
利用自动深度学习,医务人员也可开发医学影像分类系统,《柳叶刀》子刊报道
大数据文摘出品
来源:ScienceDirect
编译:张大笔茹、曹培信
深度学习可以给医疗领域带来巨大的改变,但是,开发训练模型需要大量的专业知识。《柳叶刀》子刊《柳叶刀数字健康》本月报道了一篇论文,论文实现了让没有任何深度学习专业知识且不会写代码的医务人员利用自动深度学习开发医学图像诊断分类器。

尽管发展迅速,深度学习技术在医疗领域应用还有三大挑战
?
病情诊断本质上是一种对疾病存在概率的理解,通过收集、整合和解释数据将临床表现,将病人准确分类到某一疾病上的过程。
学医的医学生是通过学习前人记录的诊断规则,对已有诊断结果的实际病例进行培训(监督临床经验),以掌握该项诊断技术。但是对人工智能而言,深度学习技术利用与生物神经网络相似的人工神经网络,在大型高维数据集(如医学数据)中发现复杂结构和模式的计算模型。
这些网络的关键特征之一是可以根据经验对输入进行微调,这一特性使其成为模式识别、分类和预测的有力工具,此外,发现的特征不是由人类预先确定的,而是由输入数据中学到的模式来确定的。
20世纪80年代首次被提出以来,深度学习在过去10年中飞速发展,很大程度上是由于最初为视频游戏开发的图形处理功能的进步以及日益增多的大型开源数据集,自2012年以来,深度学习为计算机视觉、图像处理、语音识别、自然语言翻译、机器人技术,甚至是汽车自动驾驶等多种领域带来了深刻变革。2015年,“科学美国人(Scientific American)”杂志将深度学习列为年度“改变世界思想”之一。
目前,深度学习技术在医疗方面的应用主要有三个障碍。
首先,访问大型、格式标准且结果准确的数据集是一项重大挑战,尽管世界各地的许多机构的大型临床数据集都是开放的,但是拥有易于处理和计算的形式以及可用于学习任务的准确的临床诊断结果的数据数量却很少。
其次,高度专业化的计算资源还是稀缺的,因为深度学习模型的准确度取决于并行计算架构(GPU)的最新进展,随着越来越多软件公司开始设计自己的硬件芯片,例如张量处理单元和现场可编程门阵列,定制任务的硅架构。因此出于财务成本考虑,小型研究小组很难独自在医院和大学的环境中工作。
第三,拥有专业技术和数学知识的开发深度学习模型的专业人员依然很少。2019Element AI年报告显示,尽管全球报告的AI专家人数已增加到3,000人,但“顶级人工智能人才仍供不应求”。
解决这些问题的方法之一是越来越流行的迁徙学习(transfer learning),其针对特定任务开发的模型被迁徙用作训练新任务。尽管迁徙学习从一开始就减少了设计定制模型所需的一些实质性计算资源,但它仍然需要深度学习专业知识。考虑到这一点,几家公司在2018年发布了应用程序编程接口(API),声称可以实现自动深度学习,即任何具有基本计算机能力的人都可以开发高质量的模型。
不懂编程,也可设计顶尖的医学图像诊断分类系统
不懂编程,也可设计顶尖的医学图像诊断分类系统
由于编程不是医疗保健专业人员的长项,因此自动深度学习是医疗保健和医学科学中使用深度学习的一种解决途径。在疾病诊断中,模型自动将通用神经网络架构与给定的成像数据集匹配,通过微调网络优化判别性能并创建出输出预测算法。换句话说,输入的是(标记的)图像数据集,输出的是自定义分类算法。
然而,毫无编码经验的人在多大程度上可以在自动深度学习的帮助下达到训练有素的深度学习工程师的程度,这仍是未知数。
研究内容
在这项研究中,两位没有任何深度学习专业知识的医生探讨了自动化深度学习模型开发的可行性,并研究了这些模型在诊断医学成像中的各种疾病方面的表现。更确切地说,确定了用于诊断图像分类任务的医学基准成像数据集及其在深度学习模型上的相应产物。使用这些数据集作为输入,用自动深度学习模型取代了经典的深度学习模型,并比较了经典和自动深度学习模型的辨别性能。此外,还评估了用于自动深度学习模型开发的界面(Google Cloud AutoML Vision API,beta版),以用于预测模型研究。
数据库
研究使用五个开源数据集:视网膜眼底图像教材(MESSIDOR);光学相干断层扫描(OCT)图像教材(广州医科大学和Shiley Eye Institute,第3版);皮肤病变图像(Human Against Machine [HAM] 10000);以及儿科和成人胸部X射线(CXR)图像教材(广州医科大学和Shiley Eye Institute,第3版和国家卫生研究院[NIH]数据集 )。
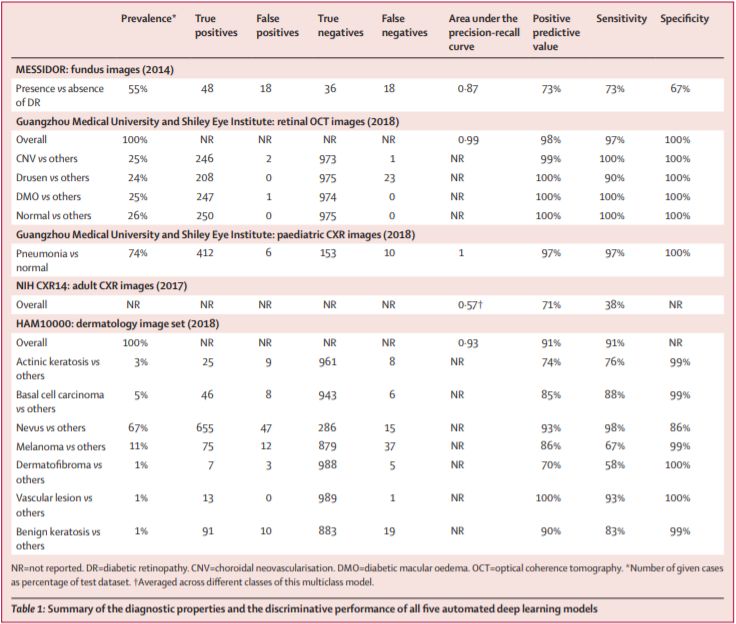
将这些数据分别提供给通过Google Cloud AutoML托管的神经架构搜索框架,该框架自动开发了深度学习架构来对常见疾病进行分类。以敏感性、特异性和阳性预测值(精确度)来评估模型的诊断效果。用精确回忆曲线(AUPRC)下的面积来判断性能,并使用Edinburgh Dermofit Library数据集对在HAM10000数据集子集上开发的深度学习模型进行外部验证。
实验结果
内部验证的诊断成功率和判别成功率在二元分类结果中很高(灵敏度73.3-97.0%,特异性在67-100%, AUPRC 0.87-1.00)。在多元分类结果中,诊断特性灵敏度范围为38%至100%,特异性范围为67%至100%。五种自动深度学习模型中,AUPRC的判别性能范围为0.57至1.00。Edinburgh Dermofit Library数据集的外部验证中,自动深度学习模型显示AUPRC为0.47,灵敏度为49%,阳性预测值为52%。
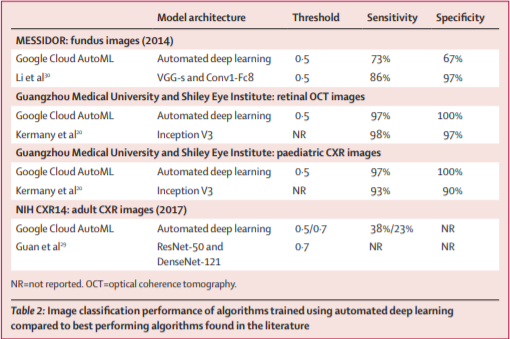
尽管准确度可以,但与专业设计模型相比还很局限
尽管准确度可以,但与专业设计模型相比还很局限
除了NIH CXR14数据集的多标签分类结果上训练的自动深度学习模型之外,所有模型都显示出与最先进的深度学习算法相当的辨别度和诊断灵敏度。然而外部验证研究的表现不佳,主要是由于开放获取数据集的质量(包括关于患者流量和人口统计学的信息不足)以及缺乏精确度测量(例如置信区间)。
自动深度学习平台的应用增强了医学界对模型开发和效果评估的理解,虽然在不需要深入理解数学、统计学和编程原理的情况下推导分类模型很有吸引力,但与专业设计模型相比,自动深入学习技术开发的模型性能仅限于更基本的分类功能。此外,在应用这些自动化模型时应避免误判造成的潜在威胁以及注意道德准则。未来的研究应在更优质更完整的数据集上比较几个模型的效果。
相关报道:
https://www.sciencedirect.com/science/article/pii/S2589750019301086
一个去乌镇的机会!
第六届世界互联网大会?乌镇峰会
数字经济人才专场研讨会
首届“30位新生代数字人才”评选
报名启动!

实习/全职编辑记者招聘ing
加入我们,亲身体验一家专业科技媒体采写的每个细节,在最有前景的行业,和一群遍布全球最优秀的人一起成长。坐标北京·清华东门,在大数据文摘主页对话页回复“招聘”了解详情。简历请直接发送至zz@bigdatadigest.cn


关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![张予曦品牌直播Look,美神降临仙气十足![哇]](https://imgs.knowsafe.com:8087/img/aideep/2024/12/30/90ed36aca05104df9033aebfeda1acbe.jpg?w=250)



 大数据文摘
大数据文摘
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675