
首次揭秘!大麦如何应对超大规模高性能选座抢票?


作者| ?阿里文娱技术专家恒磊、高级开发工程师新钱
出品 | AI科技大本营(ID:rgznai100)
?

背景介绍
随着现场娱乐行业的不断发展,各类演出层出不穷,越来越多的演出开启选座购票满足用 户的自主选座需求。大麦的选座不仅面向中小场馆类的剧院演出,还面向大型体育赛事、大型 演唱会等超大型场馆(如鸟巢近 10 万座)。
选座类型抢票的特点是“选”,由于“选”的可视化以 及超大场馆在数据量上对大麦是很大的挑战。本文通过服务端和前端上的一些解决方案来探讨 如何支撑超大规模场馆的高性能选座,通过本文的一些技术方案希望可以对读者在一些高并发 实践中提供帮助。
?

核心问题
首先看一下普通商品的秒杀,拿某款手机秒杀来说,一般情况下,一场手机只有几个型号, 比如中低档、高性能档、旗舰等,处理好这几个商品的库存即可。对于选座类抢票而言,每一 个场次的所有的每一个座位都可以认为是一个不同的商品,场馆大小不一,大的鸟巢有 10w 座 位。也即是说一个选座类抢票就涉及 10 万级别的商品,如果多个项目同时开抢,整体数量会很 庞大。目前大麦电商侧的商品维度是票档,座位并不是商品粒度,所以无法利用集团的秒杀能 力,选座类抢票涉及电商、选座、票务云产销,是对大麦整体能力的考验。
先来看看整个选座购票的流程:以林俊杰长沙测试项目购票为例。
1、用户打开需要的场次项目详情页
?
?
2、点击选座购买,打开选座页面,查看座位图及票档
?
?
?
3、选择一个看台区域,选择喜欢的座位,点击确认选座
?
? ? ? ? ? ? ?
? ? ?
4、进入下单页面,填写手机号收货地址,创建订单
?
? ? ? ? ? ? ?
? ? ?
?
5、提交订单完成付款、出票。其中,2、3、4 环节都与选座相关。从流程上看,选座的核心关键技术在于:
座位图的快速加载。快速加载其实就是选座页面的读能力。选座页面需要下载座位底图、 座位基础信息(排号等等)来做渲染,同时需要票档、该场次每个座位的状态,来决定是可售还是锁定还是已经售出。对于大型场馆座位 5 万-10 万,渲染一个选座页面需要的数据量都很大;
高并发。由于热门演出票的稀缺性,同时抢票的人数可能达到几十万。如何支撑如此高 的并发和吞吐是一大考验;
座位状态更新的及时性 当某个座位售出后,需要及时更新座位状态;
抢票体验:抢票时热门的看台某个座位可能几十个人并发去抢,如何尽量提升用户的体 验,尽量让更多用户一次性购买成功,体验更好。

高性能选座实践
针对高性能选座的核心要求,我们从如下几个维度去阐述我们在选座类抢票上的实践。
?
1. 动静结合
选座的瓶颈数据量“首当其冲”。从逻辑上讲,一个座位完整的展现到用户面前,需要包含 座位的看台、排号、价格、售卖状态等信息,其中 看台、排号等等是不变的,并可提前预知的;售卖状态等时根据项目的进行会动态变化的。所以把选座的数据拆分为动态、静态数据。对于 大型场馆如 10 万场馆,用户打开一个选座页,座位的静态数据(座位 id,票价 id,是否固定套 票,坐标 x,y,和舞台角度,哪个看台,几排几号等等),这些数据大概 15M 左右。再加上动 态数据如票档状态、颜色、看台状态、座位状态,10w 场馆大概 2M 左右。
也就是说,如果不做处理用户仅仅打开选座页就需要 17M 以上的数据量。如果选座数据存储在 oss 上,如果每人下 载 15M,10w 人同时抢票则需要 1500G 带宽,带宽成本很高。为了解决静态文件访问速度问题, 将静态数据从 oss 直接接入到 cdn。同时为了保障数据最新,静态数据采用版本控制。
2. 静态数据的预加载
上面提到带宽峰值很高,为了降低峰值且提升体验,客户端引入了静态数据预加载。静态 信息结合预加载的处理,为处理大数据量的座位信息提供了时间上的余量,用户在打开选座页 时优先显示静态信息,可有效降低用户等待时间,提升用户的体验。
通过大数据分析结合用户的行为习惯,确定预加载的场次类型,提高预加载的命中率。
?
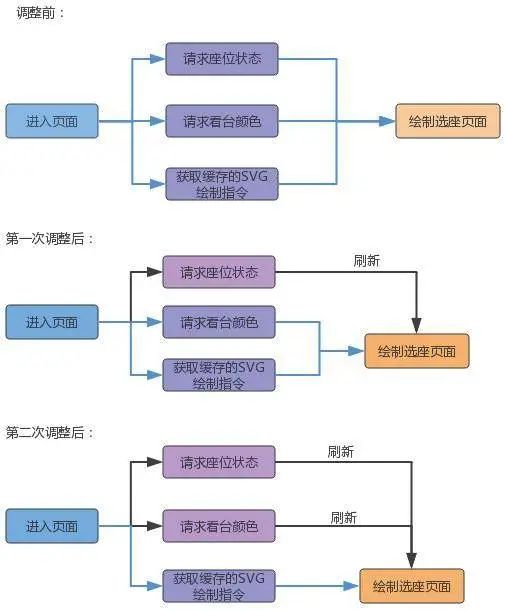
图 2.1:预加载调整流程
?
预加载+预解析,完成了绘制基本场馆信息的数据准备,再将数据提前与画座 View 绑定, 预渲染 View 进而达到选座页秒开效果。
3. 座位数据编码
动态、静态数据量大制约了我们实现高吞吐,同时也浪费了服务带宽和用户流量。所以需 要压缩,压缩到一定的可接受的范围。只有数据量足够小,才有办法做到高吞吐。
1)静态数据编码
在处理大数据量的座位(例如十万级)仅有静态数据的预加载往往是不足的,预加载并没有从根本上处理座位数据量大的问题,同时对于类似体育比赛这种多日期多场次的场景,由于预加载的使用存在缓存量的控制,往往影响预加载的命中率。而数据重编码和数据压缩的使用,是从源头解决问题的有效思路。
座位数据的重编,舍弃传统的 xml 和 json 格式,不仅可以有效压缩数据大小,还对数据安 全提供了保障,即使被拿到了接口数据,因为缺乏数据编码的协议,也无法获取有效的原始信息。
2)座位静态数据压缩整体框架
目前大麦针对自己特有的座位数据特点,结合高效二进制编码方案进行座位数据的重新编码,再使用通用的无损压缩进一步缩小数据体积,从而减少了座位数据的网络传输时间,从根本上解决大数据传输导致的时延问题:
?
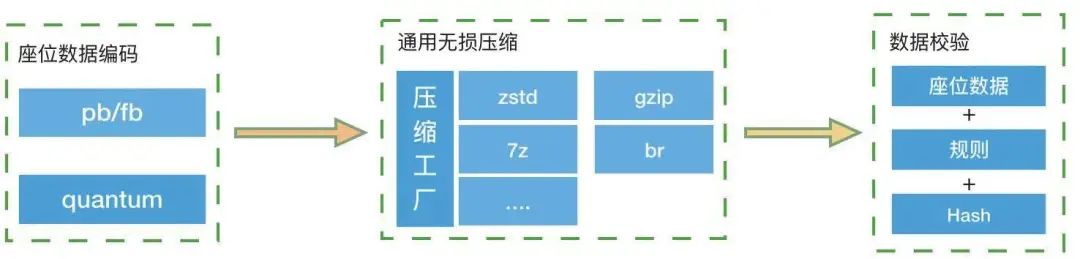
图 3.1:静态数据压缩流程
?
基于二进制的数据编码,既保障了数据安全性,又保证了在数据解析中的高效性,即使数 据压缩的使用也比 json、xml 的解析具有更少的时延。同时兼具工具化的批量生产方式,又进一步解决了数据构建问题。
? ? ? ?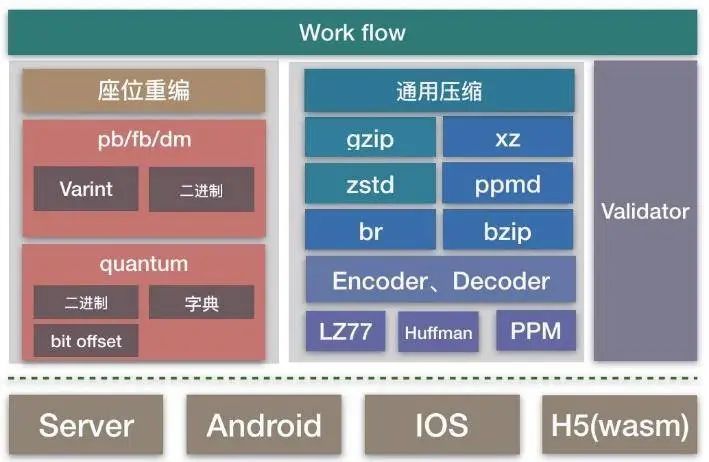 ? ? ?
? ? ?
图 3.2:静态数据压缩工具架构
?
通过端上和 server 端的握手协商过程,实现了数据编码和通用压缩方式灵活组合,sever 端 可以针对不同的端下发相应的压缩格式文件:
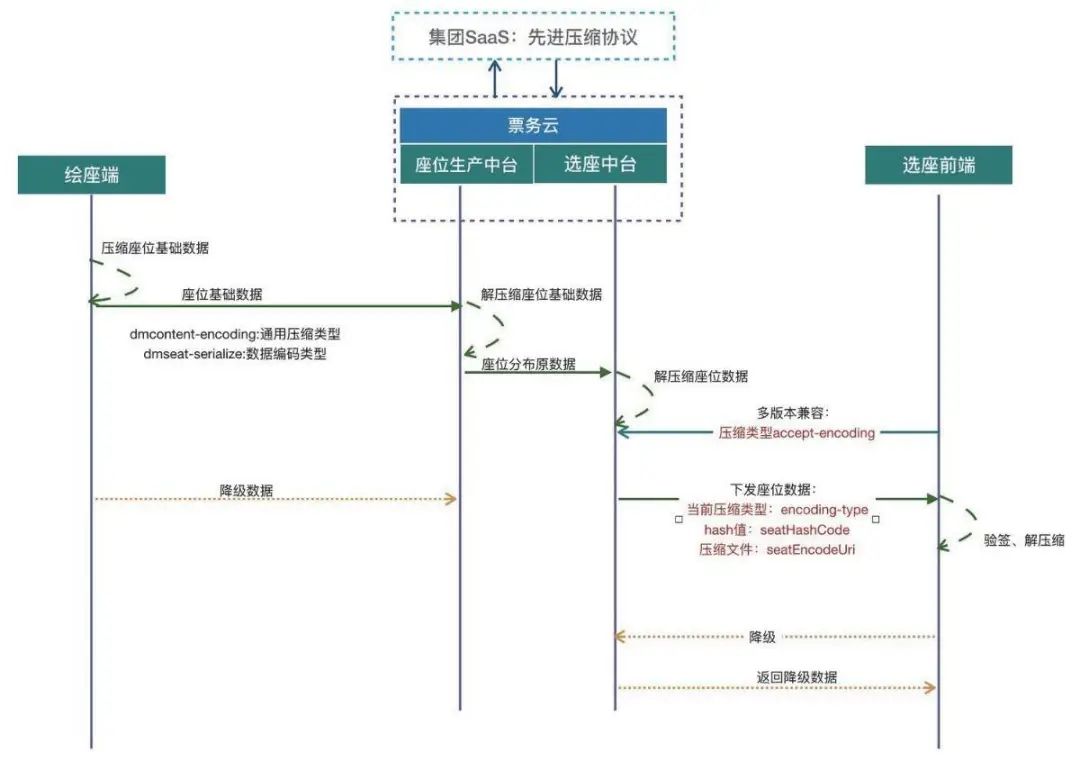
图 3.3:静态数据压缩,握手协商工作流
?
结合 CRC 的思想,制定了兼容 IOS、Android 和 H5 三端的基于座位属性的纵向 hash 校验。相比 md5 等普通的散列计算方式,在处理 6 万级座位多维度信息时,在端上实现了十几毫秒、 H5 侧 50 毫秒左右的全量数据检测,使得在不占用多长时间的情况,可以验证数万级座位解析 的准确性。经过这编码到检测的完整链路,实现了减少数据的体积的同时,又能达到比传统 xml 和 json数据的高效解析、高安全性。
?
?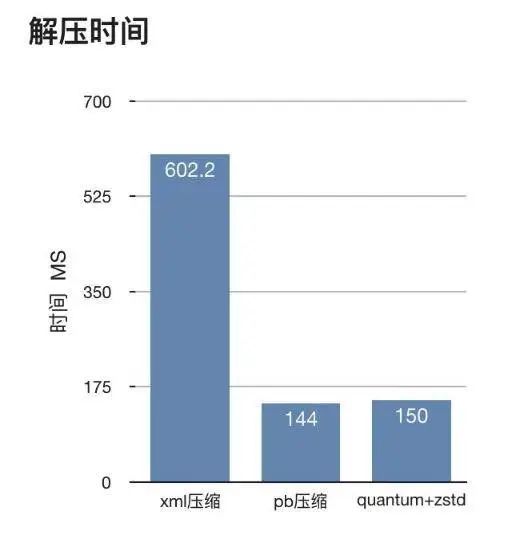 ? ?
? ?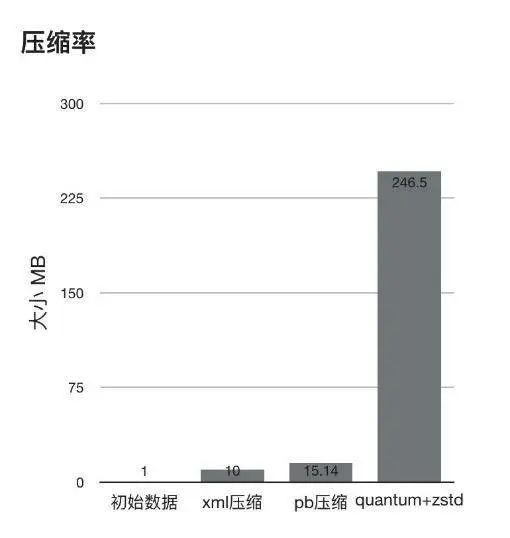
图 3.3: 压缩数据对比
?
其中 quantum 是大麦端上自研的基于动态比特和字典的压缩算法,结合大麦特有业务场景, 实现了高压缩比和快速数据解析:
?
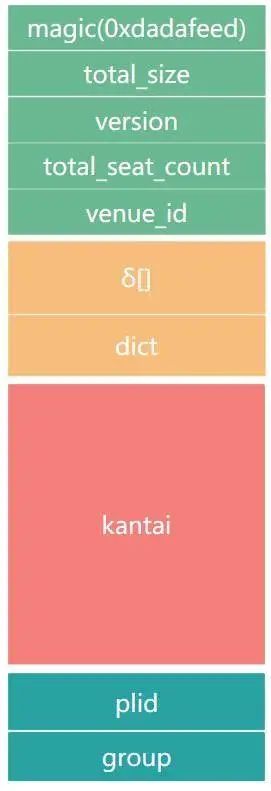
图 3.4: quantum 压缩文件结构
?
3)座位动态数据的编码处理
a)动态数据的难点
选座动态接口主要涉及票档情况、看台情况、座位状态。数据量最大的是座位状态。以一 个 5 万座位的场馆为例,每个座位都要返回一个状态供前端渲染。采用座位 id 和状态键值对的 方式,由于座位较多使得整个返回结果过大,5 万座位的场馆返回 1M 以上的数据。
如果打开 一个选座页需要吞吐 1M 数据量的化,接口基本不可用了。之前的策略是按照分组策略,5 万 大概会分 10 个组,这样每个请求大概 100k 数据量,这样才能达到接口基本可用,不过端上需 要请求 10 次才能拿到整个场次的状态,可想而知性能会有多大影响。假如 5 万座位的场馆,10 万峰值抢票,那么仅仅这个接口就需要 100 万的 qps,所以肯定会逢抢必挂。
b)方案
目前接口是通过 mtop 协议,我们思考的前提:目前 mtop 不支持 byte[]数组流,只支持 json等格式的字符串结构。如何把返回的数据减小,采用一个尽量简洁的方案,同时调用一次返回 整个场馆座位状态,是我们努力的方向。
数据量大主要是因为有很多冗余的座位 id。有没有办法不依赖这些座位 id?既然我们做的 动静分离,静态数据里已经涵盖了座位 id,我们动态接口里只需要对应的返回状态即可,即按 照静态里面的顺序返回座位状态。同时我们把返回结果进行简单的相邻状态合并将进一步降低 返回结果大小。假设用户选座座位符合正态分布概率,平均长度 5w 座位平均返回不到 20k。
当然如果我们 mtop 协议支持二进制流,那么我们可以用 bit 位进行存储,可以进一步降低 返回结果的大小。
4. 高效缓存
1)缓存
面向这么高的 TPS,tair 是不二首选。采用 tair + ?本地缓存,来支撑如此高的数据峰值。提到 tair,提一下我们这边的一些策略。用户进到选座页是一个个的看台,我们设计了一级 stand ?cache,即看台级别的 cache;用户会进行选座位,我们又加了一级 seat cache,即为座位粒度的 cache。两级 cache 保障用户查看台和用户下单选座都能命中缓存。standcache 是热点 key,从选座的场景是允许数据非准实时 的,所以引入了 tair localcache 和 guava localcache 来增加吞吐,以此降低对 tair 的读压力。
2)保护下游系统
目前采用的策略是 对下游的调用采用加锁,tair 全局锁。拿到锁的才去请求票务云底层数 据。拿到锁的进程去更新 tair 缓存。其实从这里看对 tair 的写还是 qps 比较小的,但是每次争抢 锁对 tair 的读还是不算太小。通过采用本地的锁 + 随机透传来减少 tair 锁耗费的读 qps。为了 对下游依赖做降级,增加了数据快照,每次对下游的调用记录数据快照。当某次调用失败采用 之前的快照进行补偿。
3)保障数据更新及时
由于我们采用了 tair 全局锁,可以按照秒级控制下游调用。调用采用异步触发。最短 1s 内 会触发我们发起对下游的调用。如果我们想最大化利用票务云库存能力,给用户的延迟在 1s 以 内,我们有一些策略。拿到锁的线程 1s 内调用数据更新任务,在数据更新任务里做一些策略, 1s 内是发起 1 次还是多次对票务云的调用,调用越多 tair 更新越及时。由于用户有一定的选座动作,一般情况下 500ms 的延迟用户基本无任何感知的。
4)缓存预热 预热一下缓存,对用户体验和系统性能很有帮助。抢票类项目采用一定的策略做自动化预热。
?
5. 安全及容灾
1)安全
从上文看大麦座位数据做了编码和加密,同时存储路径做了混淆,保障不到开抢时间座位数据无法被破解,保障了选座数据的安全性。此外选座页布局防控策略,保障是真正需要点击座位才能完成下单,防止机刷、防止绕过选座直接下单。通过类似策略降低了选座的无效流量, 提高了稳定性。
2)容灾
选座主要在以下几个方面做了容灾。静态数据存储在 oss 上,目前采用跨地区存储容灾;tair 缓存采用主备缓存,出故障时可以做切换;服务端在 pc 和无线做了集群隔离。
?

总结
本文通过在数据处理、选座性能、缓存等等策略上来阐述了大麦高性能选座上的一些实践。通过这些实践目前大麦可以轻松的承载数十万人的顶级流量的抢票项目。
【end】
欢迎所有开发者扫描下方二维码填写《开发者与AI大调研》,只需2分钟,便可收获价值299元的「AI开发者万人大会」在线直播门票!

推荐阅读
你点的每个“在看”,我都认真当成了AI

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675