
面试被问 DFS 和 BFS 就跪了?这份图文详解你赶紧收好 !


深度优先遍历,广度优先遍历简介
习题演练
DFS,BFS 在搜索引擎中的应用

深度优先遍历,广度优先遍历简介
1、深度优先遍历


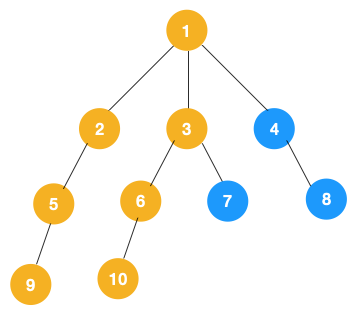
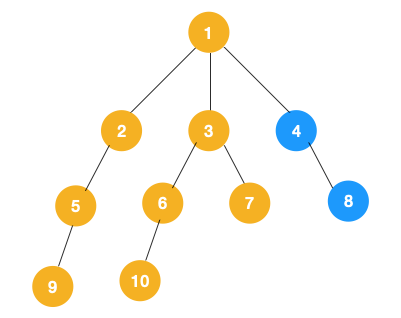
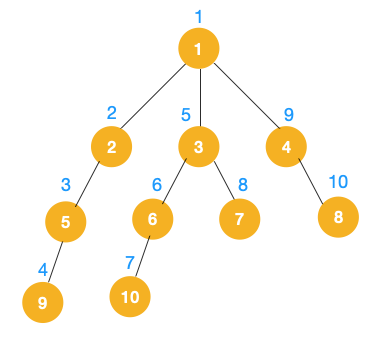
递归实现
public?class?Solution?{
????private?static?class?Node?{
????????/**
?????????*?节点值
?????????*/
????????public?int?value;
????????/**
?????????*?左节点
?????????*/
????????public?Node?left;
????????/**
?????????*?右节点
?????????*/
????????public?Node?right;
????????public?Node(int?value,?Node?left,?Node?right)?{
????????????this.value?=?value;
????????????this.left?=?left;
????????????this.right?=?right;
????????}
????}
????public?static?void?dfs(Node?treeNode)?{
????????if?(treeNode?==?null)?{
????????????return;
????????}
????????//?遍历节点
????????process(treeNode)
????????//?遍历左节点
????????dfs(treeNode.left);
????????//?遍历右节点
????????dfs(treeNode.right);
????}
}递归的表达性很好,也很容易理解,不过如果层级过深,很容易导致栈溢出。所以我们重点看下非递归实现
非递归实现
对于每个节点来说,先遍历当前节点,然后把右节点压栈,再压左节点(这样弹栈的时候会先拿到左节点遍历,符合深度优先遍历要求)
弹栈,拿到栈顶的节点,如果节点不为空,重复步骤 1, 如果为空,结束遍历。
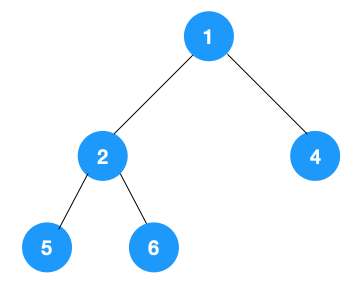

/**
?*?使用栈来实现?dfs
?*?@param?root
?*/
public?static?void?dfsWithStack(Node?root)?{
????if?(root?==?null)?{
????????return;
????}
????Stack<Node>?stack?=?new?Stack<>();
????//?先把根节点压栈
????stack.push(root);
????while?(!stack.isEmpty())?{
????????Node?treeNode?=?stack.pop();
????????//?遍历节点
????????process(treeNode)
????????//?先压右节点
????????if?(treeNode.right?!=?null)?{
????????????stack.push(treeNode.right);
????????}
????????//?再压左节点
????????if?(treeNode.left?!=?null)?{
????????????stack.push(treeNode.left);
????????}
????}
}可以看到用栈实现深度优先遍历其实代码也不复杂,而且也不用担心递归那样层级过深导致的栈溢出问题。
2、广度优先遍历

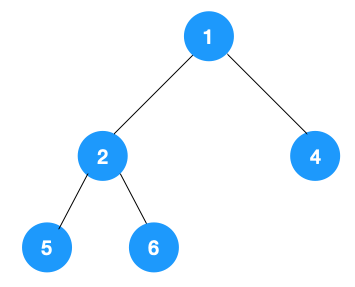

/**
?*?使用队列实现?bfs
?*?@param?root
?*/
private?static?void?bfs(Node?root)?{
????if?(root?==?null)?{
????????return;
????}
????Queue<Node>?stack?=?new?LinkedList<>();
????stack.add(root);
????while?(!stack.isEmpty())?{
????????Node?node?=?stack.poll();
????????System.out.println("value?=?"?+?node.value);
????????Node?left?=?node.left;
????????if?(left?!=?null)?{
????????????stack.add(left);
????????}
????????Node?right?=?node.right;
????????if?(right?!=?null)?{
????????????stack.add(right);
????????}
????}
}
习题演练习题演练

leetcode 104,111: 给定一个二叉树,找出其最大/最小深度。
????3
???/?\
??9??20
????/??\
???15???7则它的最小深度 2,最大深度 3。
/**
?*?leetcode?104:?求树的最大深度
?*?@param?node
?*?@return
?*/
public?static?int?getMaxDepth(Node?node)?{
????if?(node?==?null)?{
????????return?0;
????}
????int?leftDepth?=?getMaxDepth(node.left)?+?1;
????int?rightDepth?=?getMaxDepth(node.right)?+?1;
????return?Math.max(leftDepth,?rightDepth);
}
/**
?*?leetcode?111:?求树的最小深度
?*?@param?node
?*?@return
?*/
public?static?int?getMinDepth(Node?node)?{
????if?(node?==?null)?{
????????return?0;
????}
????int?leftDepth?=?getMinDepth(node.left)?+?1;
????int?rightDepth?=?getMinDepth(node.right)?+?1;
????return?Math.min(leftDepth,?rightDepth);
}
leetcode 102: 给你一个二叉树,请你返回其按层序遍历得到的节点值。(即逐层地,从左到右访问所有节点)。示例,给定二叉树:[3,9,20,null,null,15,7]
????3
???/?\
??9??20
????/??\
???15???7
[
??[3],
??[9,20],
??[15,7]
]

/**
?*?leetcdoe?102:?二叉树的层序遍历,?使用?bfs
?*?@param?root
?*/
private?static?List<List<Integer>>?bfsWithBinaryTreeLevelOrderTraversal(Node?root)?{
????if?(root?==?null)?{
????????//?根节点为空,说明二叉树不存在,直接返回空数组
????????return?Arrays.asList();
????}
????//?最终的层序遍历结果
????List<List<Integer>>?result?=?new?ArrayList<>();
????Queue<Node>?queue?=?new?LinkedList<>();
????queue.offer(root);
????while?(!queue.isEmpty())?{
????????//?记录每一层
????????List<Integer>?level?=?new?ArrayList<>();
????????int?levelNum?=?queue.size();
????????//?遍历当前层的节点
????????for?(int?i?=?0;?i?<?levelNum;?i++)?{
????????????Node?node?=?queue.poll();
????????????//?队首节点的左右子节点入队,由于?levelNum?是在入队前算的,所以入队的左右节点并不会在当前层被遍历到
????????????if?(node.left?!=?null)?{
????????????????queue.add(node.left);
????????????}
????????????if?(node.right?!=?null)?{
????????????????queue.add(node.right);
????????????}
????????????level.add(node.value);
????????}
????????result.add(level);
????}
????return?result;
}
class?Solution:
????def?levelOrder(self,?root):
????????"""
????????:type?root:?TreeNode
????????:rtype:?List[List[int]]
????????"""
????????res?=?[]??#嵌套列表,保存最终结果
????????if?root?is?None:
????????????return?res
????????from?collections?import?deque
????????que?=?deque([root])??#队列,保存待处理的节点
????????while?len(que)!=0:
????????????lev?=?[]??#列表,保存该层的节点的值
????????????thislevel?=?len(que)??#该层节点个数
????????????while?thislevel!=0:
????????????????head?=?que.popleft()??#弹出队首节点
????????????????#队首节点的左右孩子入队
????????????????if?head.left?is?not?None:
????????????????????que.append(head.left)
????????????????if?head.right?is?not?None:
????????????????????que.append(head.right)
????????????????lev.append(head.val)??#队首节点的值压入本层
????????????????thislevel-=1
????????????res.append(lev)
????????return?res
private?static?final?List<List<Integer>>?TRAVERSAL_LIST??=?new?ArrayList<>();
/**
?*?leetcdoe?102:?二叉树的层序遍历,?使用?dfs
?*?@param?root
?*?@return
?*/
private?static?void?dfs(Node?root,?int?level)?{
????if?(root?==?null)?{
????????return;
????}
????if?(TRAVERSAL_LIST.size()?<?level?+?1)?{
????????TRAVERSAL_LIST.add(new?ArrayList<>());
????}
????List<Integer>?levelList?=?TRAVERSAL_LIST.get(level);
????levelList.add(root.value);
????//?遍历左结点
????dfs(root.left,?level?+?1);
????//?遍历右结点
????dfs(root.right,?level?+?1);
}

DFS,BFS 在搜索引擎中的应用


总结



关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 程序人生
程序人生
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675