异步的数据读取口。
这样就将原有的 RocksDB 同步读接口改造成了异步,能够明显地提升单线程下的读取能力,通过实测有 5-8 倍的提升。
数据存储引擎技术特点:
对于数据使用追加写的方式,更加有利于发挥每块 SSD 性能,能够实现更加丰富的数据逻辑空间管理,为存储的一些高级特性,如快照、克隆、压缩重删的实现提供基础。
与此同时,使得我们需要在 store 层实现空间回收(GC),而空间回收的设计对提升追加写的存储系统性能和稳定性至关重要。
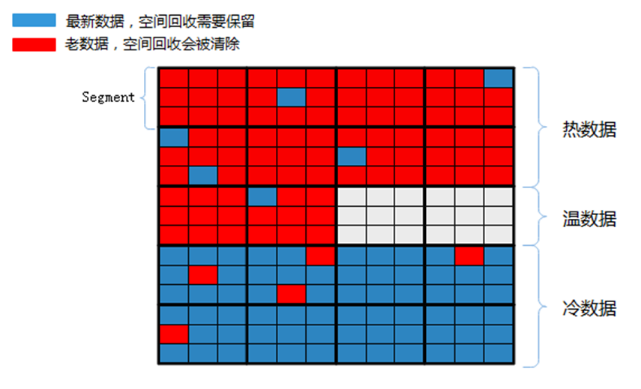
如上图所示,我们将数据分为 3 个层次:
热数据,经常被更新的数据,并且被集中存放在 SSD zone1 的数据区中
温数据,被更新次数较少的数据,被集中存放在 SSD zone2 的数据区中
冷数据,最少被更新的数据,被集中存放在 SSD zone3 的数据区中
其中 zone 由多个 segment 构成,通过数据的分层管理,能够实现在空间回收时将需要被回收的数据集中存放,这样在执行空间回收的过程搬动的数据量较少,在空间回收时对正常业务的性能影响较小。同时在执行空间回收的过程中需要回写的数据量较少,能够有效的较低空间回收对 SSD 寿命的影响。
在进行数据分区管理后,空间回收是以 segment 为执行单位,可以通过灵活的空间回收的策略选择代价较小(需要搬动数据较少)的 segment 进行空间回收,这种空间回收过程对上层业务的性能影响较小,而且配合 SSD 中 discard 指令,还能够降低对 SSD 的寿命的影响。
在空间回收的处理时,PFStore 同时会配合其 Qos 模块,选择合适的时机进行空间回收,从各个方向降低对正常业务的影响,避免分布式系统中出现性能抖动和“毛刺”。
PFStore 只在一个线程中运行,采用 run-to-completion 的编程模型,这样既简化了系统,也消除了系统的性能抖动。
总结
对于一个分布式系统而言,本地存储引擎只是一个基础组件,需要与其他模块,如一致性协议,网络传输等模块相互配合才能发挥其价值。Ceph 社区在 2018 年提出 Seastore 草案后,在 2019 年又重新提出了新的 OSD(Crimson)来满足高性能应用场景的需求。感兴趣的同学可以阅读 Crimson:A New Ceph OSD for the Age of Persistent Memory and Fast NVMe Storage 的相关内容。
最近几年存储领域有着非常大的进展,硬件领域中非易失性内存、SCM 等技术的逐步成熟与落地,NVMe-OF 等协议逐渐被各个操作系统所支持,同时学术界也出现很多好的 Idea,这些都促进了分布式存储的软件革新和高速发展。
深信服 EDS 团队未来的重点也将放在改进软件架构来更好适配硬件,从而提升系统整体的性价比。
作者介绍
煜子,十年以上存储开发经验,目前在深信服任职存储架构师,负责 EDS 新型分布式存储引擎 PFStore 的技术演进。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 51CTO技术栈
51CTO技术栈
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675