
微信也在用的Transformer加速推理工具 | 腾讯第100个对外开源项目
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
近年来,基于Transformer的模型,可以说是在NLP界杀出了一片天地。
虽然在提高模型模型精度上,Transformer发挥了不容小觑的作用,但与此同时,却引入了更大的计算量。
那么,这个计算量有多大呢?
来看下数据。
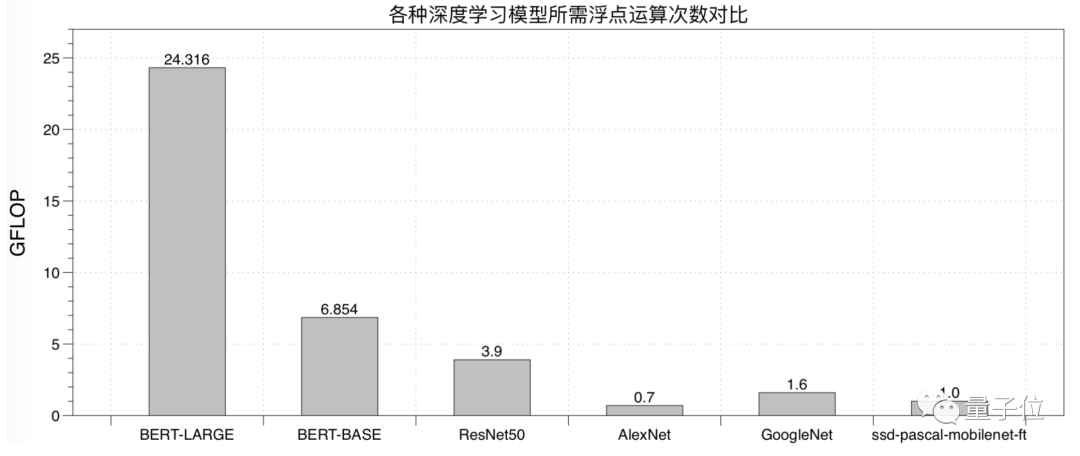
因此,实现一个能充分发挥CPU/GPU硬件计算能力的Transformer推理方法,就成了急需解决的问题。
近日,腾讯便开源了一个叫TurboTransformers的工具,对Transformer推理过程起到了加速作用,让你的推理引擎变得更加强大。

这个工具已经在微信、腾讯云、QQ看点等产品中广泛应用,在线上预测场景中可以说是“身经百战”。
Turbo具有如下三大特性:
优异的CPU/GPU性能表现。
为NLP推理任务特点量身定制。
简单的使用方式。
值得一提的是,TurboTransformers,是腾讯通过Github对外开源的第100个项目。
那么,具有如此“纪念意义”的开源工具,到底有多厉害?
接下来,我们将一一讲解。
多项性能测试“摘桂冠”
Turbo在CPU/GPU性能上的表现可以说是非常优异。
在多种CPU和GPU硬件上获得了超过pytorch/tensorflow和目前主流优化引擎的性能表现。
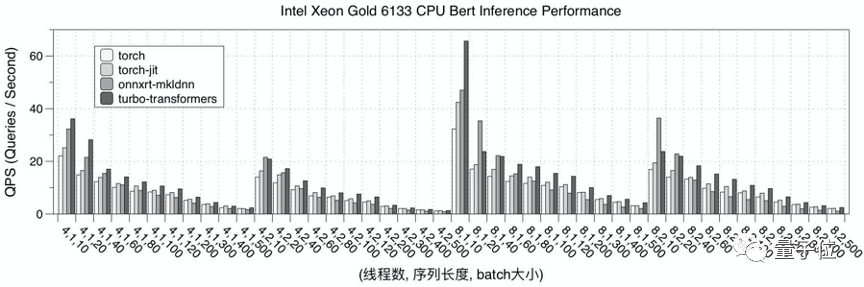
CPU上的测试结果
首先,是在CPU 硬件平台上,测试了 TurboTransformers 的性能表现。
选择 pytorch、pytorch-jit 和 onnxruntime-mkldnn 和 TensorRT 实现作为对比。
性能测试结果为迭代 150 次的均值。为了避免多次测试时,上次迭代的数据在 cache 中缓存的现象,每次测试采用随机数据,并在计算后刷新的 cache 数据。
下图是Intel Xeon 6133 CPU的性能测试结果。

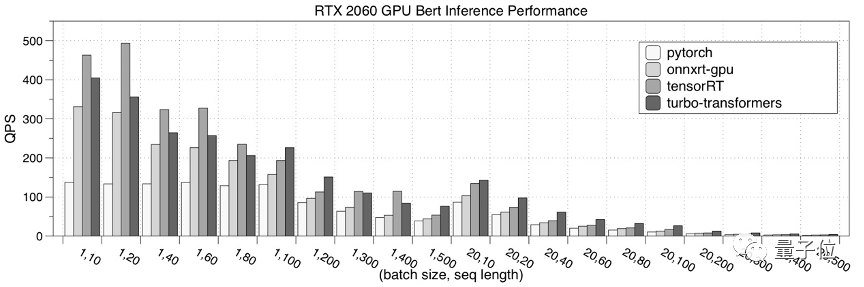
GPU上的测试结果
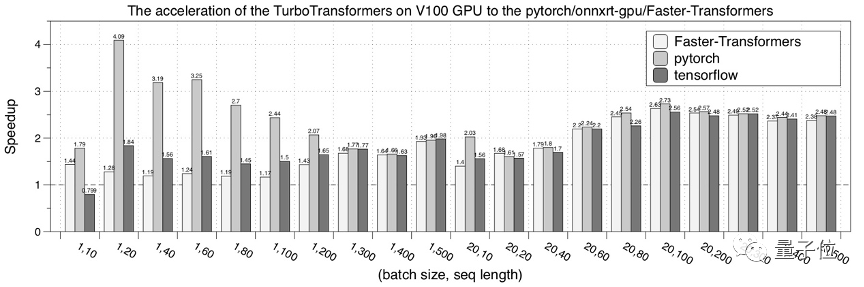
其次,是在GPU硬件平台上,测试了 TurboTransformers 的性能表现。
选择对比的对象分别是:pytorch、NVIDIA Faster Transformers、onnxruntime-gpuTensorRT。
性能测试结果为迭代 150 次的均值。
下图是在NVIDIA RTX 2060 GPU的性能测试结果。
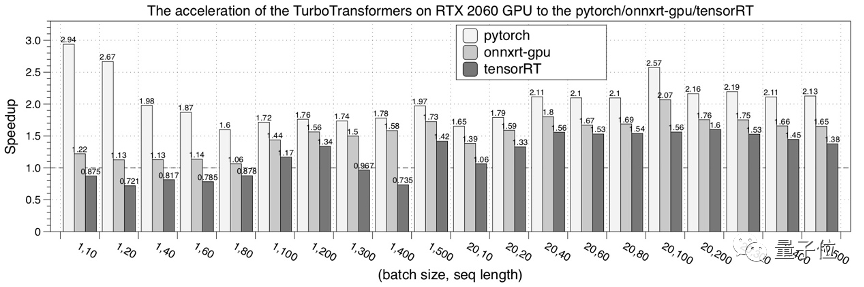
接下来,是在NVIDIA P40 GPU的性能测试结果。
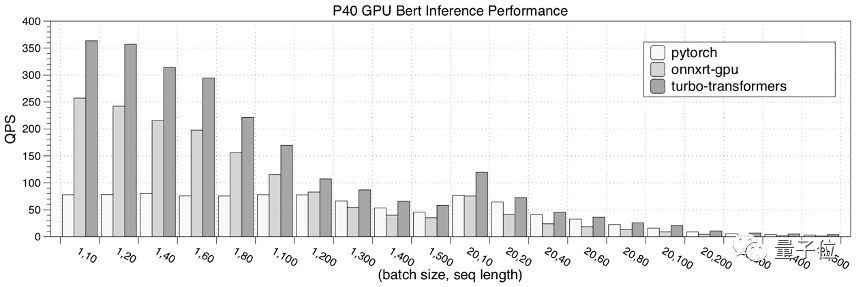
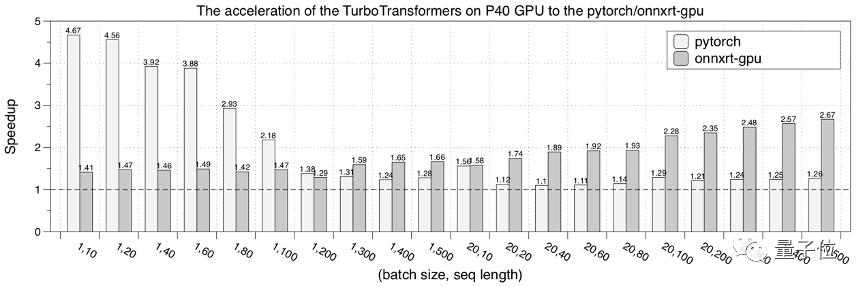
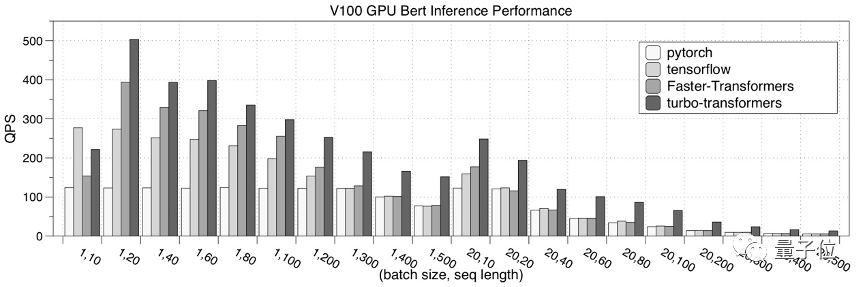
最后,是在NVIDIA V100 GPU的性能测试结果。
Turbo技术原理
能够取得如此好的推理性能,这背后的计算原理又是什么呢?
TurboTransformers的软件架构如下图,它让微信内部众多NLP线上应用能够充分榨取底层硬件的计算能力,让算法更好地服务的用户。
具体来说TurboTransformers可以在算子优化、框架优化和接口部署方式简化三个方面做了工作。

算子层优化
Transformer都包含了什么计算呢?
如下图所示,图(a)展示了论文Transformer结构示意图,这里称灰色方框内的结构为一个Transformer Cell,BERT encoder堆叠了Nx个这样的Transformer Cell。
图(b)将一个Cell的细节加以展开,每一个矩形都是一个独立的计算核心。

Transformer Cell计算包含了8个GEMM(通用矩阵乘法,General Matrix Multiplication)运算。通过调优Intel MKL和cuBLAS的GEMM调用方式来获得最佳GEMM性能。
并且在硬件允许条件下,在GPU上使用tensor core方式进行GEMM运算。
类似NVIDIA FasterTransformers方案,将所有GEMM运算之间的计算融合成一个调用核心。融合会带来两个好处,一是减少了内存访问开销,二是减少多线程启动开销。
对于这些核心,在CPU上采用openmp进行并行,在GPU上使用CUDA进行优化实现。
对于比较复杂的LayerNorm和Softmax算子,它们包含了不适合GPU上并行的规约操作,TurboTransformers为它们设计了创新并行算法,极大降低了这些算子的延迟。
理论上Transformers推理延迟应该近似于矩阵乘法延迟。
框架层优化
TurboTransformers采用了一个有效的内存管理方式。
由于NLP的采用变长输入特性,每次运算中间结果的大小其实并不相同。为了避免每次都分配释放内存,研究人员通过Caching方式管理显存。
为了能够无缝支持pytorch/tensorflow训练好的序列化模型,提供了一些脚本可以将二者的预训练模型转化为npz格式,供TurboTransformers读入。
特别的,考虑到pytorch huggingface/transformers是目前最流行的transformers训练方法,支持直接读入huggingface/transformers预训练模型。
应用部署
Turbo提供了C++和Python调用接口,可以嵌入到C++多线程后台服务流程中,也可以加入到pytorch服务流程中。
研究人员建议TurboTransformers通过docker部署,一方面保证了编译的可移植性,另一方面也可以无缝应用于K8S等线上部署平台。
传送门
GitHub项目地址:
https://github.com/Tencent/TurboTransformers/blob/master/README_cn.md
— 完 —
PaddleCV 专题大课首场4月28日线上开讲
百度AI快车道——企业深度学习实战营系列报名开始啦!
本次集训营,共5场学习内容,聚焦CV技术专题内容,带领大家围绕计算机视觉的图像分类、目标检测、图像分割、各类文字识别及模型压缩这五大常见任务,系统性学习,提供CV领域的前沿技术和快速应用之道。
课程结束,通过学习评测,可获得课程结业证书
扫码免费报名!


量子位?QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
喜欢就点「在看」吧 !
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675