
DeepMind推出GAN-TTS:用生成对抗网络实现高保真语音

??新智元报道??
??新智元报道??
编辑:鹏飞
【新智元导读】这是一种使用GAN进行文本转语音的新模型,将高质量与高效生成结合在一起。证明GAN-TTS能够产生自然逼真的高保真语音,可与最新模型媲美,而且与自回归模型不同,得益于高效的前馈发生器,它具有很高的可并行性。>>>人工智能改变中国,我们还要跨越这三座大山 | 献礼70周年
人类梦想让文字说话已经有好几个世纪的历史了。你可能没想到,其实在1968年,日本的电机技术实验室由Noriko Umeda和他的同伴开发了第一个完整的英语语音转换系统(Text-To-Speech,简称TTS)。
这套系统基于发音模型,并包含具有复杂启发式功能的句法分析模块,只不过发音非常生硬。
随着NLP和神经网络的加入,语音合成技术有了非常显著的发展,像WaveNet、SampleRNN、WaveRNN这类原始音频波形的神经自回归模型的表现尤为亮眼。
然而这类模型却有着非常大的局限性。不仅难以随时间进行并行化,而且成本高的离谱。偏偏高度可并行化的模型更适合在现代硬件上高效运行。
相比而言,GAN在并行波形生成方面有一定的优势,虽然目前GAN主要应用于图像领域,但在音频生成方面表现平平,除了WaveGAN和GANSynth等。
DeepMind发现,GAN尚未大规模应用于非可视领域。24kHz1处的两秒钟音频维度为48000,可与128128分辨率下的RGB图像媲美!所以DeepMind决定要探索一下使用GAN生成原始波形的过程,然后GAN-TTS诞生了。

GAN-TTS是什么?能干什么?效果如何
这是一种用于文本条件的高保真语音合成的生成对抗网络。它的前馈生成器是一个卷积神经网络,与多个鉴别器集成在一起,这些鉴别器基于多频随机窗口评估生成的(和实际的)音频。
值得注意的是,一些鉴别器会考虑语言条件(因此他们可以衡量所生成的音频与输入话语的对应程度),而其他鉴别器则忽略了条件,只能评估音频的一般真实感。
基于Frechet的入耳距离和Kernel Inception Distance提出了一系列语音生成量度指标,替换了Inception图像识别网络和Deep-Speech音频识别网络。
提出了对TTS-GAN及其消融的定量和主观评估,表明了架构选择的重要性。最终,性能最佳的模型实现了4:2的MOS,可与4:4的最新WaveNet MOS相提并论,并将GAN确立为高效TTS的可行选择。
大多数用于音频生成的神经模型都是基于似然性的:它们表示明确的概率分布,并且在这种分布下,观察到的数据的似然性最大。自回归模型通过将联合分布分解为条件分布的乘积来实现此目的。
另一种策略是使用可逆前馈神经网络直接建模关节密度。或者,可以通过使用概率密度蒸馏法蒸馏自回归模型来训练可逆前馈模型,这使它可以专注于特定模式。
在条件生成设置中,通常需要这种寻求模式的行为:研究人员希望生成的语音信号听起来逼真并与给定的文本相对应,但是研究人员不希望对数据中发生的每种可能的变化进行建模。这减少了模型容量要求,因为部分数据分布可能会被忽略。注意,对抗模型表现出相似的行为,但是没有蒸馏和可逆性要求。
数据集和生成器
GAN-TTS模型所使用的数据集包含人类语音的高保真音频,以及相应的语言特征和音调信息。语言特征对语音和持续时间信息进行编码,而音调由对数基本频率对数F0表示,总共有567个功能。
没有使用真实的持续时间和音调来进行主观评估;相反,研究人员使用了单独模型预测的持续时间和音高。
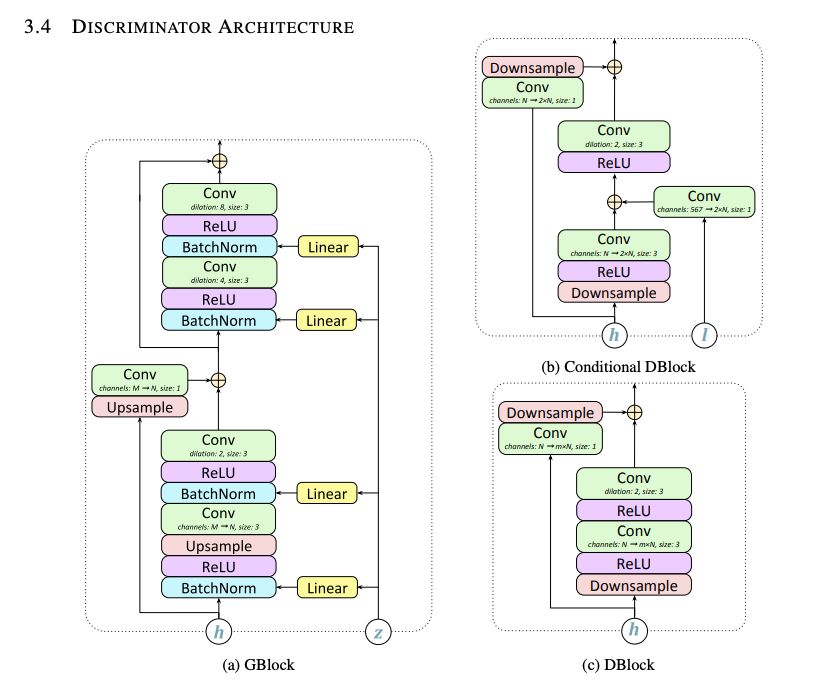
数据集由包含单个序列的可变长度音频片段组成,由专业配音演员用北美英语说出。为了进行培训,使用2秒的采样窗口(过滤出较短的示例)以及相应的语言功能。过滤后的数据集的总长度为44小时。
音频的采样频率为24kHz,而语言特征和音高是针对5ms窗口(200Hz)计算的。这意味着生成器网络需要学习如何将语言特征和音高转换为原始音频,同时对信号进行上采样120倍。使用-law变换来解释音量的对数感知。
效果
下表给出了对所提议模型的定量评估,以及研究人员在这项工作中考虑的GAN-TTS基准和其他变体。研究人员最好的模型在WaveNet和Parallel WaveNet上获得的分数要比强基线差,但可比。
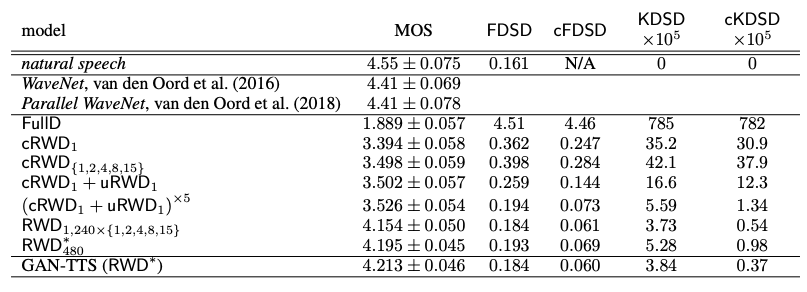
但是,这种性能尚未使用对抗技术实现,并且仍然非常好,尤其是与参数文本到语音模型相比时。由于数据集差异,这些结果不能直接比较。例如WaveNet和Parallel WaveNet接受了65个小时的数据培训,比GAN-TTS多了一点。
研究人员的消融研究证实了结合多个RWD的重要性。确定性全鉴别器得分最差。所有多个RWD模型均比单个cRWD1获得更好的结果。
使用无条件RWD的所有模型均优于未使用无条件RWD的模型。比较10个判别器模型,很明显,不同窗口大小的组合是有益的,因为10个固定大小窗口的简单组合明显更糟。
三种具有不同鉴别器大小的10-RWD模型均获得了相似的平均意见得分,其中基本窗口大小为240的下采样模型表现最佳。
研究人员还观察到人类评估得分(MOS)与拟议指标之间的显着相关性,这表明这些指标非常适合神经音频合成模型的评估。
结论
研究人员推出了GAN-TTS,这是一种用于原始音频文本到语音生成的GAN。与最新的文本语音转换模型不同,GAN-TTS经过对抗训练,生成的生成器是前馈卷积网络。
这允许非常有效的音频生成,这在实际应用中很重要。研究人员的架构探索导致了一个模型的发展,该模型具有在不同窗口大小下运行的无条件和有条件的随机窗口鉴别器集合,它们分别评估所生成语音的真实性及其与输入文本的对应性。
研究人员在消融研究中表明,这些组件中的每一个对于实现良好的性能都至关重要。研究人员还为生成的语音模型提出了一系列量化指标:(有条件的)Frechet DeepSpeech距离和(有条件的)内核DeepSpeech距离,并通过实验证明了这些指标对模型的排名与通过人工评估获得的平均意见得分一致。
由于它们基于公开可用的DeepSpeech识别模型,因此它们将可用于机器学习社区。研究人员的定量结果以及对生成样本的主观评估表明,使用GAN进行文本到语音转换的可行性。
论文地址:
https://arxiv.org/pdf/1909.11646.pdf
点击“阅读原文”直接跳转到《智周万物:人工智能改变中国》购买链接

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/





![脸脸:好东西都整理在[xeva]](https://imgs.knowsafe.com:8087/img/aideep/2025/3/31/d9e3fedaa390c85dab95ab2f89d47afd.jpg?w=250)
 新智元
新智元
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675