机器之心&ArXiv Weekly Radiostation参与:杜伟,楚航,罗若天
本周的重要论文包括上海交通大学研究者利用自组织记忆模块来解决网络图片中的标签噪声和背景噪声问题,以及 Facebook AI 研究院的学者提出激励智能体在游戏环境中采取行动的 RIDE 内在奖励方法。
目录:
Learning from Web Data with Memory Module
PF-Net: Point Fractal Network for 3D Point Cloud Completion
RIDE: REWARDING IMPACT-DRIVEN EXPLORATION FOR PROCEDURALLY-GENERATED ENVIRONMENTS
CNN-generated images are surprisingly easy to spot... for now
Learning to be Global Optimizer
DISTRIBUTED HIERARCHICAL GPU PARAMETER SERVER FOR MASSIVE SCALE DEEP LEARNING ADS SYSTEMS
BERT-OF-THESEUS: COMPRESSING BERT BY PROGRESSIVE MODULE REPLACING
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)。
论文 1:Learning from Web Data with Memory Module摘要:在这篇论文中,研究者利用网络数据研究图像分类任务 (image classification)。他们发现网络图片 (web image) 通常包含两种噪声,即标签噪声 (label noise) 和背景噪声 (background noise)。前者是因为当使用类别名 (category name) 作为关键字来爬取网络图像时,在搜索结果中可能会出现不属于该类别的图片。后者则是因为网络图片的内容与来源非常多样,导致抓取的图片往往包含比标准的图像分类数据集更多的无关背景信息。在下图中的两张图片均用关键字「狗」抓取。左边图片的内容是狗粮而不是狗,属于标签噪声;右边的图像中,草原占据了整个图像的大部分,同时小孩子也占据了比狗更为显著的位置,属于背景噪声。这两种噪声给利用网络数据学习图像分类器带来了很多额外的困难,而现有的方法要么非常依赖于额外的监督信息,要么无法应对背景噪声。论文中提出了一种不需要额外监督信息的方法来同时处理这两种类型的噪声,并在四个基准数据集上的实验证明了方法的有效性。本文已被 CVPR 2020 接收。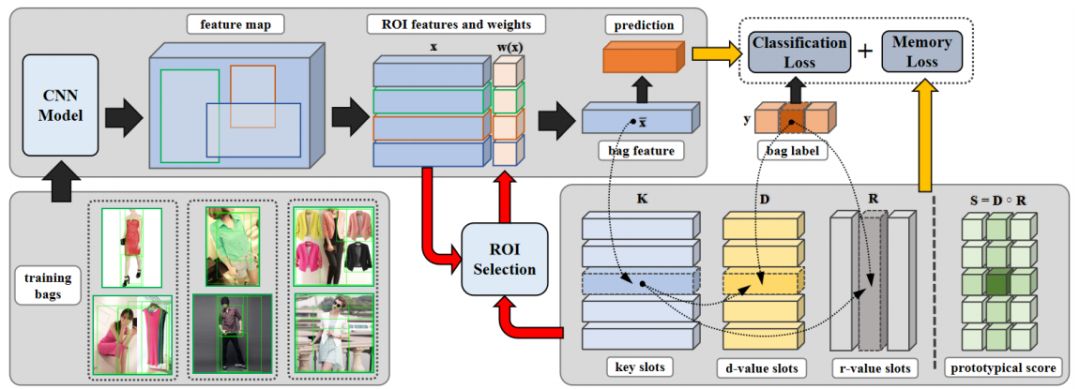

以 Clothing1M 数据集为例,对西装(Suit)这个类别可视化了其中三个 key slot。每个饼图显示对应 key slot 在 14 个类别上的 d-scores,和其在西装类别上的 r-score。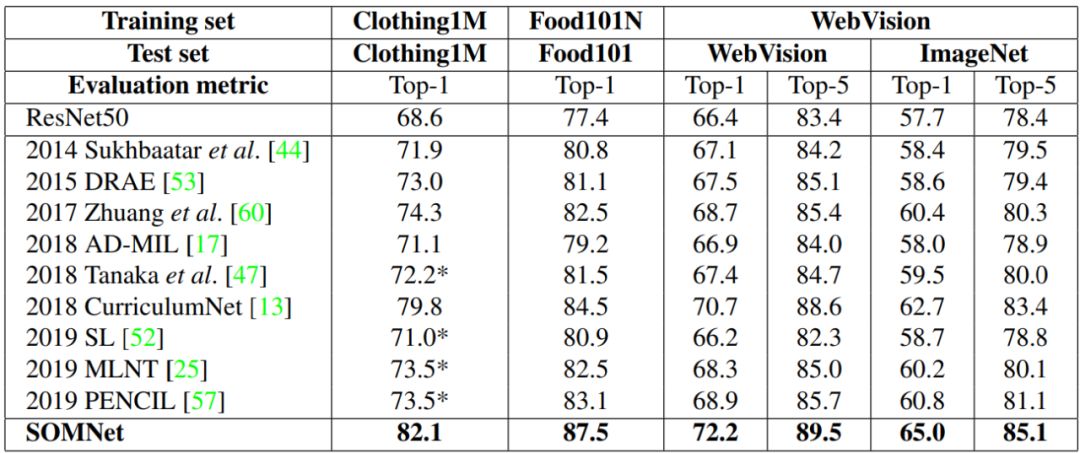
不同方法在 Clothing1M、Food101、Webvision 和 ImageNet 数据集上的准确率对比。推荐:在多实例学习的框架下,研究者设计了一种自组织记忆模块来同时解决网络图片中的标签噪声和背景噪声问题,并在图像分类实验中取得了优异的结果。论文 2:PF-Net: Point Fractal Network for 3D Point Cloud Completion作者:Zitian Huang、Yikuan Yu、 Xinyi Le 等
论文链接:https://arxiv.org/pdf/2003.00410.pdf
代码地址:https://github.com/zztianzz/PF-Net-Point-Fractal-Network
摘要:传统的点云补完方法基于一定的物体基础结构的先验信息,如对称性信息或语义类信息等,通过一定的先验信息对缺失点云进行修补。这类方法只能处理一些点云缺失率很低、结构特征十分明显的缺失点云。近年来,一些工作也尝试使用深度学习来实现点云补全,如 LGAN-AE[3],PCN[4], 和 3D-Capsule[5] 等,这些工作以不完整点云作为输入,输出完整点云,造成网络过于关注到物体的整体特征而忽略了缺失区域的几何信息。另一方面,这些网络会生成偏向于某类物体共性特征的点云,而失去某个物体的个体特征。我们提出点云分形网络(PF-Net:Point Fractal Network),采用了类似分形几何的思想,同样以不完整点云作为输入,但是仅输出缺失部分点云,并且较好地保留了某个物体的个体特征。
点云补全效果对比,从上往下(输入; LGAN-AE 输出 [3] , PCN 输出 [4]; 3D-Capsule 输出 [5] ; 我们的 PF-Net 输出; 真实输出)。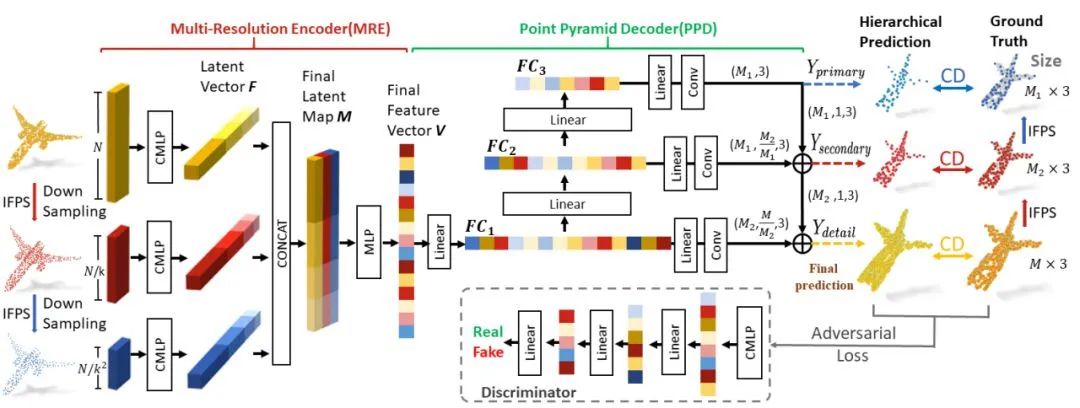
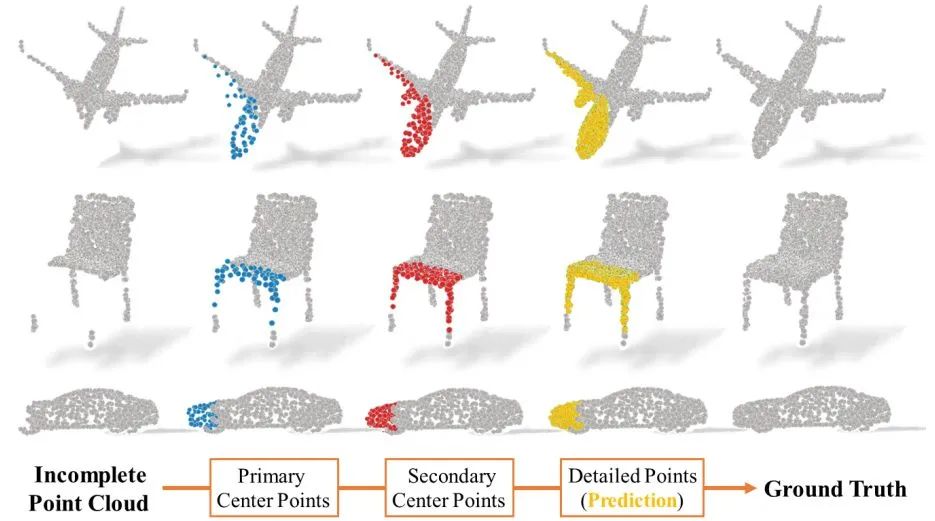
推荐:总体来说,PF-Net 实现了缺失点云数据下的精细补全,在不同缺失率和多个缺失位置的情况下的补全效果均较好,可以作为点云预处理方法,提高点云分割、点云识别的准确率。论文 3:RIDE: REWARDING IMPACT-DRIVEN EXPLORATION FOR PROCEDURALLY-GENERATED ENVIRONMENTS
摘要:在本文中,Facebook 人工智能研究院的两名研究者提出了 Rewarding Impact-Driven Exploration(RIDE)内在奖励方法,它能够激励 AI 驱动的智能体在环境中采取行动。他们表示,在程序生成世界中的艰难探索任务上,这种内在奖励方法优于当前 SOTA 方法。由此表明,这种方法可能会取代扫地机器人等必须经常在新环境中导航的设备。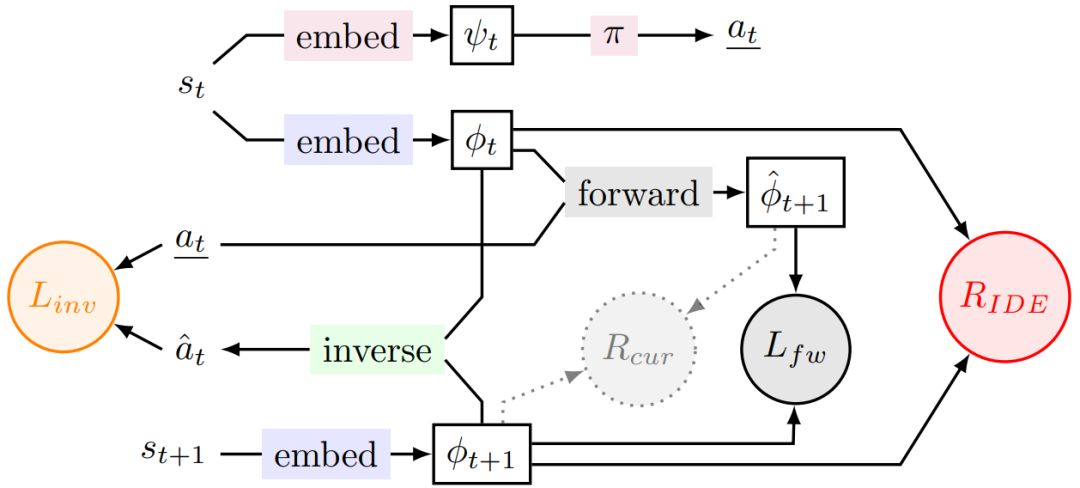
如果智能体的行动对状态表示产生影响,则会受到 RIDE 的奖励。智能体通过前向(L_fw)和逆动力学(L_inv)模型学得。推荐:文中 RIDE 方法在程序式生成的稀疏奖励环境中尤为有效,其性能远超 IMPALA 以及 Count、RND 和 ICM 等一些最流行的探索方法。论文 4:CNN-generated images are surprisingly easy to spot... for now作者:Sheng-Yu Wang、Oliver Wang、Alexei A. Efros 等
论文链接:https://arxiv.org/pdf/1912.11035.pdf
项目链接:https://github.com/peterwang512/CNNDetection
摘要:来自 Adobe 和加州伯克利的研究人员在论文预印本平台 arXiv 上传了《CNN-generated images are surprisingly easy to spot... for now》,他们提出,即使是在一种 CNN 生成的图像所训练的分类器,也能够跨数据集、网络架构和训练任务,展现出惊人的泛化能力。这篇论文目前已被 CVPR 2020 接收,代码和模型也已公布。在这项工作中,研究者希望找到一种用于检测 CNN 生成图像的通用图像伪造检测方法。检测图像是否由某种特定技术生成是相对简单的,只需在由真实图像和该技术生成的图像组成的数据集上训练一个分类器即可。在本文中,研究者遵循惯例并通过简单的方式训练分类器,使用单个 CNN 模型(使用 ProGAN,一种高性能的非条件式 GAN 模型)生成大量伪造图像,并训练一个二分类器来检测伪造图像,将模型使用的真实训练图像作为负例。此外,本文还提出了一个用于检测 CNN 生成图像的新数据集和评价指标,并通过实验分析了影响跨模型泛化性的因素。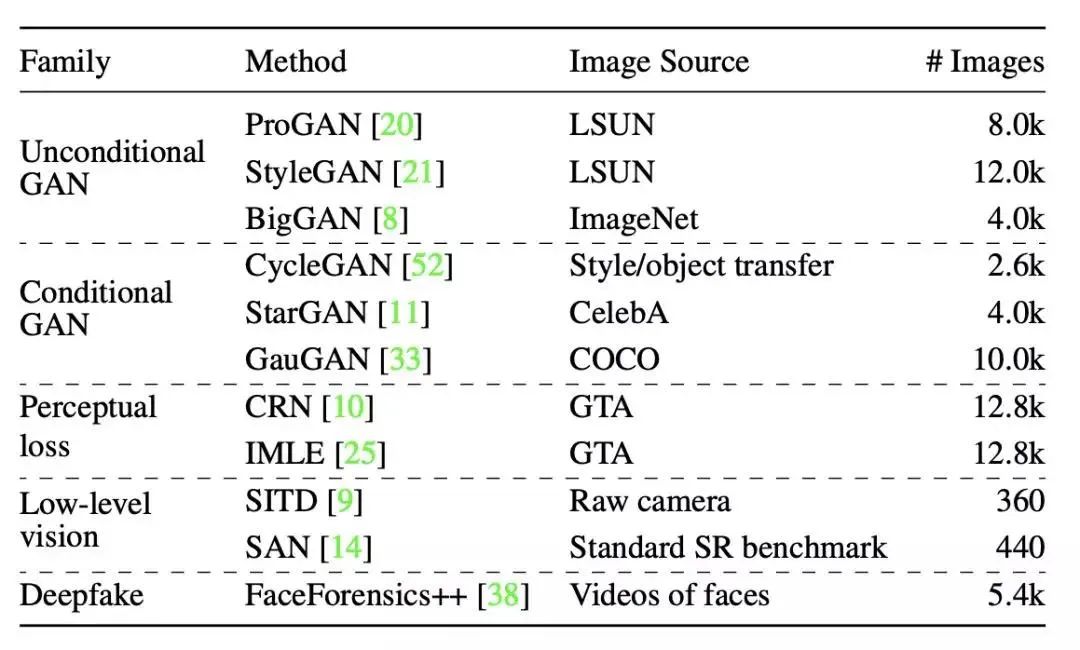
生成模型。研究者评估了伪造检测分类器在多种基于 CNN 的图像生成方法上的效果。
数据增强方法的效果。所有的检测器都在 ProGAN 上进行训练,在其他生成器上进行测试(AP 结果如图所示)。总体来说,使用数据增强进行训练可以帮助提高模型的效果。其中超分辨率模型和 DeepFake 是例外。
数据集多样性的效果。所有的检测器都在 ProGAN 上进行训练,在其他生成器上进行测试(AP 结果如图所示)。使用更多类进行训练可以提高模型表现。所有的训练都以 50% 的概率使用了模糊和 JPEG 进行数据增强。推荐:值得注意的是,检测伪造图像只是解决视觉虚假信息威胁这一难题的一小部分,有效的解决方案需要融合从技术、社会到法律等各方面的广泛战略。论文 5:Learning to be Global Optimizer摘要:在本文中,来自西安交通大学的三位研究者首先提出以一种模型驱动的方法来学习局部凸函数的适应性下降方向,然后基于学习到的方向来开发局部收敛保证算法。接着,他们将填充函数方法中的 escaping phase 建模为马尔科夫决策过程(Markov decision process,MDP),并提出固定策略(fixed policy)和策略梯度学习到的策略(policy learned by policy gradient),以决定新的起始点。结合学习到的局部算法和 escaping 策略,研究者最后构建了一种两段式全局优化算法。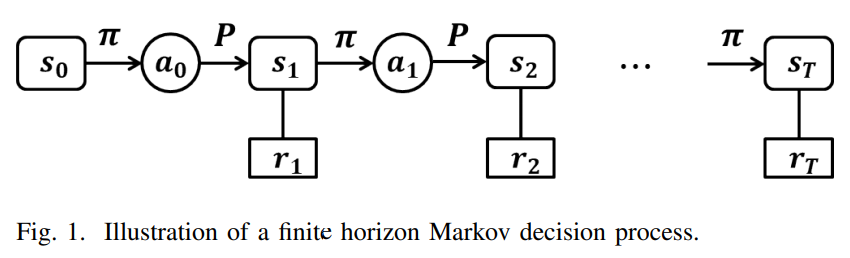
推荐:研究表明,学习到的局部搜索算法呈现收敛性,并且与随机取样相比,固定策略有更大的概率找到有潜力的起始点。大量的实验证实了学习到的局部搜索算法、两种策略以及学习到的两段式全局优化算法的有效性。论文 6:DISTRIBUTED HIERARCHICAL GPU PARAMETER SERVER FOR MASSIVE SCALE DEEP LEARNING ADS SYSTEMS摘要:在本文中,来自百度研究院等机构的研究者提出了一种用于大规模深度学习 ads 系统的分布式 GPU 分级参数服务器。文中提出的分级流程将 GPU 高频宽内存、CPU 主内存和 SSD 作为 3 层分级存储。所有的神经网络训练计算都包含在 GPU 中。在真实世界数据上的大量实验证实了文中提出系统的有效性和可扩展性。研究者表示,文中系统的性价比是 MPI 集群解决方案的 4 至 9 倍。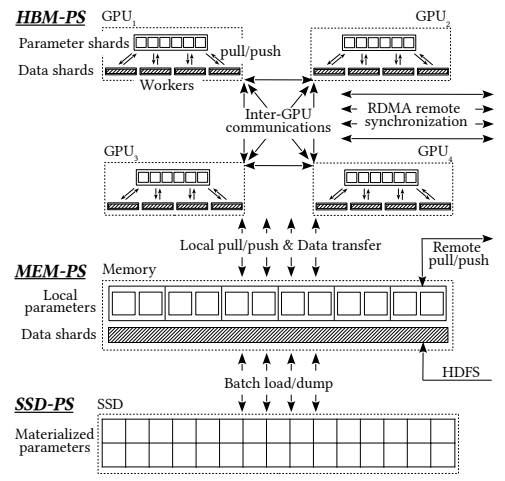
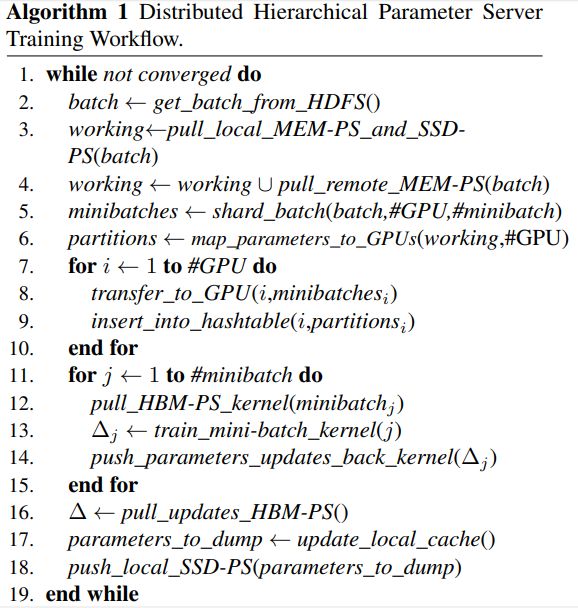
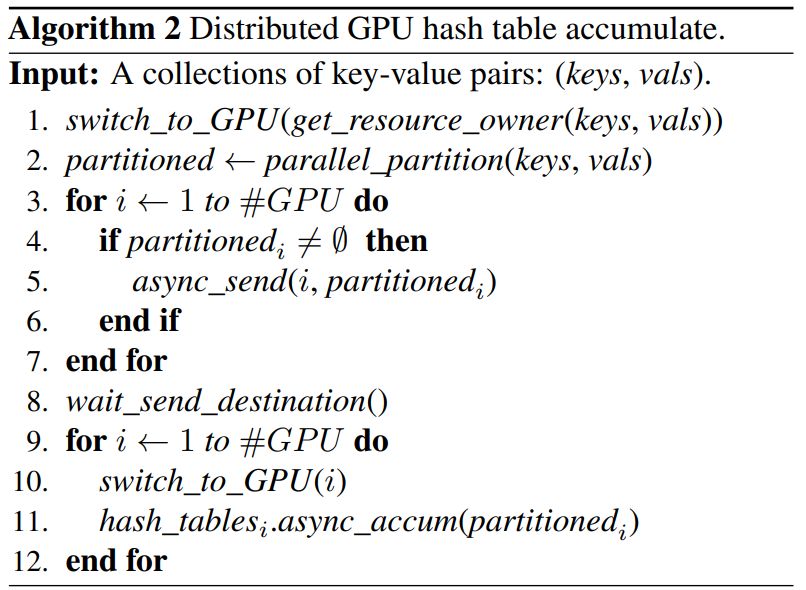
推荐:本文中的系统正与百度 PaddlePaddle 深度学习平台进行集成,以形成「PaddleBox」。论文 7:BERT-OF-THESEUS: COMPRESSING BERT BY PROGRESSIVE MODULE REPLACING摘要:这篇论文提出了一种新型模型压缩方法,能够通过逐步模块替换(progressive module replacing)有效地压缩 BERT。该方法首先将原版 BERT 分割成多个模块,并构建更加紧凑的替代模块;然后,用替代模块随机替换原始模块,训练替代模块来模仿原始模块的行为。在训练过程中,研究者逐步增加模块的替换概率,从而实现原始模型与紧凑模型之间的更深层次交互,使得训练过程流畅进行。与显式地利用蒸馏损失函数来最小化教师模型与学生模型距离的 KD 不同,该研究提出一种新型模型压缩方法。研究者受到著名哲学思想实验「忒修斯之船」的启发(如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?),提出了 Theseus Compression for BERT (BERT-of-Theseus),该方法逐步将 BERT 的原始模块替换成参数更少的替代模块。研究者将原始模型叫做「前辈」(predecessor),将压缩后的模型叫做「接替者」(successor),分别对应 KD 中的教师和学生。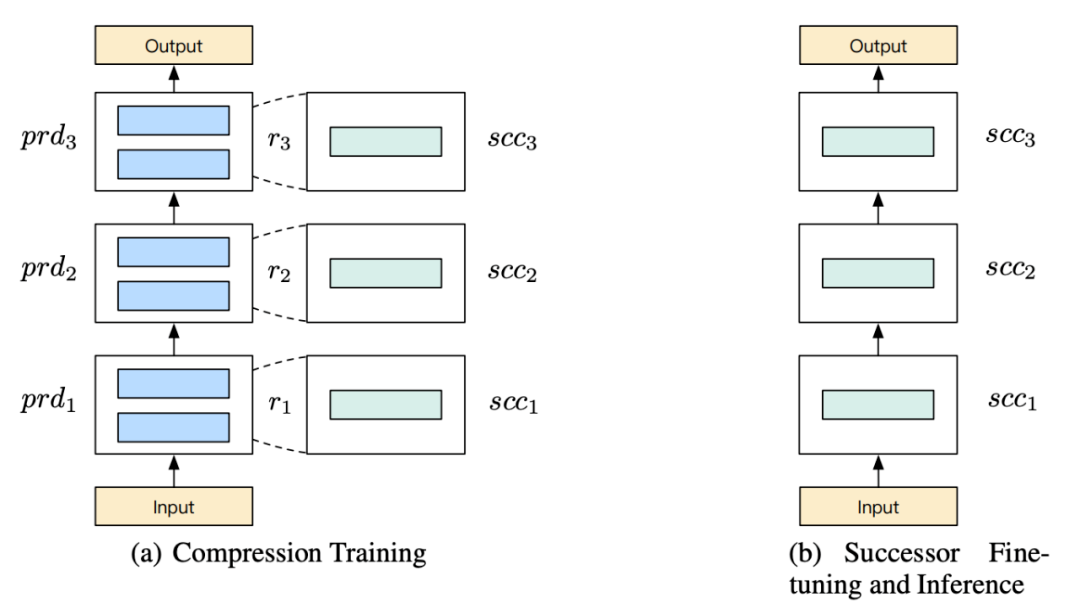
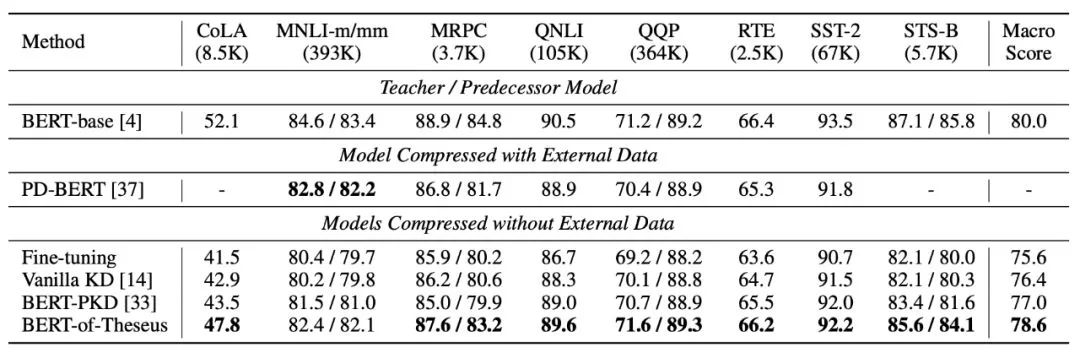
在 GLUE 服务器测试集上的实验结果。每个数据集下的数字表示数据集中的训练样本数量。
该研究训练出的通用模型在 GLUE-dev 上的实验结果。推荐:与之前用于 BERT 压缩的知识蒸馏方法相比,该方法仅利用一个损失函数和一个超参数,将开发者从调参这一繁琐过程中解放出来。该方法在 GLUE 基准上的性能优于现有的知识蒸馏方法,为模型压缩开启了新方向。ArXiv Weekly Radiostation机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Multi-SimLex: A Large-Scale Evaluation of Multilingual and Cross-Lingual Lexical Semantic Similarity. (from Ivan Vuli?, Simon Baker, Edoardo Maria Ponti, Ulla Petti, Ira Leviant, Kelly Wing, Olga Majewska, Eden Bar, Matt Malone, Thierry Poibeau, Roi Reichart, Anna Korhonen)2. Improving Neural Named Entity Recognition with Gazetteers. (from Chan Hee Song, Dawn Lawrie, Tim Finin, James Mayfield)3. A Framework for the Computational Linguistic Analysis of Dehumanization. (from Julia Mendelsohn, Yulia Tsvetkov, Dan Jurafsky)4. Adv-BERT: BERT is not robust on misspellings! Generating nature adversarial samples on BERT. (fromLichao Sun, Kazuma Hashimoto, Wenpeng Yin, Akari Asai, Jia Li, Philip Yu, Caiming Xiong)5. Pseudo Labeling and Negative Feedback Learning for Large-scale Multi-label Domain Classification. (from Joo-Kyung Kim, Young-Bum Kim)6. TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages. (from Jonathan H. Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, Jennimaria Palomaki)7. Learning to Respond with Stickers: A Framework of Unifying Multi-Modality in Multi-Turn Dialog. (from Shen Gao, Xiuying Chen, Chang Liu, Li Liu, Dongyan Zhao, Rui Yan)8. It Means More if It Sounds Good: Yet Another Hypotheses Concerning the Evolution of Polysemous Words. (fromIvan P. Yamshchikov, Cyrille Merleau Nono Saha, Igor Samenko, Jürgen Jost)9. The growing echo chamber of social media: Measuring temporal and social contagion dynamics for over 150 languages on Twitter for 2009--2020. (from Thayer Alshaabi, David R. Dewhurst, Joshua R. Minot, Michael V. Arnold, Jane L. Adams, Christopher M. Danforth, Peter Sheridan Dodds)10. Shallow Discourse Annotation for Chinese TED Talks. (from Wanqiu Long, Xinyi Cai, James E. M. Reid, Bonnie Webber, Deyi Xiong)1. Visual Grounding in Video for Unsupervised Word Translation. (from Gunnar A. Sigurdsson, Jean-Baptiste Alayrac, Aida Nematzadeh, Lucas Smaira, Mateusz Malinowski, Jo?o Carreira, Phil Blunsom, Andrew Zisserman)2. Learning Delicate Local Representations for Multi-Person Pose Estimation. (from Yuanhao Cai, Zhicheng Wang, Zhengxiong Luo, Binyi Yin, Angang Du, Haoqian Wang, Xinyu Zhou, Erjin Zhou, Xiangyu Zhang, Jian Sun)3. Beyond the Camera: Neural Networks in World Coordinates. (from Gunnar A. Sigurdsson, Abhinav Gupta, Cordelia Schmid, Karteek Alahari)4. Rethinking Image Mixture for Unsupervised Visual Representation Learning. (from Zhiqiang Shen, Zechun Liu, Zhuang Liu, Marios Savvides, Trevor Darrell)5. A New Meta-Baseline for Few-Shot Learning. (from Yinbo Chen, Xiaolong Wang, Zhuang Liu, Huijuan Xu, Trevor Darrell)6. Improved Baselines with Momentum Contrastive Learning. (from Xinlei Chen, Haoqi Fan, Ross Girshick, Kaiming He)7. HeatNet: Bridging the Day-Night Domain Gap in Semantic Segmentation with Thermal Images. (from Johan Vertens, Jannik Zürn, Wolfram Burgard)8. Highly Efficient Salient Object Detection with 100K Parameters. (from Shang-Hua Gao, Yong-Qiang Tan, Ming-Ming Cheng, Chengze Lu, Yunpeng Chen, Shuicheng Yan)9. Unifying Specialist Image Embedding into Universal Image Embedding. (from Yang Feng, Futang Peng, Xu Zhang, Wei Zhu, Shanfeng Zhang, Howard Zhou, Zhen Li, Tom Duerig, Shih-Fu Chang, Jiebo Luo)10. Transformation-based Adversarial Video Prediction on Large-Scale Data. (from Pauline Luc, Aidan Clark, Sander Dieleman, Diego de Las Casas, Yotam Doron, Albin Cassirer, Karen Simonyan)1. Robustness Guarantees for Mode Estimation with an Application to Bandits. (from Aldo Pacchiano, Heinrich Jiang, Michael I. Jordan)2. Efficiency and Equity are Both Essential: A Generalized Traffic Signal Controller with Deep Reinforcement Learning. (from Shengchao Yan, Jingwei Zhang, Daniel Buescher, Wolfram Burgard)3. Towards CRISP-ML(Q): A Machine Learning Process Model with Quality Assurance Methodology. (from Stefan Studer, Thanh Binh Bui, Christian Drescher, Alexander Hanuschkin, Ludwig Winkler, Steven Peters, Klaus-Robert Mueller)4. Building and Interpreting Deep Similarity Models. (from Oliver Eberle, Jochen Büttner, Florian Kr?utli, Klaus-Robert Müller, Matteo Valleriani, Grégoire Montavon)5. The MineRL Competition on Sample-Efficient Reinforcement Learning Using Human Priors: A Retrospective. (from Stephanie Milani, Nicholay Topin, Brandon Houghton, William H. Guss, Sharada P. Mohanty, Oriol Vinyals, Noboru Sean Kuno,? (2) OpenA,? (3) AIcrow,? (4) DeepMin,? (5) Microsoft Research)6. A Survey of Adversarial Learning on Graphs. (from Liang Chen, Jintang Li, Jiaying Peng, Tao Xie, Zengxu Cao, Kun Xu, Xiangnan He, Zibin Zheng)7. Trends and Advancements in Deep Neural Network Communication. (from Felix Sattler, Thomas Wiegand, Wojciech Samek)8. Causal Interpretability for Machine Learning -- Problems, Methods and Evaluation. (from Raha Moraffah, Mansooreh Karami, Ruocheng Guo, Adrienne Ragliny, Huan Liu)9. Closure Properties for Private Classification and Online Prediction. (from Noga Alon, Amos Beimel, Shay Moran, Uri Stemmer)10. Transfer Reinforcement Learning under Unobserved Contextual Information. (from Yan Zhang, Michael M. Zavlanos)
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号




