
耐能团队论文登上《自然·电子学》:集成忆阻器与CMOS以实现更好的AI

《自然·电子学》杂志封面(资料图,来源:《自然》官网)
来源:Kneron耐能
近日,《自然》杂志子刊《自然·电子学》(Nature Electronics)发表论文《集成忆阻器与CMOS以实现更好的AI》(Integrating Memristors and CMOS for Better AI),介绍了新型忆阻内存元器件结合传统CMOS工艺应用于AI领域的现状,并展望其方向与趋势。论文指出:通过将忆阻阵列与CMOS电路集成,可创建能提供高效DNN处理器的内存计算架构。
论文作者包括:圣母大学计算机科学与工程系博士后姜炜文、耐能工程总监谢必克、耐能创始人兼CEO刘峻诚,以及身兼耐能高级顾问的圣母大学计算机系终身副教授、博士生导师兼电子系终身副教授史弋宇。
为便于中国读者阅读,我们将其翻译成中文,正文部分如下:
深度神经网络(deep neural network, DNN, 图1a)在各种AI应用中的成功,推动了DNN加速器(或AI处理器)的普及,其中包括GPU、FPGA和ASIC。在这些AI处理器的设计中,能效和计算延迟是需要优化的两个关键指标,特别是在网络之间的边界控制数据流的终端平台,如移动和物联网设备(图1b)。?
然而,由于DNN存在大量的中间数据,当前基于传统冯·诺依曼架构的AI处理器设计方法都受到“内存墙”的限制,以致在内存和数据路径之间的海量数据移动中花费了过多的时间和电能(图1c)。
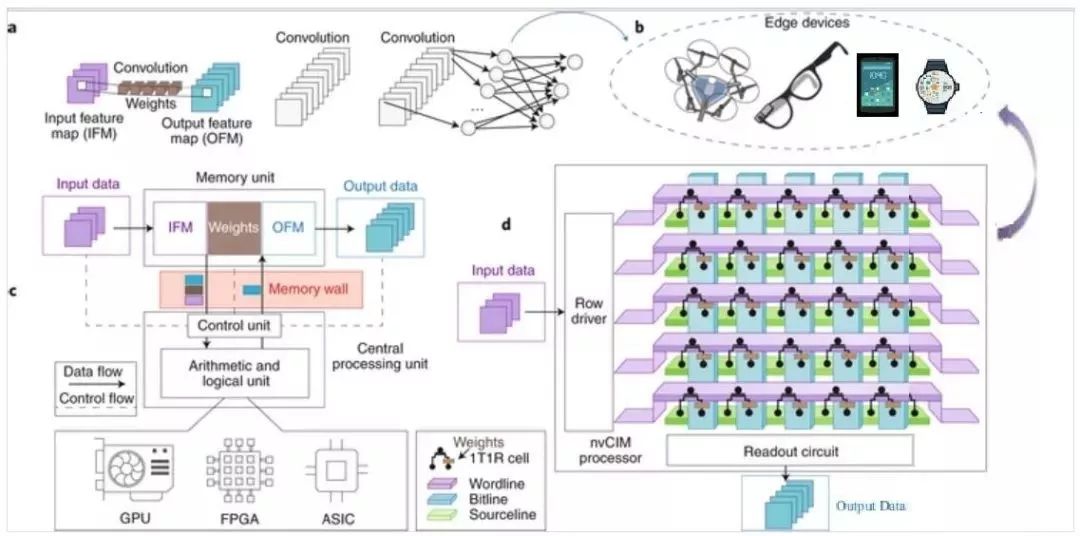
冯·诺依曼架构与用于AI终端设备的nvCIM架构:
a,具有卷积运算的典型DNN。
b,基于DNN执行应用程序的目标终端设备,可以使用nvCIM平台。
c,具有独立存储单元和处理单元的传统冯·诺依曼架构,使用GPU、FPGA或ASIC进行卷积运算。
d,基于nvCIM架构的AI处理器,在同一芯片上集成存储和处理单元。该方法使用忆阻器,可存储数据并具有可在存储器中进行卷积运算的计算能力。
?
为打破这种内存墙,研究人员开发了非易失性内存计算(non-volatile computing-in-memory, nvCIM)架构,它使用nvCIM来存储数据,并直接用这类存储器的计算能力处理数据。
最近关于nvCIM的工作已成功证明,MAC运算——这是DNN中的一项基本运算,可在由忆阻器组成的交叉单元阵列上实现,并可加快DNN的执行。然而,由于缺乏与同一芯片上的外围电路完全集成的存储单元阵列设计,nvCIM的效率增益仍未得到实验证实。
新竹清华大学教授张孟凡(音)及其合作者在《自然·电子学》杂志介绍了一个1Mb的忆阻nvCIM处理器,该处理器将定制控制和读出电路完全集成在一块芯片上。该方法特别集成了单晶体管、单电阻(one-transistor, one-resistor, 1T1R)电阻随机存取存储阵列和65nm制程 CMOS工艺的控制和读出电路。
研究人员使用该nvCIM处理器演示了二个输入、三个加权神经网络,实现了16.95TOPS/W的能效,修改后的数据集在美国国家标准技术研究院(the Modified National Institute of Standards and Technology, NIST)的推断精度达到98.8%。
该处理器可使用两个或三个输入以及MAC运算执行可重构逻辑运算。它在执行三输入布尔逻辑运算时的访问时间仅4.9纳秒,执行MAC运算时的访问时间则为14.8纳秒,这一结果清楚地说明了该方法提供高速运算以加速DNN的潜力。
张孟凡及其合作者使用基于三端1T1R元件的忆阻单元阵列,与传统的二端忆阻单元相比,这种三端1T1R单元可更好地扩展到更大的阵列而减缓功耗增长。该nvCIM处理器还利用数字双模字线驱动器作为行驱动器,它使用小面积数字缓冲器而非典型的数模转换器来提供稳定的模拟电压。
此外,研究人员提出了两种关键的电路级读出技术:小偏移多电平电流模式读出放大器,以及模式和输入自适应参考电流发生器。这些技术可实现低功率高度并行计算的内存运算,并在紧凑区域中克服设备多样性和单元漏电问题从而实现高精度。这些技术也可扩展到更大规模的nvCIM以及其他类型的电阻式存储器和忆阻器件。
张孟凡及其合作者的工作,是开发nvCIM处理器以在终端设备上实现AI的重要一步。但在广泛应用于商业化产品之前,仍有许多问题需要解决:
首先,用于忆阻器的读写电路仍可能在体积、功耗、延迟等方面造成巨大的负担。
其次,忆阻器的电阻状态有限,这要求它们牺牲输入数据或权值的数值精度,导致可能无法进行全精度显示。
然后,多数忆阻器都存在不可预知的问题,例如器件间的相斥、循环耐久性和随时间变化的磨损,需要深入验证它们如何影响AI处理器的性能。为解决这些问题,有必要从软件和硬件的角度探索可能的设计补救措施。
最后,现有基于nvCIM的AI处理器的内存仍然较小,可实现的神经网络对于多数应用来说也过于简单,需要实施大规模系统才能真正展示其实际能力。
这篇论文,是耐能团队在AI学术研究领域的最新成果之一。近年来,耐能团队已发表多篇核心论文并获得多项国际专利,并充分应用于终端AI芯片与解决方案的研发。其中,耐能创始人兼CEO刘峻诚的研究成果主要包括:
1
2019年
美国专利:卷积运算器件和方法(Operation Device and Mmethod for Convolutional Neural Network)
2
2018年
美国专利:缓冲器、卷积运算器件和方法(Buffer Device and Convolution Operation Device and Method)
美国专利:人工神经元及其控制方法(Artificial Neuron and Controlling Method Thereof)
3
2017年
美国专利:多层人工神经网络及其控制方法(Multi-Layer Artificial Neural Network and Controlling Method Thereof)
美国专利:3D集成电路(3D Integrated Circuit)
IEEE论文:用于物联网的可重构流式深度卷积神经网络加速器(A Reconfigurable Streaming Deep Cconvolutional Neural Network Accelerator for Internet of Things)
UCLA论文:硬件机器学习系统电路不确定性综合解决方案(Comprehensive Solutions to Circuit Uncertainty for Hardware Machine Learning System)

《崛起的超级智能》一书主要阐述当今天人类为人工智能的春天到来而兴奋,为人工智能是否超越人类而恐慌的时候,一个更为庞大、远超人类预期的智能形态正在崛起,种种迹象表明50年来,互联网正在从网状结构进化成为类脑模型,数十亿人类智慧与数百亿机器智能通过互联网大脑结构,正在形成自然界前所未有的超级智能形式。这个新的超级智能的崛起正在对人类的科技,产业、经济,军事,国家竞争产生重要而深远的影响。
作者:刘锋? ?推荐专家:张亚勤、刘慈欣、周鸿祎、王飞跃、约翰、翰兹
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
??如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 人工智能学家
人工智能学家
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675