
作词家下岗系列:教你用 AI 做一个写歌词的软件!


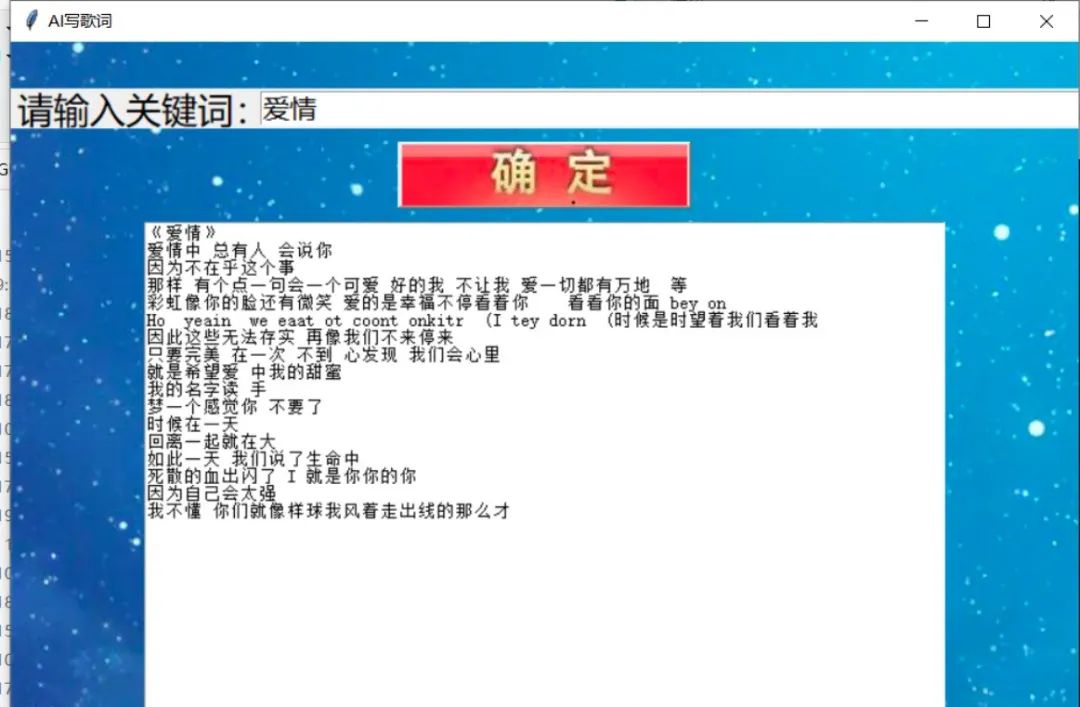
x(t)x(t)代表在序列索引号tt时训练样本的输入。同样的,x(t?1)x(t?1)和x(t+1)x(t+1)代表在序列索引号t?1t?1和t+1t+1时训练样本的输入。
h(t)h(t)代表在序列索引号tt时模型的隐藏状态。h(t)h(t)由x(t)x(t)和h(t?1)h(t?1)共同决定。
o(t)o(t)代表在序列索引号tt时模型的输出。o(t)o(t)只由模型当前的隐藏状态h(t)h(t)决定。
L(t)L(t)代表在序列索引号tt时模型的损失函数。
y(t)y(t)代表在序列索引号tt时训练样本序列的真实输出。
U,W,VU,W,V这三个矩阵是我们的模型的线性关系参数,它在整个RNN网络中是共享的,这点和DNN很不相同。也正因为是共享了,它体现了RNN的模型的“循环反馈”的思想。 ?

实验前的准备

RNN算法搭建
1、数据集处理和准备:

2、模型的训练:
首先要读取数据集
设定训练批次、步数等等
数据载入RNN进行训练即可
def?train():
????filename?=?'date.txt'
????with?open(filename,?'r',?encoding='utf-8')?as?f:
????????text?=?f.read()
????reader?=?TxtReader(text=text,?maxVocab=3500)
????reader.save('voc.data')
????array?=?reader.text2array(text)
????generator?=?GetBatch(array,?n_seqs=100,?n_steps=100)
????model?=?CharRNN(
????????????????????numClasses?=?reader.vocabLen,
????????????????????mode?='train',
????????????????????numSeqs?=?100,?
????????????????????numSteps?=?100,
????????????????????lstmSize?=?128,?
????????????????????numLayers?=?2,?
????????????????????lr?=?0.001,?
????????????????????Trainprob?=?0.5,?
????????????????????useEmbedding?=?True,?
????????????????????numEmbedding?=?128
????????????????)
????model.train(
????????????????generator,
????????????????logStep?=?10,?
????????????????saveStep?=?1000,
????????????????maxStep?=?100000
????????????????)
#?创建输入
????def?buildInputs(self):
????????numSeqs?=?self.numSeqs
????????numSteps?=?self.numSteps
????????numClasses?=?self.numClasses
????????numEmbedding?=?self.numEmbedding
????????useEmbedding?=?self.useEmbedding
????????with?tf.name_scope('inputs'):
????????????self.inData?=?tf.placeholder(tf.int32,?shape=(numSeqs,?numSteps),?name='inData')
????????????self.targets?=?tf.placeholder(tf.int32,?shape=(numSeqs,?numSteps),?name='targets')
????????????self.keepProb?=?tf.placeholder(tf.float32,?name='keepProb')
????????????#?中文
????????????if?useEmbedding:
????????????????with?tf.device("/cpu:0"):
????????????????????embedding?=?tf.get_variable('embedding',?[numClasses,?numEmbedding])
????????????????????self.lstmInputs?=?tf.nn.embedding_lookup(embedding,?self.inData)
????????????#?英文
????????????else:
????????????????self.lstmInputs?=?tf.one_hot(self.inData,?numClasses)
????#?创建单个Cell
????def?buildCell(self,?lstmSize,?keepProb):
????????basicCell?=?tf.nn.rnn_cell.BasicLSTMCell(lstmSize)
????????drop?=?tf.nn.rnn_cell.DropoutWrapper(basicCell,?output_keep_prob=keepProb)
????????return?drop
????#?将单个Cell堆叠多层
????def?buildLstm(self):
????????lstmSize?=?self.lstmSize
????????numLayers?=?self.numLayers
????????keepProb?=?self.keepProb
????????numSeqs?=?self.numSeqs
????????numClasses?=?self.numClasses
????????with?tf.name_scope('lstm'):
????????????multiCell?=?tf.nn.rnn_cell.MultiRNNCell(
????????????????????[self.buildCell(lstmSize,?keepProb)?for?_?in?range(numLayers)]
????????????????)
????????????self.initial_state?=?multiCell.zero_state(numSeqs,?tf.float32)
????????????self.lstmOutputs,?self.finalState?=?tf.nn.dynamic_rnn(multiCell,?self.lstmInputs,?initial_state=self.initial_state)
????????????seqOutputs?=?tf.concat(self.lstmOutputs,?1)
????????????x?=?tf.reshape(seqOutputs,?[-1,?lstmSize])
????????????with?tf.variable_scope('softmax'):
????????????????softmax_w?=?tf.Variable(tf.truncated_normal([lstmSize,?numClasses],?stddev=0.1))
????????????????softmax_b?=?tf.Variable(tf.zeros(numClasses))
????????????self.logits?=?tf.matmul(x,?softmax_w)?+?softmax_b
????????????self.prediction?=?tf.nn.softmax(self.logits,?name='prediction')
????#?计算损失
????def?buildLoss(self):
????????numClasses?=?self.numClasses
????????with?tf.name_scope('loss'):
????????????targets?=?tf.one_hot(self.targets,?numClasses)
????????????targets?=?tf.reshape(targets,?self.logits.get_shape())
????????????loss?=?tf.nn.softmax_cross_entropy_with_logits(logits=self.logits,?labels=targets)
????????????self.loss?=?tf.reduce_mean(loss)
????#?创建优化器
????def?buildOptimizer(self):
????????gradClip?=?self.gradClip
????????lr?=?self.lr
????????trainVars?=?tf.trainable_variables()
????????#?限制权重更新
????????grads,?_?=?tf.clip_by_global_norm(tf.gradients(self.loss,?trainVars),?gradClip)
????????trainOp?=?tf.train.AdamOptimizer(lr)
????????self.optimizer?=?trainOp.apply_gradients(zip(grads,?trainVars))
????#?训练
????def?train(self,?data,?logStep=10,?saveStep=1000,?savepath='./models/',?maxStep=100000):
????????if?not?os.path.exists(savepath):
????????????os.mkdir(savepath)
????????Trainprob?=?self.Trainprob
????????self.session?=?tf.Session()
????????with?self.session?as?sess:
????????????step?=?0
????????????sess.run(tf.global_variables_initializer())
????????????state_now?=?sess.run(self.initial_state)
????????????for?x,?y?in?data:
????????????????step?+=?1
????????????????feed_dict?=?{
????????????????????????????????self.inData:?x,
????????????????????????????????self.targets:?y,
????????????????????????????????self.keepProb:?Trainprob,
????????????????????????????????self.initial_state:?state_now
????????????????????????????}
????????????????loss,?state_now,?_?=?sess.run([self.loss,?self.finalState,?self.optimizer],?feed_dict=feed_dict)
????????????????if?step?%?logStep?==?0:
????????????????????print('[INFO]:?<step>:?{}/{},?loss:?{:.4f}'.format(step,?maxStep,?loss))
????????????????if?step?%?saveStep?==?0:
????????????????????self.saver.save(sess,?savepath,?global_step=step)
????????????????if?step?>?maxStep:
????????????????????self.saver.save(sess,?savepath,?global_step=step)
????????????????????break
????#?从前N个预测值中选
????def?GetTopN(self,?preds,?size,?top_n=5):
????????p?=?np.squeeze(preds)
????????p[np.argsort(p)[:-top_n]]?=?0
????????p?=?p?/?np.sum(p)
????????c?=?np.random.choice(size,?1,?p=p)[0]
????????return?c
def?main(_):
????reader?=?TxtReader(filename='voc.data')
????model?=?CharRNN(
????????????????????numClasses?=?reader.vocabLen,
????????????????????mode?=?'test',
????????????????????lstmSize?=?128,?
????????????????????numLayers?=?2,?
????????????????????useEmbedding?=?True,?
????????????????????numEmbedding?=?128
????????????????)
????checkpoint?=?tf.train.latest_checkpoint('./models/')
????model.load(checkpoint)
????key="雪花"
????prime?=?reader.text2array(key)
????array?=?model.test(prime,?size=reader.vocabLen,?n_samples=300)
????print("《"+key+"》")
????print(reader.array2text(array))

界面的定义和调用

1、界面布局:
root?=?tk.Tk()
root.title('AI写歌词')
#?背景
canvas?=?tk.Canvas(root,?width=800,?height=500,?bd=0,?highlightthickness=0)
imgpath?=?'1.jpg'
img?=?Image.open(imgpath)
photo?=?ImageTk.PhotoImage(img)
imgpath2?=?'3.jpg'
img2?=?Image.open(imgpath2)
photo2?=?ImageTk.PhotoImage(img2)
canvas.create_image(700,?400,?image=photo)
canvas.pack()
label=tk.Label(text="请输入关键词:",font=("微软雅黑",20))
entry?=?tk.Entry(root,?insertbackground='blue',?highlightthickness=2,font=("微软雅黑",15))
entry.pack()
entry1?=?tk.Text(height=15,width=115)
entry1.pack()
2、功能调用:
def?song():
????ss=entry.get()
????f=open("1.txt","w")
????f.write(ss)
????f.close()
????os.startfile("1.bat")
????while?True:
????????if?os.path.exists("2.txt"):
????????????f=open("2.txt")
????????????ws=f.read()
????????????f.close()
????????????entry1.insert("0.0",?ws)
????????????break
????try:
????????os.remove("1.txt")
????????os.remove("2.txt")
????except:
????????pass
import?tkinter?as?tk
from?PIL?import?ImageTk,?Image
import?os
try:
????os.remove("1.txt")
????os.remove("2.txt")
except:
????pass
import?os
def?song():
????ss=entry.get()
????f=open("1.txt","w")
????f.write(ss)
????f.close()
????os.startfile("1.bat")
????while?True:
????????if?os.path.exists("2.txt"):
????????????f=open("2.txt")
????????????ws=f.read()
????????????f.close()
????????????entry1.insert("0.0",?ws)
????????????break
????try:
????????os.remove("1.txt")
????????os.remove("2.txt")
????except:
????????pass
root?=?tk.Tk()
root.title('AI写歌词')
#?背景
canvas?=?tk.Canvas(root,?width=800,?height=500,?bd=0,?highlightthickness=0)
imgpath?=?'1.jpg'
img?=?Image.open(imgpath)
photo?=?ImageTk.PhotoImage(img)
imgpath2?=?'3.jpg'
img2?=?Image.open(imgpath2)
photo2?=?ImageTk.PhotoImage(img2)
canvas.create_image(700,?400,?image=photo)
canvas.pack()
label=tk.Label(text="请输入关键词:",font=("微软雅黑",20))
entry?=?tk.Entry(root,?insertbackground='blue',?highlightthickness=2,font=("微软雅黑",15))
entry.pack()
entry1?=?tk.Text(height=15,width=115)
entry1.pack()
bnt?=?tk.Button(width=15,height=2,image=photo2,command=song)
canvas.create_window(100,?50,?width=200,?height=30,
?????????????????????window=label)
canvas.create_window(500,?50,?width=630,?height=30,
?????????????????????window=entry)
canvas.create_window(400,?100,?width=220,?height=50,
?????????????????????window=bnt)
canvas.create_window(400,?335,?width=600,?height=400,
?????????????????????window=entry1)
root.mainloop()?

作者简介 :
李秋键,CSDN?博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap安卓武侠游戏一部,vip视频解析,文意转换工具,写作机器人等项目,发表论文若干,多次高数竞赛获奖等等。

AI修复100年前晚清影像喜提热搜,这两大算法立功了
CycleGan人脸转为漫画脸,牛掰的知识又增加了 | 附代码 用大白话彻底搞懂 HBase RowKey 详细设计 为什么黑客无法攻击公开的区块链? 再见 Python,Hello Julia! 百万人学AI 万人在线大会, 15+场直播抢先看!

你点的每个“在看”,我都认真当成了AI
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675