出品 | AI科技大本营(ID:rgznai100)
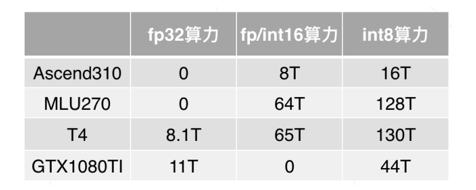
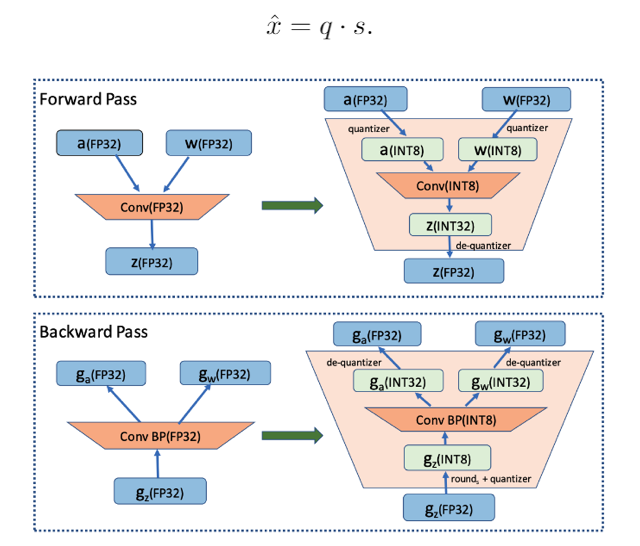
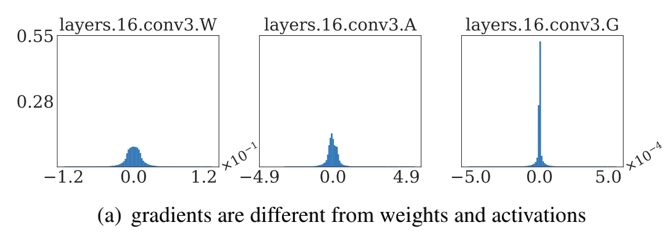
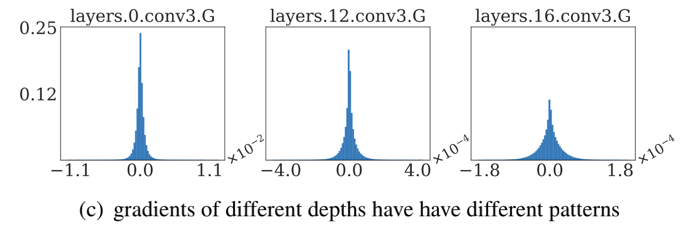
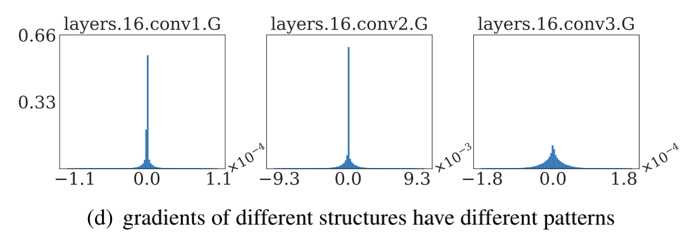
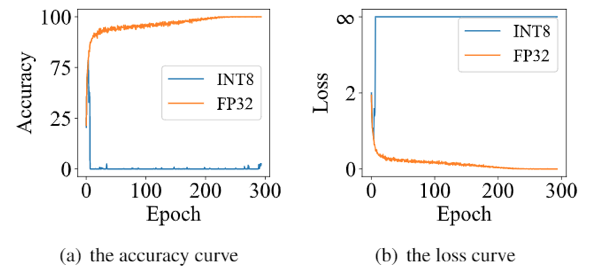
在CVPR 2020上,商汤研究院链接与编译团队、高性能计算团队和北航刘祥龙老师团队合作提出了用于加速卷积神经网络训练过程的INT8训练技术。该工作通过将网络的输入、权重和梯度量化到8比特来加速网络的前向传播和反向传播过程,缩短卷积神经网络训练时间。论文观察到梯度的独特分布给量化训练带来了极大挑战,为了解决梯度量化带来的精度损失和不稳定问题,该论文进行了量化训练收敛稳定性的理论分析并基于此提出了误差敏感的学习率调节和基于方向自适应的梯度截断方法。同时为了保证更高的加速比,该论文还提出使用周期更新、量化卷积融合等技术来减少量化操作带来的时间开销。应用了上述方法之后,INT8训练在图像分类任务和检测任务上都仅仅损失微小的精度,且训练过程相比浮点训练加速了22%。卷积神经网络被广泛应用在多种计算机视觉任务中并且取得了优异的精度。由于拥有庞大的参数量,训练和部署卷积神经网络需要耗费大量计算资源和漫长的训练时间,如何用更少资源训练卷积神经网络一直是一个学术研究热点,也是工业界关心的话题。神经网络量化技术是一种使用定点计算代替浮点的加速技术,目前被广泛地应用在神经网络部署中,可以极大地提升部署速度,并降低内存资源占用。现有很多工作均表明将网络前向过程的浮点计算替换成INT8计算,不会带来明显的精度下降[1][2]。下图展示了现代神经网络加速芯片对于不同精度计算的理论计算峰值对比,可以看到,INT8算力相比于FP32和FP/INT16均能有超过2倍峰值性能提升。当考虑将神经网络量化技术应用在卷积神经网络训练中时,为了加速卷积的反向梯度传播过程,不得不对梯度进行量化操作。在将浮点的梯度量化到INT8数值范围内之后,训练过程变得极其不稳定,并且收敛到非常差的精度。如何解决量化梯度给训练带来的收敛稳定性问题,是十分重要的问题。与此同时,在提升训练精度的同时,也不应当进入过多额外的计算,否则加速效果将会大打折扣。一方面是高效的计算峰值保障,一方面是困难重重的算法设计,这是INT8训练技术的机遇与挑战。标准的线性量化操作指的是,将一个浮点张量(tensor)进行线性映射,变换到整数空间中[3]。这个整数空间的大小由于量化比特数来决定,比如常见的8bit量化数,就有256个取值,本文中使用的是对称量化,因此量化数的取值是从-128到127。具体公式如下,其中x是被量化的数据,q是量化后的数据,s是量化系数,clip是截断函数:在8bit的场景里,截断函数和量化系数的计算公式如下:为了降低量化带来的误差,一个常见做法是对取整过程进行随机化,使得取整函数从期望上更接近原始的数,具体随机取整的公式如下:相反的,将8bit量化数变换回浮点的过程称之为反量化。反量化公式如下所示,其中q为量化计算结果,s为量化系数,为反量化后的结果。上图的上半部分展示了标准的卷积神经网络量化计算前向过程,该过程被广泛应用在INT8部署加速中。在卷积计算之前,量化器会对输入和权重进行量化操作,将浮点数量化到8bit数值上,通过INT8卷积计算核心,即可完成一次INT8前向计算,最终将求和得到的32bit数进行反量化操作回算到浮点数域中,以供给下一层计算使用。INT8训练的一个核心的加速点在于卷积计算的反向过程,上图展示了INT8训练中卷积计算在反向传播过程中的计算细节。在卷积的反向梯度传播过程,同样的将梯度进行浮点量化操作,不过为了降低量化的误差,针对梯度的量化采用了随机取整操作。通过INT8的反向卷积计算核心,可以得到下一层所需的回传梯度,以及当前层的权重所需的梯度。由于INT8反向卷积输出的是32bit数,与前传类似,需要引入一次反量化操作,将32bit数反算回到浮点数域中。为什么对梯度进行量化会给网络训练带来如此大的影响?我们可以观察训练过程中的梯度分布情况来进一步的分析。通过图(a)中对比梯度和输入、权重的分布,可以发现:梯度分布相比输入和权重分布更加尖锐,同时范围更大。相比于输入和权重,梯度有更多的值集中在0附近,但同时梯度还有许多较大值,让梯度的分布范围变得相当广,这些特征都会导致梯度量化的量化误差比输入和权重更大。图(b)展示的是layers16随着训练,其梯度从epoch 0到epoch 300的变化情况。从中可以看出,随着训练的进行,梯度分布越变得更加尖锐,同时仍然保持着较广的分布范围,这意味着梯度量化的误差会随着训练的进行变得越来越大。梯度的分布随网络深度变化情况从图(c)中可以看出。很容易发现,卷积层的深度越浅,梯度分布越尖锐,这也会导致梯度量化的误差更大。从图(d)中可以看出卷积的结构也会影响梯度分布,对于MobileNetV2来说,conv2为depthwise卷积其相比conv1和conv3具有更加尖锐的分布。由于卷积神经网络的梯度具有如上四个特点,所以当我们直接在训练中对梯度进行量化时,训练精度非常容易出现突发的崩溃情况。下图展示了在CIFAR-10数据集上进行实验的精度和损失函数变化曲线,以MobileNetv2在CIFAR-10数据集上训练为例,其训练的精度曲线和loss曲线如下图,从图中可以发现INT8训练的loss在训练初期正常下降,但随后迅速上升,对应的精度也不断下降。根据以上的观察和初步启发,我们希望通过理论的分析和推导,对量化训练的收敛稳定性进行建模。根据Adam等相关论文的经验和优化理论中的Regret analysis,不失一般性地定义R(T)为其中f是损失函数,t是训练轮数,T是训练总轮数,为t轮的权重,是最优权重。其中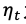 为t轮的学习率,d为权重的维度,
为t轮的学习率,d为权重的维度,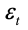 为t轮的量化误差,
为t轮的量化误差,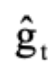 是t轮的量化后梯度。为了确保网络能够稳定收敛,
是t轮的量化后梯度。为了确保网络能够稳定收敛,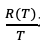 在T变大时需要能够达到足够小。通过上式可以发现,在T趋于无穷大时,第(1)项可以忽略不计,主要考虑减小第(2)项和第(3)项。我们发现,第(2)项与量化误差正相关,第(3)项与学习率以及量化后的梯度大小有关。因此我们不难得到两个直观的提升训练收敛稳定性的策略:
在T变大时需要能够达到足够小。通过上式可以发现,在T趋于无穷大时,第(1)项可以忽略不计,主要考虑减小第(2)项和第(3)项。我们发现,第(2)项与量化误差正相关,第(3)项与学习率以及量化后的梯度大小有关。因此我们不难得到两个直观的提升训练收敛稳定性的策略:通过调节量化函数中的截断减小量化误差
通过适当调低学习率来提高量化训练精度
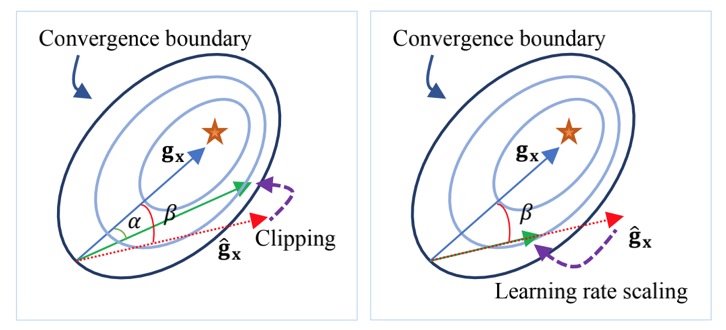
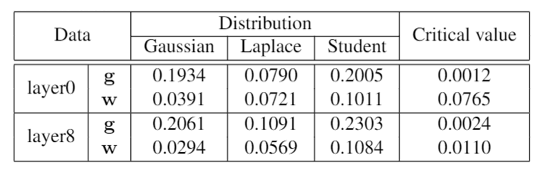
依据以上分析,我们针对量化误差和学习率提出了基于方向自适应的梯度截断和误差敏感的学习率调节两个方法来解决量化训练带来的精度损失问题。同时,为了减少量化操作带来的额外开销,本文还提出了周期更新和量化卷积融合的方法。1、基于方向自适应的梯度截断:调整截断值,让梯度方向保持正确为了最小化量化误差,之前有很多研究提出优化截断值的方法,其中就有研究提出通过假设数据分布直接求解最优截断值。但是已有的研究都针对于权重量化的截断值进行优化。就如本文观察所显示,梯度的分布特征与权重区别较大,无法直接使用。本文通过KS检验发现梯度的分布并不符合常见的高斯分布、拉普拉斯分布和学生t分布,因此很难通过假设梯度分布来直接求解最优的截断值。基于以上的分析,本文采用梯度下降的方法来自适应地学习最优截断值,常见的目标函数有均方误差函数,但是由于梯度的分布特征,均方误差的大小会受到梯度的影响,影响优化过程;同时对于梯度来说,均方误差并不能很好地体现梯度的量化误差对于优化过程的影响,因此本文提出使用能够体现梯度方向的余弦距离来衡量梯度的量化误差,并以余弦距离为目标函数来优化求解最优截断值。余弦距离定义如下:其中,g是梯度,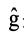 是量化后的梯度。2、误差敏感的学习率调节:在错误的方向上尽量少更新根据上述的理论分析,降低学习率能够有助于模型量化训练的收敛。针对学习率的调整,本文提出误差敏感的学习率调节方法,使用学习率系数对原学习率进行调整,学习率系数与余弦距离
是量化后的梯度。2、误差敏感的学习率调节:在错误的方向上尽量少更新根据上述的理论分析,降低学习率能够有助于模型量化训练的收敛。针对学习率的调整,本文提出误差敏感的学习率调节方法,使用学习率系数对原学习率进行调整,学习率系数与余弦距离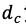 负相关,学习率系数
负相关,学习率系数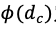 定义如下:其中
定义如下:其中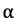 和
和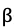 是超参数,用于控制衰减程度和调节下界。由于量化操作需要的统计数据范围和计算截断值等操作十分耗时,为了减少这些操作的时间开销,本文采用周期更新的方式,周期性地统计数据范围和计算截断值。通过周期更新的方法能够有效地提高减少因量化引入的额外时间开销。下表为ResNet50在ImageNet数据集上不同周期的单次训练时间统计表。4、量化卷积融合:减少访存次数、节省cuda kernel launch次数通过将量化和反量化操作融合入卷积计算的CUDA核函数里,可以减少一次数据的访存,有效地减少量化和反量化操作的时间开销。图像分类任务:本文在CIFAR10和ImageNet等图像分类数据集进行INT8训练实验。从下表结果中可以看出,在大多数网络结构中均取得了比现有最好方法更优的精度,并且首次在MobileNet、Inception等网络上进行量化训练实验,精度损失也在1.5%以内。目标检测任务:同时,本文也首次尝试在PASCAL和COCO等目标检测数据集上进行INT8训练实验,精度损失也在2%以内。
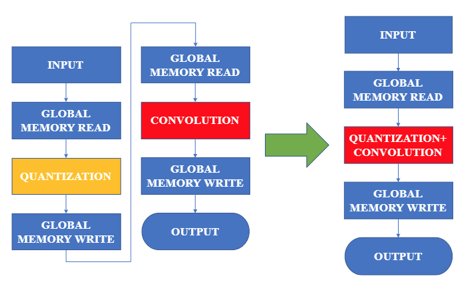
是超参数,用于控制衰减程度和调节下界。由于量化操作需要的统计数据范围和计算截断值等操作十分耗时,为了减少这些操作的时间开销,本文采用周期更新的方式,周期性地统计数据范围和计算截断值。通过周期更新的方法能够有效地提高减少因量化引入的额外时间开销。下表为ResNet50在ImageNet数据集上不同周期的单次训练时间统计表。4、量化卷积融合:减少访存次数、节省cuda kernel launch次数通过将量化和反量化操作融合入卷积计算的CUDA核函数里,可以减少一次数据的访存,有效地减少量化和反量化操作的时间开销。图像分类任务:本文在CIFAR10和ImageNet等图像分类数据集进行INT8训练实验。从下表结果中可以看出,在大多数网络结构中均取得了比现有最好方法更优的精度,并且首次在MobileNet、Inception等网络上进行量化训练实验,精度损失也在1.5%以内。目标检测任务:同时,本文也首次尝试在PASCAL和COCO等目标检测数据集上进行INT8训练实验,精度损失也在2%以内。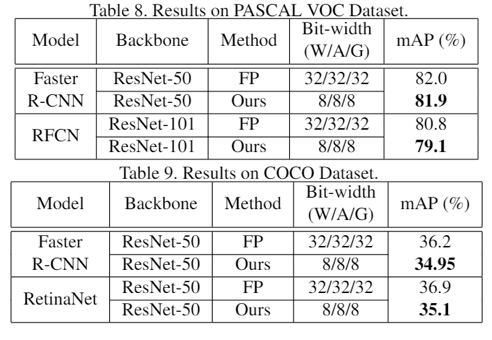 ?已有的少量探究梯度量化的论文[4]均未报告算法在实际训练任务中的真实加速性能,为了最大限度将方法实用化,本文在 GeForce GTX1080TI显卡上编写并优化了用于支持INT8训练的卷积前向和后向计算核心。实测结果表明,使用INT8卷积计算的前向和后向过程相比于浮点计算有明显的加速,其中前向过程平均加速1.63倍,后向过程平均加速1.94倍。如下图所示:同时,本文在实际训练过程中进行了完整的端到端测试,可以看到,INT8训练可以将ResNet50的一轮训练过程从0.360秒降低到0.293秒,整体训练过程提速了22%。https://arxiv.org/pdf/1912.12607.pdf?[1].Ruihao Gong, Xianglong Liu, Shenghu Jiang, Tianxiang Li,Peng Hu, Jiazhen Lin, Fengwei Yu, and Junjie Yan. Differen-tiable soft quantization:? Bridging full-precision and low-bitneural networks. In ICCV, October 2019.[2].Rundong Li, Yan Wang, Feng Liang, Hongwei Qin, Junjie Yan, and Rui Fan. Fully quantized network for object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.[3].?? Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. 2018 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 2018.[4].? ?Yukuan Yang, Shuang Wu, Lei Deng, Tianyi Yan, Yuan Xie, and Guoqi Li. Training high-performance and large-scale deep neural networks with full 8-bit integers, 2019.
?已有的少量探究梯度量化的论文[4]均未报告算法在实际训练任务中的真实加速性能,为了最大限度将方法实用化,本文在 GeForce GTX1080TI显卡上编写并优化了用于支持INT8训练的卷积前向和后向计算核心。实测结果表明,使用INT8卷积计算的前向和后向过程相比于浮点计算有明显的加速,其中前向过程平均加速1.63倍,后向过程平均加速1.94倍。如下图所示:同时,本文在实际训练过程中进行了完整的端到端测试,可以看到,INT8训练可以将ResNet50的一轮训练过程从0.360秒降低到0.293秒,整体训练过程提速了22%。https://arxiv.org/pdf/1912.12607.pdf?[1].Ruihao Gong, Xianglong Liu, Shenghu Jiang, Tianxiang Li,Peng Hu, Jiazhen Lin, Fengwei Yu, and Junjie Yan. Differen-tiable soft quantization:? Bridging full-precision and low-bitneural networks. In ICCV, October 2019.[2].Rundong Li, Yan Wang, Feng Liang, Hongwei Qin, Junjie Yan, and Rui Fan. Fully quantized network for object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.[3].?? Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. 2018 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), June 2018.[4].? ?Yukuan Yang, Shuang Wu, Lei Deng, Tianyi Yan, Yuan Xie, and Guoqi Li. Training high-performance and large-scale deep neural networks with full 8-bit integers, 2019.
欢迎所有开发者扫描下方二维码填写《开发者与AI大调研》,只需2分钟,便可收获价值299元的「AI开发者万人大会」在线直播门票!

推荐阅读
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





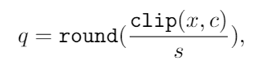
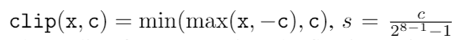
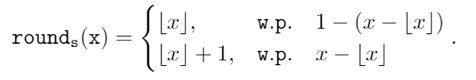



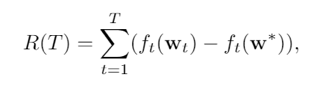
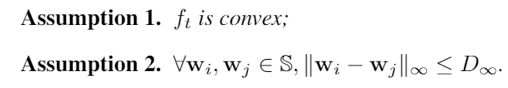
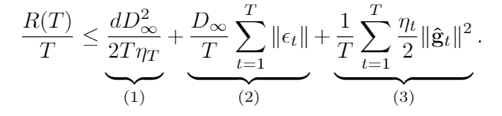

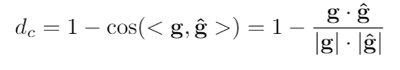
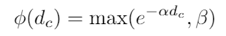








![王姿允 #来卖个萌吧# 熊熊控都给我出来[哇] ](https://imgs.knowsafe.com:8087/img/aideep/2023/11/1/63e90db3799f7eb54376aba829e1ccf4.jpg?w=250)


 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




