
面试官:背了几道面试题就敢说熟悉Java源码?我们不招连源码都不会看的人|原力计划



你看源码么? 你会看源码么? 你从源码中有收获么?

String?index?out?of?range:?100
public?String?substring(int?beginIndex,?int?endIndex)?{
????????if?(beginIndex?<?0)?{//起始坐标小于0
????????????throw?new?StringIndexOutOfBoundsException(beginIndex);
????????}
????????if?(endIndex?>?value.length)?{//结束坐标大于字符串长度
????????????throw?new?StringIndexOutOfBoundsException(endIndex);
????????}
????????int?subLen?=?endIndex?-?beginIndex;
????????if?(subLen?<?0)?{//起始坐标大于结束坐标
????????????throw?new?StringIndexOutOfBoundsException(subLen);
????????}
????????return?((beginIndex?==?0)?&&?(endIndex?==?value.length))???this
????????????????:?new?String(value,?beginIndex,?subLen);
????}
if?((beginIndex?==?0)?&&?(endIndex?==?value.length))?return?this;
???return?new?String(value,?beginIndex,?subLen);
3.学习设计模式(针对新手)
import?java.util.ResourceBundle;
public?class?Configration?{
????private?static?Object?lock??????????????=?new?Object();
????private?static?Configration?config?????=?null;
????private?static?ResourceBundle?rb????????=?null;
????private?Configration(String?filename)?{
????????rb?=?ResourceBundle.getBundle(filename);
????}
????public?static?Configration?getInstance(String?filename)?{
????????synchronized(lock)?{
????????????if(null?==?config)?{
????????????????config?=?new?Configration(filename);
????????????}
????????}
????????return?(config);
????}
????public?String?getValue(String?key)?{
????????String?ret?=?"";
????????if(rb.containsKey(key))
????????{
????????????ret?=?rb.getString(key);
????????}
????????return?ret;
????}
}




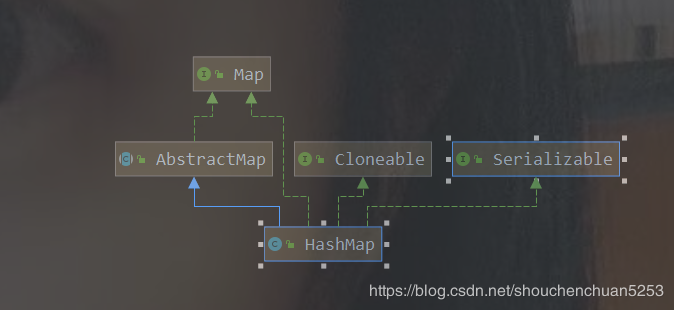
public?class?HashMap<K,V>?extends?AbstractMap<K,V>
????implements?Map<K,V>,?Cloneable,?Serializable?
public?HashMap(int?initialCapacity)?{
????????this(initialCapacity,?DEFAULT_LOAD_FACTOR);
????}
//序列号
????private?static?final?long?serialVersionUID?=?362498820763181265L;
????/**
?????*?初始容量,必须是2的幂数
?????*?1?<<?4?=?10000?=?16
?????*/
????static?final?int?DEFAULT_INITIAL_CAPACITY?=?1?<<?4;?//?初始默认值二进制1左移四位?=?16
????/**
?????*?最大容量
?????*?必须是2的幂数?<=?1<<30.
?????*/
????static?final?int?MAXIMUM_CAPACITY?=?1?<<?30;
????/**
?????*?加载因子,构造函数中没有指定时会被使用
?????*/
????static?final?float?DEFAULT_LOAD_FACTOR?=?0.75f;
????/**
?????*?从链表转到树的时机
?????*/
????static?final?int?TREEIFY_THRESHOLD?=?8;
????/**
?????*?从树转到链表的时机
?????*/
????static?final?int?UNTREEIFY_THRESHOLD?=?6;
????/**
?????*?The?smallest?table?capacity?for?which?bins?may?be?treeified.
?????*?(Otherwise?the?table?is?resized?if?too?many?nodes?in?a?bin.)
?????*?Should?be?at?least?4?*?TREEIFY_THRESHOLD?to?avoid?conflicts
?????*?between?resizing?and?treeification?thresholds.
?????*/
????static?final?int?MIN_TREEIFY_CAPACITY?=?64;? ??
这样,我们就对HashMap中常量的作用和意义有所理解了
????/**
?????*?构造一个空的,带有初始值和初始加载因子的HashMap
?????*?@param??initialCapacity?the?initial?capacity.
?????*?@throws?IllegalArgumentException?if?the?initial?capacity?is?negative.
?????*/
????public?HashMap(int?initialCapacity)?{
????????this(initialCapacity,?DEFAULT_LOAD_FACTOR);
????}
??/**
?????*
?????*?@param??initialCapacity?the?initial?capacity
?????*?@param??loadFactor??????the?load?factor
?????*?@throws?IllegalArgumentException?if?the?initial?capacity?is?negative
?????*?????????or?the?load?factor?is?nonpositive
?????*/
????public?HashMap(int?initialCapacity,?float?loadFactor)?{
????????if?(initialCapacity?<?0)
????????????throw?new?IllegalArgumentException("Illegal?initial?capacity:?"?+
???????????????????????????????????????????????initialCapacity);
????????if?(initialCapacity?>?MAXIMUM_CAPACITY)
????????????initialCapacity?=?MAXIMUM_CAPACITY;
????????if?(loadFactor?<=?0?||?Float.isNaN(loadFactor))
????????????throw?new?IllegalArgumentException("Illegal?load?factor:?"?+
???????????????????????????????????????????????loadFactor);
????????this.loadFactor?=?loadFactor;
????????this.threshold?=?tableSizeFor(initialCapacity);
????}
??static?final?int?tableSizeFor(int?cap)?{
????????int?n?=?cap?-?1;
????????n?|=?n?>>>?1;
????????n?|=?n?>>>?2;
????????n?|=?n?>>>?4;
????????n?|=?n?>>>?8;
????????n?|=?n?>>>?16;
????????return?(n?<?0)???1?:?(n?>=?MAXIMUM_CAPACITY)???MAXIMUM_CAPACITY?:?n?+?1;
????}
public?V?put(K?key,?V?value)?{
????????return?putVal(hash(key),?key,?value,?false,?true);
????}
static?final?int?hash(Object?key)?{
????int?h;
????return?(key?==?null)???0?:?(h?=?key.hashCode())?^?(h?>>>?16);
}
/**
?????*?Implements?Map.put?and?related?methods.
?????*
?????*?@param?hash?hash?for?key
?????*?@param?key?the?key
?????*?@param?value?the?value?to?put
?????*?@param?onlyIfAbsent?if?true,?don't?change?existing?value
?????*?@param?evict?if?false,?the?table?is?in?creation?mode.
?????*?@return?previous?value,?or?null?if?none
?????*/
????final?V?putVal(int?hash,?K?key,?V?value,?boolean?onlyIfAbsent,
???????????????????boolean?evict)?{
????????Node<K,V>[]?tab;?Node<K,V>?p;?int?n,?i;
????????if?((tab?=?table)?==?null?||?(n?=?tab.length)?==?0)
????????????n?=?(tab?=?resize()).length;
????????if?((p?=?tab[i?=?(n?-?1)?&?hash])?==?null)
????????????tab[i]?=?newNode(hash,?key,?value,?null);
????????else?{
????????????Node<K,V>?e;?K?k;
????????????if?(p.hash?==?hash?&&
????????????????((k?=?p.key)?==?key?||?(key?!=?null?&&?key.equals(k))))
????????????????e?=?p;
????????????else?if?(p?instanceof?TreeNode)
????????????????e?=?((TreeNode<K,V>)p).putTreeVal(this,?tab,?hash,?key,?value);
????????????else?{
????????????????for?(int?binCount?=?0;?;?++binCount)?{
????????????????????if?((e?=?p.next)?==?null)?{
????????????????????????p.next?=?newNode(hash,?key,?value,?null);
????????????????????????if?(binCount?>=?TREEIFY_THRESHOLD?-?1)?//?-1?for?1st
????????????????????????????treeifyBin(tab,?hash);
????????????????????????break;
????????????????????}
????????????????????if?(e.hash?==?hash?&&
????????????????????????((k?=?e.key)?==?key?||?(key?!=?null?&&?key.equals(k))))
????????????????????????break;
????????????????????p?=?e;
????????????????}
????????????}
????????????if?(e?!=?null)?{?//?existing?mapping?for?key
????????????????V?oldValue?=?e.value;
????????????????if?(!onlyIfAbsent?||?oldValue?==?null)
????????????????????e.value?=?value;
????????????????afterNodeAccess(e);
????????????????return?oldValue;
????????????}
????????}
????????++modCount;
????????if?(++size?>?threshold)
????????????resize();
????????afterNodeInsertion(evict);
????????return?null;
????}
????/**
?????*?继承于?Map.put.
?????*
?????*?@param?hash?key的hash值
?????*?@param?key?key
?????*?@param?value?要输入的值
?????*?@param?onlyIfAbsent?如果是?true,?不改变存在的值
?????*?@param?evict?if?false,?the?table?is?in?creation?mode.
?????*?@return?返回当前值,?当前值不存在返回null
?????*/
static?class?Node<K,V>?implements?Map.Entry<K,V>?{
????????final?int?hash;
????????final?K?key;
????????V?value;
????????Node<K,V>?next;
????????Node(int?hash,?K?key,?V?value,?Node<K,V>?next)?{
????????????this.hash?=?hash;
????????????this.key?=?key;
????????????this.value?=?value;
????????????this.next?=?next;
????????}
}


更多精彩推荐
?“抗疫”新战术:世卫组织联合IBM、甲骨文、微软构建了一个开放数据的区块链项目!
?原来疫情发生后,全球加密社区为了抗击冠状病毒做了这么多事情!

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 程序人生
程序人生
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675