“瘦身成功”的ALBERT,能取代BERT吗?
十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
参数比BERT少了80%,性能却提高了。
这就是谷歌去年提出的“瘦身成功版BERT”模型——ALBERT。
这个模型一经发布,就受到了高度关注,二者的对比也成为了热门话题。
而最近,网友Naman Bansal就提出了一个疑问:
是否应该用ALBERT来代替BERT?

能否替代,比比便知。
BERT与ALBERT
BERT模型是大家比较所熟知的。
2018年由谷歌提出,训练的语料库规模非常庞大,包含33亿个词语。

模型的创新点集中在了预训练过程,采用Masked LM和Next Sentence Prediction两种方法,分别捕捉词语和句子级别的表示。
BERT的出现,彻底改变了预训练产生词向量和下游具体NLP任务的关系。
时隔1年后,谷歌又提出ALBERT,也被称作“lite-BERT”,骨干网络和BERT相似,采用的依旧是 Transformer 编码器,激活函数也是GELU。
其最大的成功,就在于参数量比BERT少了80%,同时还取得了更好的结果。
与BERT相比的改进,主要包括嵌入向量参数化的因式分解、跨层参数共享、句间连贯性损失采用SOP,以及移除了dropout。
下图便是BERT和ALBERT,在SQuAD和RACE数据集上的性能测试比较结果。

可以看出,ALBERT性能取得了较好的结果。
如何实现自定义语料库(预训练)ALBERT?
为了进一步了解ALBERT,接下来,将在自定义语料库中实现ALBERT。
所采用的数据集是“用餐点评数据集”,目标就是通过ALBERT模型来识别菜肴的名称。
第一步:下载数据集并准备文件
1#Downlading?all?files?and?data
2
3!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/data_toy/dish_name_train.csv
4!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/data_toy/dish_name_val.csv
5!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/data_toy/restaurant_review.txt
6!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/data_toy/restaurant_review_nopunct.txt
7!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/models_toy/albert_config.json
8!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/model_checkpoint/finetune_checkpoint
9!wget?https://github.com/LydiaXiaohongLi/Albert_Finetune_with_Pretrain_on_Custom_Corpus/raw/master/model_checkpoint/pretrain_checkpoint
10
11#Creating?files?and?setting?up?ALBERT
12
13!pip?install?sentencepiece
14!git?clone?https://github.com/google-research/ALBERT
15!python?./ALBERT/create_pretraining_data.py?--input_file?"restaurant_review.txt"?--output_file?"restaurant_review_train"?--vocab_file?"vocab.txt"?--max_seq_length=64
16!pip?install?transformers
17!pip?install?tfrecord
第二步:使用transformer并定义层
1#Defining?Layers?for?ALBERT
2
3from?transformers.modeling_albert?import?AlbertModel,?AlbertPreTrainedModel
4from?transformers.configuration_albert?import?AlbertConfig
5import?torch.nn?as?nn
6class?AlbertSequenceOrderHead(nn.Module):
7????def?__init__(self,?config):
8????????super().__init__()
9????????self.dense?=?nn.Linear(config.hidden_size,?2)
10????????self.bias?=?nn.Parameter(torch.zeros(2))
11
12????def?forward(self,?hidden_states):
13????????hidden_states?=?self.dense(hidden_states)
14????????prediction_scores?=?hidden_states?+?self.bias
15
16????????return?prediction_scores
17
18from?torch.nn?import?CrossEntropyLoss
19from?transformers.modeling_bert?import?ACT2FN
20class?AlbertForPretrain(AlbertPreTrainedModel):
21
22????def?__init__(self,?config):
23????????super().__init__(config)
24
25????????self.albert?=?AlbertModel(config)???????
26
27????????#?For?Masked?LM
28????????#?The?original?huggingface?implementation,?created?new?output?weights?via?dense?layer
29????????#?However?the?original?Albert?
30????????self.predictions_dense?=?nn.Linear(config.hidden_size,?config.embedding_size)
31????????self.predictions_activation?=?ACT2FN[config.hidden_act]
32????????self.predictions_LayerNorm?=?nn.LayerNorm(config.embedding_size)
33????????self.predictions_bias?=?nn.Parameter(torch.zeros(config.vocab_size))?
34????????self.predictions_decoder?=?nn.Linear(config.embedding_size,?config.vocab_size)
35
36????????self.predictions_decoder.weight?=?self.albert.embeddings.word_embeddings.weight
37
38????????#?For?sequence?order?prediction
39????????self.seq_relationship?=?AlbertSequenceOrderHead(config)
40
41
42????def?forward(
43????????self,
44????????input_ids=None,
45????????attention_mask=None,
46????????token_type_ids=None,
47????????position_ids=None,
48????????head_mask=None,
49????????inputs_embeds=None,
50????????masked_lm_labels=None,
51????????seq_relationship_labels=None,
52????):
53
54????????outputs?=?self.albert(
55????????????input_ids,
56????????????attention_mask=attention_mask,
57????????????token_type_ids=token_type_ids,
58????????????position_ids=position_ids,
59????????????head_mask=head_mask,
60????????????inputs_embeds=inputs_embeds,
61????????)
62
63????????loss_fct?=?CrossEntropyLoss()
64
65????????sequence_output?=?outputs[0]
66
67????????sequence_output?=?self.predictions_dense(sequence_output)
68????????sequence_output?=?self.predictions_activation(sequence_output)
69????????sequence_output?=?self.predictions_LayerNorm(sequence_output)
70????????prediction_scores?=?self.predictions_decoder(sequence_output)
71
72
73????????if?masked_lm_labels?is?not?None:
74????????????masked_lm_loss?=?loss_fct(prediction_scores.view(-1,?self.config.vocab_size)
75??????????????????????????????????????,?masked_lm_labels.view(-1))
76
77????????pooled_output?=?outputs[1]
78????????seq_relationship_scores?=?self.seq_relationship(pooled_output)
79????????if?seq_relationship_labels?is?not?None:??
80????????????seq_relationship_loss?=?loss_fct(seq_relationship_scores.view(-1,?2),?seq_relationship_labels.view(-1))
81
82????????loss?=?masked_lm_loss?+?seq_relationship_loss
83
84????????return?loss
第三步:使用LAMB优化器并微调ALBERT
1#Using?LAMB?optimizer
2#LAMB?-??"https://github.com/cybertronai/pytorch-lamb"
3
4import?torch
5from?torch.optim?import?Optimizer
6class?Lamb(Optimizer):
7????r"""Implements?Lamb?algorithm.
8????It?has?been?proposed?in?`Large?Batch?Optimization?for?Deep?Learning:?Training?BERT?in?76?minutes`_.
9????Arguments:
10????????params?(iterable):?iterable?of?parameters?to?optimize?or?dicts?defining
11????????????parameter?groups
12????????lr?(float,?optional):?learning?rate?(default:?1e-3)
13????????betas?(Tuple[float,?float],?optional):?coefficients?used?for?computing
14????????????running?averages?of?gradient?and?its?square?(default:?(0.9,?0.999))
15????????eps?(float,?optional):?term?added?to?the?denominator?to?improve
16????????????numerical?stability?(default:?1e-8)
17????????weight_decay?(float,?optional):?weight?decay?(L2?penalty)?(default:?0)
18????????adam?(bool,?optional):?always?use?trust?ratio?=?1,?which?turns?this?into
19????????????Adam.?Useful?for?comparison?purposes.
20????..?_Large?Batch?Optimization?for?Deep?Learning:?Training?BERT?in?76?minutes:
21????????https://arxiv.org/abs/1904.00962
22????"""
23
24????def?__init__(self,?params,?lr=1e-3,?betas=(0.9,?0.999),?eps=1e-6,
25?????????????????weight_decay=0,?adam=False):
26????????if?not?0.0?<=?lr:
27????????????raise?ValueError("Invalid?learning?rate:?{}".format(lr))
28????????if?not?0.0?<=?eps:
29????????????raise?ValueError("Invalid?epsilon?value:?{}".format(eps))
30????????if?not?0.0?<=?betas[0]?<?1.0:
31????????????raise?ValueError("Invalid?beta?parameter?at?index?0:?{}".format(betas[0]))
32????????if?not?0.0?<=?betas[1]?<?1.0:
33????????????raise?ValueError("Invalid?beta?parameter?at?index?1:?{}".format(betas[1]))
34????????defaults?=?dict(lr=lr,?betas=betas,?eps=eps,
35????????????????????????weight_decay=weight_decay)
36????????self.adam?=?adam
37????????super(Lamb,?self).__init__(params,?defaults)
38
39????def?step(self,?closure=None):
40????????"""Performs?a?single?optimization?step.
41????????Arguments:
42????????????closure?(callable,?optional):?A?closure?that?reevaluates?the?model
43????????????????and?returns?the?loss.
44????????"""
45????????loss?=?None
46????????if?closure?is?not?None:
47????????????loss?=?closure()
48
49????????for?group?in?self.param_groups:
50????????????for?p?in?group['params']:
51????????????????if?p.grad?is?None:
52????????????????????continue
53????????????????grad?=?p.grad.data
54????????????????if?grad.is_sparse:
55????????????????????raise?RuntimeError('Lamb?does?not?support?sparse?gradients,?consider?SparseAdam?instad.')
56
57????????????????state?=?self.state[p]
58
59????????????????#?State?initialization
60????????????????if?len(state)?==?0:
61????????????????????state['step']?=?0
62????????????????????#?Exponential?moving?average?of?gradient?values
63????????????????????state['exp_avg']?=?torch.zeros_like(p.data)
64????????????????????#?Exponential?moving?average?of?squared?gradient?values
65????????????????????state['exp_avg_sq']?=?torch.zeros_like(p.data)
66
67????????????????exp_avg,?exp_avg_sq?=?state['exp_avg'],?state['exp_avg_sq']
68????????????????beta1,?beta2?=?group['betas']
69
70????????????????state['step']?+=?1
71
72????????????????#?Decay?the?first?and?second?moment?running?average?coefficient
73????????????????#?m_t
74????????????????exp_avg.mul_(beta1).add_(1?-?beta1,?grad)
75????????????????#?v_t
76????????????????exp_avg_sq.mul_(beta2).addcmul_(1?-?beta2,?grad,?grad)
77
78????????????????#?Paper?v3?does?not?use?debiasing.
79????????????????#?bias_correction1?=?1?-?beta1?**?state['step']
80????????????????#?bias_correction2?=?1?-?beta2?**?state['step']
81????????????????#?Apply?bias?to?lr?to?avoid?broadcast.
82????????????????step_size?=?group['lr']?#?*?math.sqrt(bias_correction2)?/?bias_correction1
83
84????????????????weight_norm?=?p.data.pow(2).sum().sqrt().clamp(0,?10)
85
86????????????????adam_step?=?exp_avg?/?exp_avg_sq.sqrt().add(group['eps'])
87????????????????if?group['weight_decay']?!=?0:
88????????????????????adam_step.add_(group['weight_decay'],?p.data)
89
90????????????????adam_norm?=?adam_step.pow(2).sum().sqrt()
91????????????????if?weight_norm?==?0?or?adam_norm?==?0:
92????????????????????trust_ratio?=?1
93????????????????else:
94????????????????????trust_ratio?=?weight_norm?/?adam_norm
95????????????????state['weight_norm']?=?weight_norm
96????????????????state['adam_norm']?=?adam_norm
97????????????????state['trust_ratio']?=?trust_ratio
98????????????????if?self.adam:
99????????????????????trust_ratio?=?1
100
101????????????????p.data.add_(-step_size?*?trust_ratio,?adam_step)
102
103????????return?loss
104
105?import?time
106import?torch.nn?as?nn
107import?torch
108from?tfrecord.torch.dataset?import?TFRecordDataset
109import?numpy?as?np
110import?os
111
112LEARNING_RATE?=?0.001
113EPOCH?=?40
114BATCH_SIZE?=?2
115MAX_GRAD_NORM?=?1.0
116
117print(f"---?Resume/Start?training?---")???
118feat_map?=?{"input_ids":?"int",?
119???????????"input_mask":?"int",
120???????????"segment_ids":?"int",
121???????????"next_sentence_labels":?"int",
122???????????"masked_lm_positions":?"int",
123???????????"masked_lm_ids":?"int"}
124pretrain_file?=?'restaurant_review_train'
125
126#?Create?albert?pretrain?model
127config?=?AlbertConfig.from_json_file("albert_config.json")
128albert_pretrain?=?AlbertForPretrain(config)
129#?Create?optimizer
130optimizer?=?Lamb([{"params":?[p?for?n,?p?in?list(albert_pretrain.named_parameters())]}],?lr=LEARNING_RATE)
131albert_pretrain.train()
132dataset?=?TFRecordDataset(pretrain_file,?index_path?=?None,?description=feat_map)
133loader?=?torch.utils.data.DataLoader(dataset,?batch_size=BATCH_SIZE)
134
135tmp_loss?=?0
136start_time?=?time.time()
137
138if?os.path.isfile('pretrain_checkpoint'):
139????print(f"---?Load?from?checkpoint?---")
140????checkpoint?=?torch.load("pretrain_checkpoint")
141????albert_pretrain.load_state_dict(checkpoint['model_state_dict'])
142????optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
143????epoch?=?checkpoint['epoch']
144????loss?=?checkpoint['loss']
145????losses?=?checkpoint['losses']
146
147else:
148????epoch?=?-1
149????losses?=?[]
150for?e?in?range(epoch+1,?EPOCH):
151????for?batch?in?loader:
152????????b_input_ids?=?batch['input_ids'].long()?
153????????b_token_type_ids?=?batch['segment_ids'].long()?
154????????b_seq_relationship_labels?=?batch['next_sentence_labels'].long()
155
156????????#?Convert?the?dataformat?from?loaded?decoded?format?into?format?
157????????#?loaded?format?is?created?by?google's?Albert?create_pretrain.py?script
158????????#?required?by?huggingfaces?pytorch?implementation?of?albert
159????????mask_rows?=?np.nonzero(batch['masked_lm_positions'].numpy())[0]
160????????mask_cols?=?batch['masked_lm_positions'].numpy()[batch['masked_lm_positions'].numpy()!=0]
161????????b_attention_mask?=?np.zeros((BATCH_SIZE,64),dtype=np.int64)
162????????b_attention_mask[mask_rows,mask_cols]?=?1
163????????b_masked_lm_labels?=?np.zeros((BATCH_SIZE,64),dtype=np.int64)?-?100
164????????b_masked_lm_labels[mask_rows,mask_cols]?=?batch['masked_lm_ids'].numpy()[batch['masked_lm_positions'].numpy()!=0]?????
165????????b_attention_mask=torch.tensor(b_attention_mask).long()
166????????b_masked_lm_labels=torch.tensor(b_masked_lm_labels).long()
167
168
169????????loss?=?albert_pretrain(input_ids?=?b_input_ids
170??????????????????????????????,?attention_mask?=?b_attention_mask
171??????????????????????????????,?token_type_ids?=?b_token_type_ids
172??????????????????????????????,?masked_lm_labels?=?b_masked_lm_labels?
173??????????????????????????????,?seq_relationship_labels?=?b_seq_relationship_labels)
174
175????????#?clears?old?gradients
176????????optimizer.zero_grad()
177????????#?backward?pass
178????????loss.backward()
179????????#?gradient?clipping
180????????torch.nn.utils.clip_grad_norm_(parameters=albert_pretrain.parameters(),?max_norm=MAX_GRAD_NORM)
181????????#?update?parameters
182????????optimizer.step()
183
184????????tmp_loss?+=?loss.detach().item()
185
186????#?print?metrics?and?save?to?checkpoint?every?epoch
187????print(f"Epoch:?{e}")
188????print(f"Train?loss:?{(tmp_loss/20)}")
189????print(f"Train?Time:?{(time.time()-start_time)/60}?mins")??
190????losses.append(tmp_loss/20)
191
192????tmp_loss?=?0
193????start_time?=?time.time()
194
195????torch.save({'model_state_dict':?albert_pretrain.state_dict(),'optimizer_state_dict':?optimizer.state_dict(),
196???????????????'epoch':?e,?'loss':?loss,'losses':?losses}
197???????????,?'pretrain_checkpoint')
198from?matplotlib?import?pyplot?as?plot
199plot.plot(losses)
200
201#Fine?tuning?ALBERT
202
203#?At?the?time?of?writing,?Hugging?face?didnt?provide?the?class?object?for?
204#?AlbertForTokenClassification,?hence?write?your?own?defination?below
205from?transformers.modeling_albert?import?AlbertModel,?AlbertPreTrainedModel
206from?transformers.configuration_albert?import?AlbertConfig
207from?transformers.tokenization_bert?import?BertTokenizer
208import?torch.nn?as?nn
209from?torch.nn?import?CrossEntropyLoss
210class?AlbertForTokenClassification(AlbertPreTrainedModel):
211
212????def?__init__(self,?albert,?config):
213????????super().__init__(config)
214????????self.num_labels?=?config.num_labels
215
216????????self.albert?=?albert
217????????self.dropout?=?nn.Dropout(config.hidden_dropout_prob)
218????????self.classifier?=?nn.Linear(config.hidden_size,?config.num_labels)
219
220????def?forward(
221????????self,
222????????input_ids=None,
223????????attention_mask=None,
224????????token_type_ids=None,
225????????position_ids=None,
226????????head_mask=None,
227????????inputs_embeds=None,
228????????labels=None,
229????):
230
231????????outputs?=?self.albert(
232????????????input_ids,
233????????????attention_mask=attention_mask,
234????????????token_type_ids=token_type_ids,
235????????????position_ids=position_ids,
236????????????head_mask=head_mask,
237????????????inputs_embeds=inputs_embeds,
238????????)
239
240????????sequence_output?=?outputs[0]
241
242????????sequence_output?=?self.dropout(sequence_output)
243????????logits?=?self.classifier(sequence_output)
244
245????????return?logits
246
247import?numpy?as?np
248def?label_sent(name_tokens,?sent_tokens):
249????label?=?[]
250????i?=?0
251????if?len(name_tokens)>len(sent_tokens):
252????????label?=?np.zeros(len(sent_tokens))
253????else:
254????????while?i<len(sent_tokens):
255????????????found_match?=?False
256????????????if?name_tokens[0]?==?sent_tokens[i]:???????
257????????????????found_match?=?True
258????????????????for?j?in?range(len(name_tokens)-1):
259????????????????????if?((i+j+1)>=len(sent_tokens)):
260????????????????????????return?label
261????????????????????if?name_tokens[j+1]?!=?sent_tokens[i+j+1]:
262????????????????????????found_match?=?False
263????????????????if?found_match:
264????????????????????label.extend(list(np.ones(len(name_tokens)).astype(int)))
265????????????????????i?=?i?+?len(name_tokens)
266????????????????else:?
267????????????????????label.extend([0])
268????????????????????i?=?i+?1
269????????????else:
270????????????????label.extend([0])
271????????????????i=i+1
272????return?label
273
274import?pandas?as?pd
275import?glob
276import?os
277
278tokenizer?=?BertTokenizer(vocab_file="vocab.txt")
279
280df_data_train?=?pd.read_csv("dish_name_train.csv")
281df_data_train['name_tokens']?=?df_data_train['dish_name'].apply(tokenizer.tokenize)
282df_data_train['review_tokens']?=?df_data_train.review.apply(tokenizer.tokenize)
283df_data_train['review_label']?=?df_data_train.apply(lambda?row:?label_sent(row['name_tokens'],?row['review_tokens']),?axis=1)
284
285df_data_val?=?pd.read_csv("dish_name_val.csv")
286df_data_val?=?df_data_val.dropna().reset_index()
287df_data_val['name_tokens']?=?df_data_val['dish_name'].apply(tokenizer.tokenize)
288df_data_val['review_tokens']?=?df_data_val.review.apply(tokenizer.tokenize)
289df_data_val['review_label']?=?df_data_val.apply(lambda?row:?label_sent(row['name_tokens'],?row['review_tokens']),?axis=1)
290
291MAX_LEN?=?64
292BATCH_SIZE?=?1
293from?keras.preprocessing.sequence?import?pad_sequences
294import?torch
295from?torch.utils.data?import?TensorDataset,?DataLoader,?RandomSampler,?SequentialSampler
296
297tr_inputs?=?pad_sequences([tokenizer.convert_tokens_to_ids(txt)?for?txt?in?df_data_train['review_tokens']],maxlen=MAX_LEN,?dtype="long",?truncating="post",?padding="post")
298tr_tags?=?pad_sequences(df_data_train['review_label'],maxlen=MAX_LEN,?padding="post",dtype="long",?truncating="post")
299#?create?the?mask?to?ignore?the?padded?elements?in?the?sequences.
300tr_masks?=?[[float(i>0)?for?i?in?ii]?for?ii?in?tr_inputs]
301tr_inputs?=?torch.tensor(tr_inputs)
302tr_tags?=?torch.tensor(tr_tags)
303tr_masks?=?torch.tensor(tr_masks)
304train_data?=?TensorDataset(tr_inputs,?tr_masks,?tr_tags)
305train_sampler?=?RandomSampler(train_data)
306train_dataloader?=?DataLoader(train_data,?sampler=train_sampler,?batch_size=BATCH_SIZE)
307
308
309val_inputs?=?pad_sequences([tokenizer.convert_tokens_to_ids(txt)?for?txt?in?df_data_val['review_tokens']],maxlen=MAX_LEN,?dtype="long",?truncating="post",?padding="post")
310val_tags?=?pad_sequences(df_data_val['review_label'],maxlen=MAX_LEN,?padding="post",dtype="long",?truncating="post")
311#?create?the?mask?to?ignore?the?padded?elements?in?the?sequences.
312val_masks?=?[[float(i>0)?for?i?in?ii]?for?ii?in?val_inputs]
313val_inputs?=?torch.tensor(val_inputs)
314val_tags?=?torch.tensor(val_tags)
315val_masks?=?torch.tensor(val_masks)
316val_data?=?TensorDataset(val_inputs,?val_masks,?val_tags)
317val_sampler?=?RandomSampler(val_data)
318val_dataloader?=?DataLoader(val_data,?sampler=val_sampler,?batch_size=BATCH_SIZE)
319
320model_tokenclassification?=?AlbertForTokenClassification(albert_pretrain.albert,?config)
321from?torch.optim?import?Adam
322LEARNING_RATE?=?0.0000003
323FULL_FINETUNING?=?True
324if?FULL_FINETUNING:
325????param_optimizer?=?list(model_tokenclassification.named_parameters())
326????no_decay?=?['bias',?'gamma',?'beta']
327????optimizer_grouped_parameters?=?[
328????????{'params':?[p?for?n,?p?in?param_optimizer?if?not?any(nd?in?n?for?nd?in?no_decay)],
329?????????'weight_decay_rate':?0.01},
330????????{'params':?[p?for?n,?p?in?param_optimizer?if?any(nd?in?n?for?nd?in?no_decay)],
331?????????'weight_decay_rate':?0.0}
332????]
333else:
334????param_optimizer?=?list(model_tokenclassification.classifier.named_parameters())?
335????optimizer_grouped_parameters?=?[{"params":?[p?for?n,?p?in?param_optimizer]}]
336optimizer?=?Adam(optimizer_grouped_parameters,?lr=LEARNING_RATE)
第四步:为自定义语料库训练模型
1#Training?the?model
2
3#?from?torch.utils.tensorboard?import?SummaryWriter
4import?time
5import?os.path
6import?torch.nn?as?nn
7import?torch
8EPOCH?=?800
9MAX_GRAD_NORM?=?1.0
10
11start_time?=?time.time()
12tr_loss,?tr_acc,?nb_tr_steps?=?0,?0,?0
13eval_loss,?eval_acc,?nb_eval_steps?=?0,?0,?0
14
15if?os.path.isfile('finetune_checkpoint'):
16????print(f"---?Load?from?checkpoint?---")
17????checkpoint?=?torch.load("finetune_checkpoint")
18????model_tokenclassification.load_state_dict(checkpoint['model_state_dict'])
19????optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
20????epoch?=?checkpoint['epoch']
21????train_losses?=?checkpoint['train_losses']
22????train_accs?=?checkpoint['train_accs']
23????eval_losses?=?checkpoint['eval_losses']
24????eval_accs?=?checkpoint['eval_accs']
25
26else:
27????epoch?=?-1
28????train_losses,train_accs,eval_losses,eval_accs?=?[],[],[],[]
29
30print(f"---?Resume/Start?training?---")????
31for?e?in?range(epoch+1,?EPOCH):?
32
33????#?TRAIN?loop
34????model_tokenclassification.train()
35
36????for?batch?in?train_dataloader:
37????????#?add?batch?to?gpu
38????????batch?=?tuple(t?for?t?in?batch)
39????????b_input_ids,?b_input_mask,?b_labels?=?batch
40????????#?forward?pass
41????????b_outputs?=?model_tokenclassification(b_input_ids,?token_type_ids=None,?attention_mask=b_input_mask,?labels=b_labels)
42
43????????ce_loss_fct?=?CrossEntropyLoss()
44????????#?Only?keep?active?parts?of?the?loss
45????????b_active_loss?=?b_input_mask.view(-1)?==?1
46????????b_active_logits?=?b_outputs.view(-1,?config.num_labels)[b_active_loss]
47????????b_active_labels?=?b_labels.view(-1)[b_active_loss]
48
49????????loss?=?ce_loss_fct(b_active_logits,?b_active_labels)
50????????acc?=?torch.mean((torch.max(b_active_logits.detach(),1)[1]?==?b_active_labels.detach()).float())
51
52????????model_tokenclassification.zero_grad()
53????????#?backward?pass
54????????loss.backward()
55????????#?track?train?loss
56????????tr_loss?+=?loss.item()
57????????tr_acc?+=?acc
58????????nb_tr_steps?+=?1
59????????#?gradient?clipping
60????????torch.nn.utils.clip_grad_norm_(parameters=model_tokenclassification.parameters(),?max_norm=MAX_GRAD_NORM)
61????????#?update?parameters
62????????optimizer.step()
63
64
65????#?VALIDATION?on?validation?set
66????model_tokenclassification.eval()
67????for?batch?in?val_dataloader:
68????????batch?=?tuple(t?for?t?in?batch)
69????????b_input_ids,?b_input_mask,?b_labels?=?batch
70
71????????with?torch.no_grad():
72
73????????????b_outputs?=?model_tokenclassification(b_input_ids,?token_type_ids=None,
74?????????????????????????attention_mask=b_input_mask,?labels=b_labels)
75
76????????????loss_fct?=?CrossEntropyLoss()
77????????????#?Only?keep?active?parts?of?the?loss
78????????????b_active_loss?=?b_input_mask.view(-1)?==?1
79????????????b_active_logits?=?b_outputs.view(-1,?config.num_labels)[b_active_loss]
80????????????b_active_labels?=?b_labels.view(-1)[b_active_loss]
81????????????loss?=?loss_fct(b_active_logits,?b_active_labels)
82????????????acc?=?np.mean(np.argmax(b_active_logits.detach().cpu().numpy(),?axis=1).flatten()?==?b_active_labels.detach().cpu().numpy().flatten())
83
84????????eval_loss?+=?loss.mean().item()
85????????eval_acc?+=?acc
86????????nb_eval_steps?+=?1????
87
88????if?e?%?10?==0:
89
90????????print(f"Epoch:?{e}")
91????????print(f"Train?loss:?{(tr_loss/nb_tr_steps)}")
92????????print(f"Train?acc:?{(tr_acc/nb_tr_steps)}")
93????????print(f"Train?Time:?{(time.time()-start_time)/60}?mins")??
94
95????????print(f"Validation?loss:?{eval_loss/nb_eval_steps}")
96????????print(f"Validation?Accuracy:?{(eval_acc/nb_eval_steps)}")?
97
98????????train_losses.append(tr_loss/nb_tr_steps)
99????????train_accs.append(tr_acc/nb_tr_steps)
100????????eval_losses.append(eval_loss/nb_eval_steps)
101????????eval_accs.append(eval_acc/nb_eval_steps)
102
103
104????????tr_loss,?tr_acc,?nb_tr_steps?=?0,?0,?0?
105????????eval_loss,?eval_acc,?nb_eval_steps?=?0,?0,?0?
106????????start_time?=?time.time()?
107
108????????torch.save({'model_state_dict':?model_tokenclassification.state_dict(),'optimizer_state_dict':?optimizer.state_dict(),
109???????????'epoch':?e,?'train_losses':?train_losses,'train_accs':?train_accs,?'eval_losses':eval_losses,'eval_accs':eval_accs}
110???????,?'finetune_checkpoint')
111
112plot.plot(train_losses)
113plot.plot(train_accs)
114plot.plot(eval_losses)
115plot.plot(eval_accs)
116plot.legend(labels?=?['train_loss','train_accuracy','validation_loss','validation_accuracy'])
第五步:预测
1#Prediction
2
3def?predict(texts):
4????tokenized_texts?=?[tokenizer.tokenize(txt)?for?txt?in?texts]
5????input_ids?=?pad_sequences([tokenizer.convert_tokens_to_ids(txt)?for?txt?in?tokenized_texts],
6??????????????????????????????maxlen=MAX_LEN,?dtype="long",?truncating="post",?padding="post")
7????attention_mask?=?[[float(i>0)?for?i?in?ii]?for?ii?in?input_ids]
8
9????input_ids?=?torch.tensor(input_ids)
10????attention_mask?=?torch.tensor(attention_mask)
11
12????dataset?=?TensorDataset(input_ids,?attention_mask)
13????datasampler?=?SequentialSampler(dataset)
14????dataloader?=?DataLoader(dataset,?sampler=datasampler,?batch_size=BATCH_SIZE)?
15
16????predicted_labels?=?[]
17
18????for?batch?in?dataloader:
19????????batch?=?tuple(t?for?t?in?batch)
20????????b_input_ids,?b_input_mask?=?batch
21
22????????with?torch.no_grad():
23????????????logits?=?model_tokenclassification(b_input_ids,?token_type_ids=None,
24???????????????????????????attention_mask=b_input_mask)
25
26????????????predicted_labels.append(np.multiply(np.argmax(logits.detach().cpu().numpy(),axis=2),?b_input_mask.detach().cpu().numpy()))
27????#?np.concatenate(predicted_labels),?to?flatten?list?of?arrays?of?batch_size?*?max_len?into?list?of?arrays?of?max_len
28????return?np.concatenate(predicted_labels).astype(int),?tokenized_texts
29
30def?get_dish_candidate_names(predicted_label,?tokenized_text):
31????name_lists?=?[]
32????if?len(np.where(predicted_label>0)[0])>0:
33????????name_idx_combined?=?np.where(predicted_label>0)[0]
34????????name_idxs?=?np.split(name_idx_combined,?np.where(np.diff(name_idx_combined)?!=?1)[0]+1)
35????????name_lists.append(["?".join(np.take(tokenized_text,name_idx))?for?name_idx?in?name_idxs])
36????????#?If?there?duplicate?names?in?the?name_lists
37????????name_lists?=?np.unique(name_lists)
38????????return?name_lists
39????else:
40????????return?None
41
42texts?=?df_data_val.review.values
43predicted_labels,?_?=?predict(texts)
44df_data_val['predicted_review_label']?=?list(predicted_labels)
45df_data_val['predicted_name']=df_data_val.apply(lambda?row:?get_dish_candidate_names(row.predicted_review_label,?row.review_tokens)
46????????????????????????????????????????????????,?axis=1)
47
48texts?=?df_data_train.review.values
49predicted_labels,?_?=?predict(texts)
50df_data_train['predicted_review_label']?=?list(predicted_labels)
51df_data_train['predicted_name']=df_data_train.apply(lambda?row:?get_dish_candidate_names(row.predicted_review_label,?row.review_tokens)
52????????????????????????????????????????????????,?axis=1)
53
54(df_data_val)
实验结果


可以看到,模型成功地从用餐评论中,提取出了菜名。
模型比拼
从上面的实战应用中可以看到,ALBERT虽然很lite,结果也可以说相当不错。
那么,参数少、结果好,是否就可以替代BERT呢?
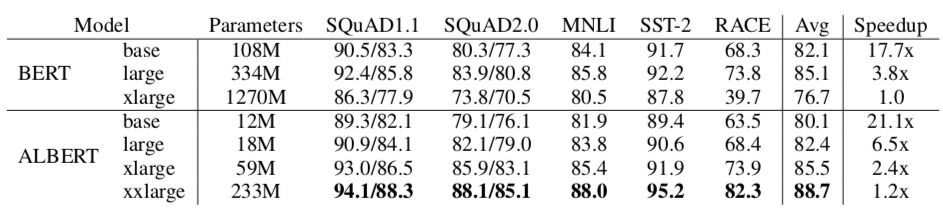
我们可以仔细看下二者实验性能的比较,这里的Speedup是指训练时间。
因为数据数据少了,分布式训练时吞吐上去了,所以ALBERT训练更快。但推理时间还是需要和BERT一样的transformer计算。
所以可以总结为:
在相同的训练时间下,ALBERT效果要比BERT好。
在相同的推理时间下,ALBERT base和large的效果都是没有BERT好。
此外,Naman Bansal认为,由于ALBERT的结构,实现ALBERT的计算代价比BERT要高一些。
所以,还是“鱼和熊掌不可兼得”的关系,要想让ALBERT完全超越、替代BERT,还需要做更进一步的研究和改良。
传送门
博客地址:
https://medium.com/@namanbansal9909/should-we-shift-from-bert-to-albert-e6fbb7779d3e
作者系网易新闻·网易号“各有态度”签约作者
—?完?—
戳二维码,备注“英伟达”即可报名、加交流群、获取前两期直播回放,主讲老师也会进群与大家交流互动哦~
免费报名 | 图像与视频处理系列直播课

学习计划 | 关注AI发展新动态
内参新升级!拓展优质人脉,获取最新AI资讯&论文教程,欢迎加入AI内参社群一起学习~


量子位?QbitAI · 头条号签约作者
?'?' ? 追踪AI技术和产品新动态
喜欢就点「在看」吧 !
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/




![中村迟 一个小时以后直个播[嘘]](https://imgs.knowsafe.com:8087/img/aideep/2024/11/10/efd76b8de31b418ab942abb1292bf916.jpg?w=250)

 量子位
量子位
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 打好关键核心技术攻坚战 7904720
- 2 在南海坠毁的2架美国军机已被捞出 7809207
- 3 立陶宛进入紧急状态 卢卡申科发声 7714156
- 4 持续巩固增强经济回升向好态势 7617302
- 5 多家店铺水银体温计售空 7520586
- 6 奶奶自爷爷去世9个月后变化 7427864
- 7 仅退款225个快递女子已归案 7333568
- 8 日舰曾收到中方提示 7234942
- 9 中国中冶跌10.03% 7141724
- 10 我国成功发射遥感四十七号卫星 7046621