
推荐 :常见损失函数和评价指标总结(附公式&代码)
作者:董文辉
本文长度为4500字,建议阅读10+分钟
本文为你总结常见损失函数和评价指标。
一、损失函数 1.1 回归问题 1.2 分类问题 二、评价指标 2.1 回归问题
2.2 分类问题
参考资料
一、损失函数
1.1 回归问题
1. 平方损失函数(最小二乘法):
2. 平均绝对值误差(L1)-- MAE:
3. MAE(L1) VS MSE(L2):
MSE计算简便,但MAE对异常点有更好的鲁棒性:当数据中存在异常点时,用MSE/RMSE计算损失的模型会以牺牲了其他样本的误差为代价,朝着减小异常点误差的方向更新。然而这就会降低模型的整体性能。
直观上可以这样理解:如果我们最小化MSE来对所有的样本点只给出一个预测值,那么这个值一定是所有目标值的平均值。但如果是最小化MAE,那么这个值,则会是所有样本点目标值的中位数。众所周知,对异常值而言,中位数比均值更加鲁棒,因此MAE对于异常值也比MSE更稳定。
NN中MAE更新梯度始终相同,而MSE则不同:MSE损失的梯度随损失增大而增大,而损失趋于0时则会减小。 Loss选择建议: MSE:如果异常点代表在商业中很重要的异常情况,并且需要被检测出来 MAE:如果只把异常值当作受损数据
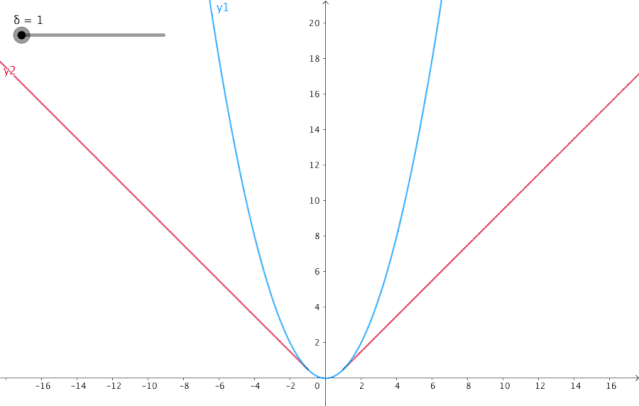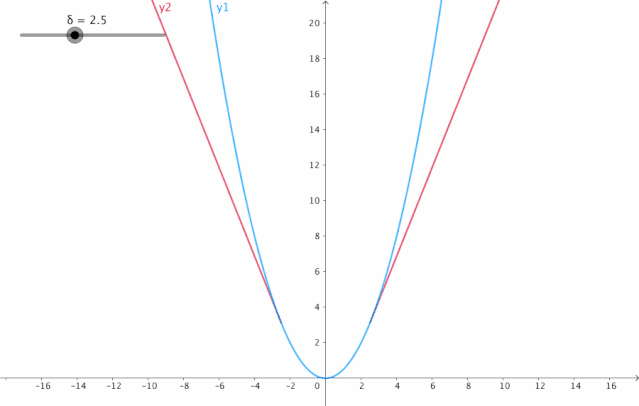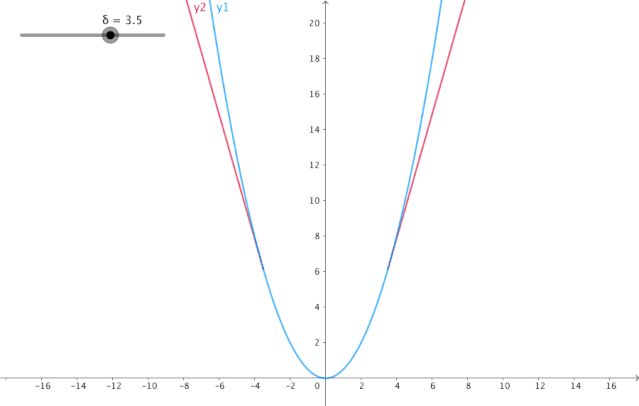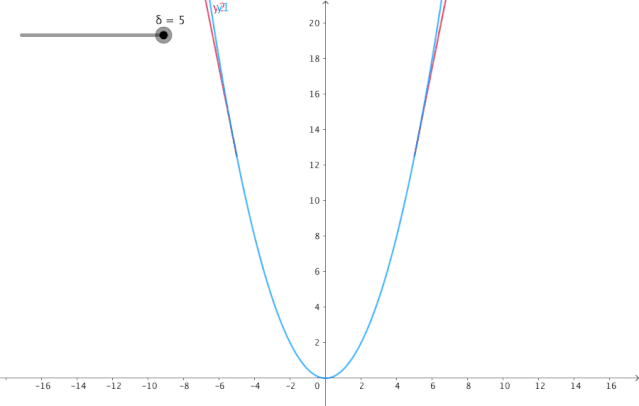
4. Huber损失:
当Huber损失在之间时,等价为MSE 在和时等价为MAE
使用MAE训练神经网络最大的一个问题就是不变的大梯度,这可能导致在使用梯度下降快要结束时,错过了最小点。而对于MSE,梯度会随着损失的减小而减小,使结果更加精确。在这种情况下,Huber损失就非常有用。它会由于梯度的减小而落在最小值附近。比起MSE,它对异常点更加鲁棒。因此,Huber损失结合了MSE和MAE的优点。但是,Huber损失的问题是我们可能需要不断调整超参数delta。
1.2 分类问题:
1. LogLoss:
2. 指数损失函数:
二、评价指标
2.1 回归问题
分母代表baseline(平均值)的误差,分子代表模型的预测结果产生的误差; 预测结果越大越好,为1说明完美拟合,为0说明和baseline一致;
# coding=utf-8import numpy as npfrom sklearn import metricsfrom sklearn.metrics import r2_score# MAPE和SMAPE需要自己实现def mape(y_true, y_pred):return np.mean(np.abs((y_pred - y_true) / y_true)) * 100def smape(y_true, y_pred):return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])y_pred = np.array([1.0, 4.5, 3.5, 5.0, 8.0, 4.5, 1.0])# MSEprint(metrics.mean_squared_error(y_true, y_pred)) # 8.107142857142858# RMSEprint(np.sqrt(metrics.mean_squared_error(y_true, y_pred))) # 2.847304489713536# MAEprint(metrics.mean_absolute_error(y_true, y_pred)) # 1.9285714285714286# MAPEprint(mape(y_true, y_pred)) # 76.07142857142858# SMAPEprint(smape(y_true, y_pred)) # 57.76942355889724# R Squaredprint(r2_score(y_true, y_pred))
2.2 分类问题
0. Confusion Matrix(混淆矩阵):
| 预测正例 | 预测反例 | |
|---|---|---|
| 真实正例 | TP(真正例) | FN(假反例) |
| 真实反例 | FP(假正例) | TN(真反例) |
降低假负数例(FN):假设在一个癌症检测问题中,每100个人中就有5个人患有癌症。在这种情况下,即使是一个非常差的模型也可以为我们提供95%的准确度。但是,为了捕获所有癌症病例,当一个人实际上没有患癌症时,我们可能最终将其归类为癌症。因为它比不识别为癌症患者的危险要小,因为我们可以进一步检查。但是,错过癌症患者将是一个巨大的错误,因为不会对其进行进一步检查。 降低假正例(FP):假设在垃圾邮件分类任务中,垃圾邮件为正样本。如果我们收到一个正常的邮件,比如某个公司或学校的offer,模型却识别为垃圾邮件(FP),那将损失非常大。所以在这种任务中,需要尽可能降低假正例。
1. Accuracy(准确率):
2. Precision(精准率):
3. Recall(召回率):
4. P-R曲线:

如果一个学习器的P-R曲线被另一个学习器的曲线完全包住,后者性能优于前者; 如果两个学习器的曲线相交,可以通过平衡点(如上图所示)来度量性能; 阈值下降: Recall:不断增加,因为越来越多的样本被划分为正例,假设阈值为0.,全都划分为正样本了,此时recall为1; Precision:正例被判为正例的变多,但负例被判为正例的也变多了,因此precision会振荡下降,不是严格递减; 如果有个划分点可以把正负样本完全区分开,那么P-R曲线面积是1*1;
5.?(加权调和平均)和?(调和平均):
:召回率(Recall)影响更大,eg. :精确率(Precision)影响更大,eg.
6. ROC-AUC:
横轴-假正例率:?实际为负的样本多少被预测为正;
纵轴-真正例率:?实际为正的样本多少被预测为正;

阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1); ROC曲线越靠近左上角,该分类器的性能越好; 对角线表示一个随机猜测分类器; 若一个学习器的ROC曲线被另一个学习器的曲线完全包住,后者性能优于前者;
7. 代码实现:
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,fbeta_scorey_test = [1,1,1,1,0,0,1,1,1,0,0]y_pred = [1,1,1,0,1,1,0,1,1,1,0]print("准确率为:{0:%}".format(accuracy_score(y_test, y_pred)))print("精确率为:{0:%}".format(precision_score(y_test, y_pred)))print("召回率为:{0:%}".format(recall_score(y_test, y_pred)))print("F1分数为:{0:%}".format(f1_score(y_test, y_pred)))print("Fbeta为:{0:%}".format(fbeta_score(y_test, y_pred,beta =1.2)))
参考资料:
[1]分类问题性能评价指标详述:?
https://blog.csdn.net/foneone/article/details/88920256
[2]AUC,ROC我看到的最透彻的讲解:
https://blog.csdn.net/u013385925/article/details/80385873
[3]机器学习大牛最常用的5个回归损失函数,你知道几个?:
https://www.jiqizhixin.com/articles/2018-06-21-3
[4]机器学习-损失函数:?
https://www.csuldw.com/2016/03/26/2016-03-26-loss-function/
[5]损失函数jupyter notebook:
https://nbviewer.jupyter.org/github/groverpr/Machine-Learning/blob/master/notebooks/05_Loss_Functions.ipynb
[6]L1 vs. L2 Loss function:
http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/
[7]P-R曲线深入理解:?
https://blog.csdn.net/b876144622/article/details/80009867
原文链接:
https://zhuanlan.zhihu.com/p/91511706
END
转自:?数据派THU 公众号;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
合作请加QQ:365242293??
数据分析(ID?:?ecshujufenxi?)互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 数据分析
数据分析
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675