点击阅读原文进入 ? 为了挣到10000块,他在VSRC投了一篇稿!

【技术分享】唯品会图卷积算法简介和应用
鸣 谢

VSRC感谢业界小伙伴——sneutrino 分享原创类文章。VSRC欢迎精品原创类文章投稿,优秀文章一旦采纳发布,将有好礼相送,我们已为您准备好了丰富的奖品!
(活动最终解释权归VSRC所有)

1、基本介绍
近几年来,深度学习取得了突破式的进展,特别是在图像处理和机器翻译领域。在这里面扮演关键角色的是卷积神经网络。
卷积神经网络可以非常有效地处理网格状结构类数据,即数据有规律的分布在一定区域。比如对于彩色照片,由R,G,B三基色矩阵构成,每个矩阵的尺寸为照片尺寸,矩阵元描述该像素点红(绿、蓝)的程度,矩阵元的取值范围为0-255的整数;对于机器翻译,输入的数据结构为词向量组成的序列。
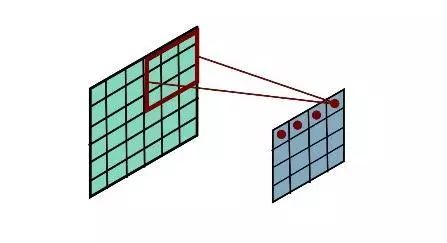
图1:CNN卷积过程
对于这类网格状的数据,通过训练尺寸统一的局部过滤器(filter),将过滤器作用在输入数据的各个区域,从而为后续的计算提取出需要的特征。如图1所示。
1.1
图类型数据和神经网络
然而在工程生产的过程中,存在大量的无法表示为网格拓扑结构的数据,比如,社会网络,生物网络,蛋白质结构等,这类数据的特点在于:数据结构上没有固定的拓扑结构,不像照片那样为固定的网状结构,即每个顶点周围的顶点不具有明确的顺序性,比如对于照片中的每个像素点,其周围的像素点可按照一定的空间位置顺序排序(从左到右,从上到下);而图类数据不具有这类特点,比如在社会关系网络中,每个顶点(node)的邻接顶点无法通过空间位置信息进行排序。同时,每个顶点周围的邻接点的数目也不固定,这导致无法像处理照片那样建立卷积神经网络--通过训练通用的同一尺寸的过滤器来自动提取特征。
图卷积神经网络便被用来处理这类数据,这类问题中,有一类为半监督学习,对图上的每个顶点进行分类:图上的顶点只有少部分具有标签(label),其余的无标签数据都是待分类数据;顶点之间由无向边(edge)互相连接,表明顶点和顶点之间具有某种联系。图2即为图(graph)的直观表示。
传统的神经网络(NN)分类往往将每个数据样本本身的高维特征输入到多层神经网络内,通过逐层向前传播不断提取信息,最后进行分类,然而其不足在于无法利用关联数据。对于图卷积神经网络(GNN),在每一次向前传播的过程中,隐藏层的特征还与其临界点有关。
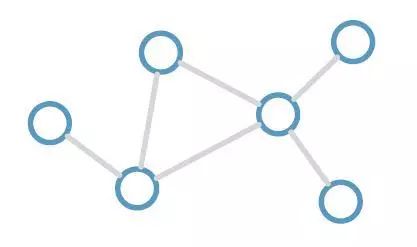
图2

2、常用的算法
如今已有大量算法处理图类数据。本文将介绍两篇近期比较流行的文章:Tomas N.Kipf的 Semi-supervised Classification with Graph Convolutional Network和 Peter Velickovic的Graph Attention Network。
我们首先简单介绍GCN和GAT算法,了解二者之间的关系。随后,我们介绍一下在唯品会安全场景下我们对GCN算法的应用,以及程序和训练参数设置。最后是我们的总结和展望。
2.1
图的数学表示
为了简单考虑,只考虑无向图。对于无向图,其为顶点和边的集合,每个图有N个顶点 ,以及一系列的边
,以及一系列的边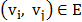 。通过图上的关联关系,可以得到N*N的邻接矩阵A,同时通过邻接矩阵还可以得到对角矩阵度矩阵
。通过图上的关联关系,可以得到N*N的邻接矩阵A,同时通过邻接矩阵还可以得到对角矩阵度矩阵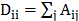 。对于邻接矩阵当顶点和顶点相连时,
。对于邻接矩阵当顶点和顶点相连时,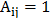 ,否则
,否则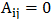 ,所以邻接矩阵描述了图中顶点之间的连接情况。度矩阵则描述了对于每个顶点有多少个顶点在它周围。这些是非常直观的数学解释。
,所以邻接矩阵描述了图中顶点之间的连接情况。度矩阵则描述了对于每个顶点有多少个顶点在它周围。这些是非常直观的数学解释。
通常情况下会对邻接矩阵考虑自连接,所以使用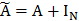 ,其中
,其中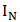 为N*N的单位矩阵,表示每个点都和自己连接;同时度矩阵可以重新定义为
为N*N的单位矩阵,表示每个点都和自己连接;同时度矩阵可以重新定义为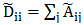 。
。
2.2
图卷积
图卷积可以表示为:
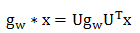
参考Kipf的文章,文章中计算得出了如下近似:
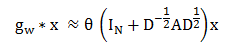
其中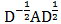 为归一化的邻接矩阵。可以发现,数据的特征矩阵
为归一化的邻接矩阵。可以发现,数据的特征矩阵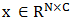 (N个顶点,每个顶点有C维特征),卷积后得到了如下新的特征矩阵:
(N个顶点,每个顶点有C维特征),卷积后得到了如下新的特征矩阵:
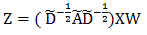
这里Z为N*F的矩阵,卷积核W为C*F的矩阵。上式等号右边可以看作三个矩阵的相乘, 项和前馈神经网络的特征提取一样;不同之处在于
项和前馈神经网络的特征提取一样;不同之处在于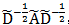 ,展开后表示为:
,展开后表示为:
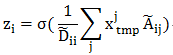
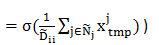
由于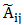 只在顶点
只在顶点 的邻接点和自身处取值为1,其余为0,所以求和只对邻接点以及自身进行,最后的特征
的邻接点和自身处取值为1,其余为0,所以求和只对邻接点以及自身进行,最后的特征 为邻接点(包括自身)临时特征
为邻接点(包括自身)临时特征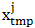 的算术平均。
的算术平均。
2.3
半监督顶点分类学习
顶点的分类问题是半监督学习任务:只知道图中部分顶点的标签,需要将无标签的顶点进行分类。
图卷积神经网络的每一层卷积结束后使用ReLU激活函数:
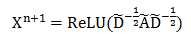
最后一层使用softmax函数进行分类:

?其中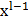 为倒数第二层的输出结果。
为倒数第二层的输出结果。
进行模型训练,损失函数(loss function)为交叉熵函数,由于在图中只有部顶点带有标签,所以最后的求和只对有标签的数据进行求和:
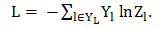
2.4
自注意力机制改进:GAT
通过上面的介绍可以看出,以上的方法有改进的空间。GCN算法在计算隐藏层特征时,邻接顶点对该顶点有等权重的影响,但实际情况中并非如此,可以利用两两顶点的特征计算关联的重要性。
在Velickovic的文章中,作者引入了自注意力机制(self-attention),用于优化隐藏层的特征的计算,该算法为GAT算法。任意顶点的不同邻接点,其对隐藏层的特征计算的权重是不一样的。比如,单个顶点的输入特征向量为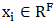 时,进行一次卷积计算后,可以初步得到特征:
时,进行一次卷积计算后,可以初步得到特征: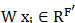 ,随后进行卷积计算。在上面的GCN算法中最后确定的特征为:
,随后进行卷积计算。在上面的GCN算法中最后确定的特征为:

这里n表示该顶点的邻接点个数,求和的对象包括该顶点本身。而在GAT算法中,隐藏层特征表示为:
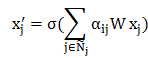
不同邻接点对该顶点的影响是不一样的,我们可以构建通用的神经网络,用于计算自注意力系数 。接下来我们计算自注意力系数,该系数的求取使用的是单层的向前传播神经网络,激活函数为LeakyReLU,其输入为顶点和邻接点的特征:
。接下来我们计算自注意力系数,该系数的求取使用的是单层的向前传播神经网络,激活函数为LeakyReLU,其输入为顶点和邻接点的特征:
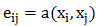
该公式计算了顶点j对顶点i的重要程度。对所有邻接点(包括自身)计算完该系数后,我们可以利用softmax函数对所有的注意力系数进行归一化:
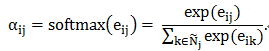
在得到归一化的注意力系数之后,我们便可以简单得到维数为k’的隐藏层的新特征。
为了能够让学习的过程具有较好的稳定性,文章中使用了多头注意力机制:即使用K个注意力机制的神经网络,它们得到的结果合并起来形成隐藏层的特征向量,从而进一步修正上面的公式,我们可以得到:
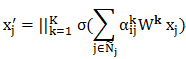
这样,我们新得到的隐藏层的特征维数为KF’。这里,(公式)为连接算符,将两个高维向量连接为一个更高维的向量。这个多头计算过程有点类似于CNN中,每层卷积都使用了多个卷积核,多个卷积核的作用就是为了提升模型的稳定性以及提取尽可能多的特征。
而对于输出层,如果我们采用和隐藏层一样的多头注意力机制,则不能简单的将每个头的输出进行拼接,文章中采用了输出特征平均的方法,随后使用softmax函数来作为激活函数,用于分类。
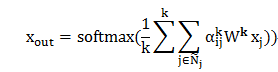

图3:注意力机制下的注意力系数计算和隐藏层特征计算
2.5
算法总结
常规的神经网络算法中,我们通过输入样本实例的特征,逐层向前传播提取有用信息,最后给出分类结果,这类方法已经取得了很大的成功。但是许多数据,实例和实例之间还有各种关联,常规的神经网络无法利用这部分信息。
GCN算法改进了常规的神经网络算法,将实例之间的关系利用起来,每个样本在隐藏层的特征不仅仅和自己的特征有关,还和其关联样本的特征有关,每个样本点在隐藏层的特征是其自身新特征和邻接点新特征的算术平均。但由于关联信息在算法中的利用只是关联点特征的算术平均,这点值得优化。
在GAT算法中,使用了自注意力机制,样本点的隐藏层特征是自身新特征和邻接点新特征的加权平均,其权值由每层通用的神经网络决定,该神经网络的输入为相关联的两个顶点的特征,为单层神经网络,这样可以很好的反映不同邻接点对顶点的影响程度,同时,每层使用了多头的自注意力神经网络,这种多头设计非常类似于CNN中,每层卷积使用多个卷积核,这样可以进一步增强模型的稳定性。
可见GCN和GAT都极大的利用了数据样本之间的关联信息,相比常规的NN算法而言,更有效的挖掘了数据所的信息。同时GAT相比于GCN,使用了多头的自注意力机制,进一步优化了隐藏层的特征更新。

3、我们的应用
3.1
应用场景
在唯品会购物平台上,大多数用户都是正常用户,少部分为非正常用户,有的往往注册多个小号,成为马甲用户;有的代客下单;有的直接使用机器行为抢购商品。这些非正常用户影响了我们公司的运营,更重要的是影响了其他正常用户的购物体验,许多优惠商品和高价值的商品都被这些非正常用户一扫而空。
对于所有的注册用户,我们根据他们的不同种类的行为进行不同评分,一般有几类,比如注册评分,登陆评分等等,评分过高的用户普遍为可疑用户。同时,用户之间可以通过各种方式关联起来,比如使用的设备,电话号码,收货地址等。
在这个由用户组成的关系图中,一些较新的用户暂时没有太多评分,一些很老的用户得分也不是很全,还有一些用户有评分但是介于正常和非正常得分之间。为了挖掘这部分用户的性质,我们可以使用他们的关联数据进一步得判断。
3.2
模型构建
为了进一步挖掘恶意用户,我们尝试利用这些关联数据。作为简单尝试,我们使用GCN算法,其包含:四个输入单元,为四类评分方式的得分;包含了三个隐藏层,每层隐藏层包含32,8,4个激活单元,使用ReLU激活函数;由于是二分类问题,输出层包含两个输出单元,最后的分类使用softmax进行分类。学习效率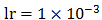 ,为了防止过拟合,我们使用dropoup = 0.15。同时我们设置epoch = 2000。
,为了防止过拟合,我们使用dropoup = 0.15。同时我们设置epoch = 2000。
我们首先挑选近期活跃用户,以及和他们有一度关联的用户,将他们四类用户评分作为输入,对于评分只要存在非常高得分的(大于等于90分以上)的用户作为马甲用户,评分都低于30分的用户作为正常用户,介于这二者之间的、以及没有得分的为待评估用户。
3.3
程序
使用的程序为kipf在github上的代码,下载地址为https://github.com/tkipf/gcn,该代码需要tensorflow和networkx两个库。
我们的模型输入包含三个pickle文件:1)表明用户之间关系的文件,为字典格式,字典的键为用户UID,字典的值为与其相关联用户组成的集合;2)用户得分文件,为numpy array格式,记录了每个用户的三种评分;3)用户标签文件,为numpy array格式,记录每个用户的标签,为one-hot表示,负样本为[1, 0],正样本为[0, 1],对于那些缺乏标签的用户设定为[0, 0]。
首先导入数据,我们首先利用networkx处理第一个pickle文件,得到邻接矩阵。由于可使用数据充足,我们将全量数据分成三等分:training,validation,testing。原程序中使用的数据为sparse matrix,我们的输入数据和处理后得到的数据均为sparse matrix类型。
在特征预处理过程中,由于各种得分的跨度较大,为了均衡处理每种得分在损失函数中的权重,我们使用了sk-learn中的StandardScaler类,利用该类的transform方法让每个特征分布在0到1这样一个区间里面:

对于模型部分,Layer的定义至关重要,可参考原程序GraphConvolution 类的定义:
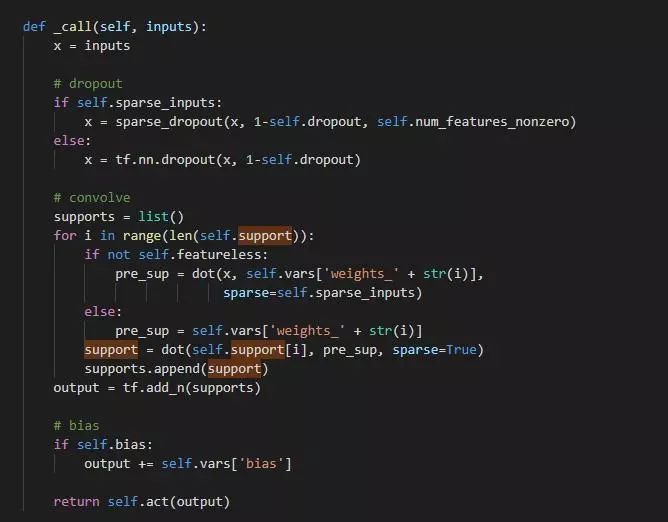
图卷积类中最重要的是私有方法_call(最后被特殊方法__call__调用,这样该类可以像函数那样调用),首先实现的是dropout;随后根据GCN中卷积计算公式,分别进行sparse矩阵相乘:权重和输入相乘得到初步隐藏层特征,随后支持度矩阵和初步隐藏层特征相乘,得到输出;最后,如果需要加入偏执,则最后在output中加入偏执。
由于原代码中只实现了两层图卷积,我们重新实现了多层图卷积神经网络,从而方便实现任意层数的卷积神经网络:

进行训练,最重要的是定义损失函数:
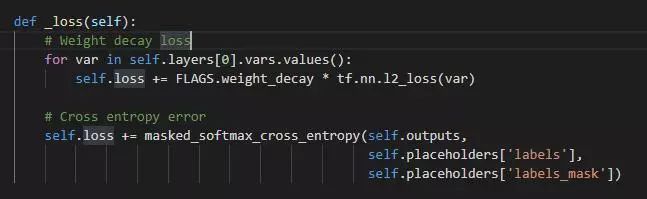
损失函数分成两部分,第一部分使用weight decay,确保权重都是较小的值,第二部分则是模型预测结果的交叉熵,由于我们只关心打了标签的数据,所以最后的交叉熵关注的是有标签实例。
在预处理完成数据之后,我们的便可以开始常规的tensorflow模型训练过程。
3.4
训练结果
训练后我们发现,该模型的正确率为0.959,准确率为0.979,召回率为0.940。同时我们输出那些被“误判”的正常用户,发现,他们普遍存在问题,比如和上百个用户关联,或者其关联的十多个用户中一半以上是非正常用户等等。

4、展望和总结
本文介绍了最近比较流行的GCN和GAT算法,相比于传统的DNN算法,GCN和GAT考虑了样本点之间的关系,提取出了更多的信息。而GAT相比于GCN,使用了注意力机制,从而可以量化样本点之间的关联强弱,优化了隐藏层的特征提取,可以有效的提升模型的健壮性。
在这两类模型中,都只是考虑了顶点的特征,在GAT中,注意力权重也只是和两两顶点的特征相关,而没有考虑边(关联方式)的特征。而在关联方式中,依旧存在大量的信息值得我们去挖掘和提取。
本文暂时只是使用了GCN 算法,在后期,我们也将尝试GAT算法,以及尝试其他图卷积算法,比如考虑边的性质。
。
。
精彩原创文章投稿有惊喜!

VSRC欢迎精品原创类文章投稿,优秀文章一旦采纳发布,将为您准备的丰富奖金税后1000元现金或等值礼品,上不封顶!如若是安全文章连载,奖金更加丰厚,税后10000元或等值礼品,上不封顶!可点击“阅读原文”了解规则。(最终奖励以文章质量为准。活动最终解释权归VSRC所有)
不知道,大家都喜欢阅读哪些类型的信息安全文章?
不知道,大家都希望我们更新关于哪些主题的干货?
现在起,只要您有任何想法或建议,欢迎直接回复本公众号留言!
精彩留言互动的热心用户,将有机会获得VSRC赠送的精美奖品一份!
同时,我们也会根据大家反馈的建议,选取热门话题,进行原创发布!
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 唯品会安全
唯品会安全
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675