
数字化转型之解决方案篇 | 基于 QingStor®️ 对象存储的数据湖解决方案
据 IDC 最新报告预测,2022 年中国 50% 以上的组织都将成为数字化坚定者,依靠新的商业模式、数字化产品与服务实现业务增长。
面对数字化转型的时代浪潮,青小云为大家准备了一份硬核大礼 —— 《数字化转型之路》,包含基础设施、业务架构、解决方案到行业实践、未来探索五个部分,该系列是对数字化转型理论与具体实践路径的系统梳理,希望帮助读者全面准确把握数字化转型发展趋势与前沿技术,促进企业与组织能够在变革的数字化世界中创造更大的价值,实现更强健的生命力。?

今天与大家分享的是《数字化转型之路》中解决方案篇——基于 QingStor? 对象存储的数据湖解决方案。
以下是分享正文:
1
数据湖
大家非常熟悉大数据的概念,但可能没听说过数据湖。实际上,数据湖和大数据是紧密联系在一起的。
数据湖在学术上的定义,是一种在系统或者存储库以自然格式存储的方法。它有助于存储各种模式和结构形式的数据,通常是对象块或者文件。
为什么现在会提出新的自然存储格式方法?以前我们如何存储数据?
在使用数据仓库时,我们要经过大量 ETL、数据标准化、数据整理的过程,换句话说,它要做大量数据的工作。
而正是因为大数据的产生,我们提出了数据湖的概念。
大数据来了,它就像水似的,我们无法把水存在传统的仓库里。一是它太大了,二是它很廉价,三是它的形态不一样了。大数据速度太快,就像洪水一样,一下过来了,在使用过程中没法做减库、入库的动作,要快速以自然的格式存储。
因此,传统数据仓库存的是结构化数据,数据湖里存的是非结构化、半结构化的数据。
2
数据湖最佳实践报告
接下来是如何使用数据湖,以及使用数据湖会遇到什么问题。

这里引用 TDWI 的报告,这份报告统计了美国两三百家企业,企业核心分布在金融、咨询等主要偏传统的各个行业,规模是 1 亿美元以上到 100 亿美元以下,算是中档企业。
人们为什么用数据湖?

采用数据湖的原因,一方面是刚才谈到的大量非结构化数据,从图中可以看到现在有社交媒体、传感器等数据。
另一方面原因是为了做机器学习和人工智能的分析使用。其中还有新的驱动型实践,比如数据探索和发现,传统的数据仓库更多的是看一个报表。
新的数据探索像数据科学家在数据湖里自由探索,而不是所有人都加工一个报表。
至于大数据产生的业务价值,数据湖的产生会把数据仓库的一部分功能移植到数据湖中,数据湖的成本比数据仓库的成本更低廉。
数据仓库有大量的模型、ETL、数据治理等工作,数据湖比数据仓库简单,大家用更原始的方式堆到湖里,那么数据湖以后要替代数据仓库吗?
使用数据湖遇到的问题

Gartner 在一份报告中指出,没有经过数据治理的数据湖大部分会沦为数据沼泽。
为了更好的理解数据沼泽的问题,我举一个例子,比如大家用手机拍照,可以随便拍,但拍完后过一段时间会发现里面的大部分照片都没什么用,有拍了风景或者拍坏拍虚的照片,这些照片没有经过管理、没有打上标签,最后整理照片是很痛苦的过程。
有大量数据时,你要找到所需照片时是很困难的。这就和今天的数据湖一样,由于数据湖的价格低廉,收集的数据很多,大家在数据湖里堆积了大量重复数据以及数据质量低下的数据,这就会沦为数据沼泽。

虽然有缺点,但如上图,在调查过程中,接近一半的人认为使用数据湖非常紧迫,四分之一的人认为已经部署了数据湖,另外四分之一的人会在一年内部署数据湖。

很多人把传统数据放在数据湖里,数据湖不光有原始数据,它也有大量的数据加工。它的数据量在不断增加,逐步迈向 PB 级。
从数据管理来说,数据湖还是由传统的数据仓库团队管理和 IT 部门管理,业务部门只占少数。大部分是工程师、架构师、分析师在用数据湖,业务员和非技术人员用得比较少。

从架构和平台的采纳方面来说,目前数据湖以 Hadoop 为多,传统数据可以采用关系型数据湖,二者结合使用的也很好。

3
云端数据湖解决方案
刚才分享的是机构报告,现在我们讲讲云上的数据湖。
HashData 云端数据湖

在青云QingCloud 上的数据湖如上图,包括几块:存储、分析、搜索。
存储我们用的是 QingStor??对象存储。分析用的是 HaseData V2 版本计算引擎。数据摄取用的是 QingMR,结合 Kafka 做存储。机器学习,我们除了配有 QingMR Steaming 和 SparkMR,还有一个 SQL 机器学习的工具,下面逐一展开。

在存储方面,大家对数据湖的需求是数据湖要存得住、存得起。
对象存储支持海量的数据存储,可以无限扩展,存大数据没问题。
存得起,就要我们提供一个经济实用的存储。如上图,对比了块存储,用的是磁盘和 SSD,和对象存储,它们的成本有 5-10 倍差异。从存储角度来看,如果用对象存储会大幅降低数据湖的存储成本。
其中有一个问题,存储成本降下来了,如何保证你的计算性能?我们不能为了用更廉价的产品,让客户体验更差的服务。
从计算层面,我们采用了 V2 架构。

分享一个物联网客户的故事,我们当时用了 v1 版本在块存储磁盘上,客户大概有 2 万的 IoT 传感器设备,每时每刻都在不断地产生数据,数据膨胀得非常厉害。他们说这样做我们的预算有点超支,能否做一个方案把成本降下来?
当时我们和青云一起讨论做一个方案:能否把一部分数据,比如近六个月的数据放在块存储上,把之前的历史数据放在对象存储上?
我们做了一个接口,通过手工的动作存储到对象存储上,另一块放在块存储上。这是一个简单的数据温度的管理,把冷数据放在对象存储上,把热数据放在块存储上。
我们把这个工作通过系统自动完成,更频繁一点,把成本降得更低一点,要知道六个月的数据也是很大的。通过计算引擎,先把数据存下来,当跑运算的时候会把它抓取。
接下来看一个测试,TPC-H 测试,这边采用 100G 的数据。
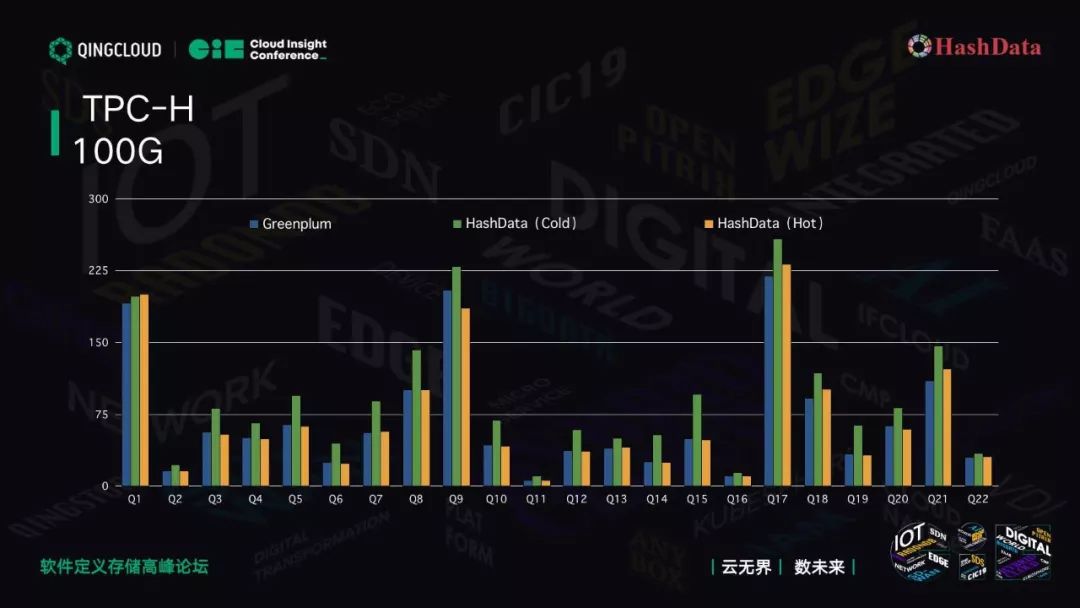
我们用了八个节点虚机,用低廉的 4C8G 做 TPC-H 测试。
在测试过程中,我们的内核使用 GreenPlum,GreenPlum 用了磁盘的块存储。HaseData(Cold)是我们新的 V2 架构,蓝色部分表示是第一次跑,黄色部分表示是跑完一次,第二次缓存抓住了。对象存储比块存储 IO 低很多,Q7 差一半左右。一旦缓存抓住后,Hot 的部分相差无几。Q9 比传统的块存储更好。
通过分级存储机制,既大幅降低了存储成本,又保证了查询性能。
下面分享第二个故事。
我们在做用户行为分析、网络日志分析时,经常会遇到这样的情况:电信客户有 1PB 的数据,是基于传统块存储实现的(如 Hadoop、GreenPlum,给它配一两百个节点)。大数据有一个特点,比如我有 1PB 的存储,我分析时 99% 只分析一天的数据,可能只分析 1T 或者 100G,这是数据密度的问题。我们要解决存储问题,所以要做计算存储分离的架构。
首先,把它存出来。计算层的计算量很少,如果配 100 个节点大多就浪费了。我们在存储上把 1PB 存起来。计算时只用 10-20 个节点就可以完成计算任务,你会节省 80-90 台机器,大量节省硬件资源。这是计算和存储分离的意义。
我们的架构继承了 GreenPlum 体系,还是用 SQL 解决问题。这简化了数据湖的使用,大家都喜欢用 SQL,我们进一步面向业务人员。

大数据来了,其实时性要求比较高。除了传统可以用对象存储存 API 接口、Python 接口外。实时部分,大家用得比较多的三个工具:Storm、Spark Steaming 和 FLink。我们主要比较两块,Spark Steaming 和 Storm。
实时性,Spark Steaming 从计算模型来看是准实时,它会等一秒钟,比如来了 10 万条数据,我一次性批量写进去。Storm 是实时的,你来一条数据,它处理一条实时数据。从延时来看,Storm 达到毫秒级,Spark Steaming 达到秒级。
存储量,Spark Steaming 更大一点,它更符合大数据的处理。秒级接受,一般在我们碰到的应用场景是可以接受的,比如它攒到 10 万或者几万条,批量写入,不需要每条写。我们标配是采用 Spark Steaming 做实时数据的摄取。

机器学习分析,Spark MLab 这一块是通用的。我们更多的是做 MADlib,MADlib 是 Apache 的顶级开源项目,只在 PostgreSQL 和 GreenPlum 体系里可以用。
它的特点是基于 SQL,以前用 Spark 做机器学习,要么用 Python,要么用 Skyline 或者 R。SQL 是大部分都会用,学一两周都会用,这种比较专业。
其特点是简单上手,具体功能 Spark 能做的,它也可以做。同时,它是 In Database 的数据分析,我的数据湖就在我的平台上,如果要采用另外的工具分析,它会先把数据拿过去,做完分析再拿过来,这里有大量的数据交换。它在 Base 里减少数据交换,并且可以充分利用 HaseData 的并行计算,可以保证其性能。
4
云端数据治理和数据安全
前面谈到数据治理和数据安全。HaseData 秉承 PostgreSQL 和 GreenPlum 完整的权限管理,如 Table、Database、Funtcion 等。

角色结构,在大企业里对几千人进行授权可以先到角色,通过角色再到具体的权限。

更安全的管理可以用视图做隔离,用视图精细到资源级的权限。这都是 PostgreSQL 和 GreenPlum 数据库的部分。

元数据管理,存到 HaseData 里的表和字段,除了存到数据节点上之外,还会把元数据存到 Global Catalog 上,这时候数据治理工具或者 DPU 管理员清楚地知道我们存到数据湖里有哪些数据,什么时候存的,数据有多大都能一目了然,数据治理非常方便。

主要应用场景,前面谈到第一步应用场景是工业数据湖,工业数据湖 IoT 有大量的数据做分析、预测性维修等。另一部分是电信用户行为分析、日志分析。
其中还有一块是交通大数据,比如卡口信息,在工作范围大量拍照,拍照后人工智能摄像头可以很方便地把牌照信息进行结构化处理解析出来,结构化的存到 HaseData 上,如牌照、车牌颜色等都存在数据库里,进一步分析其流量、高速公路缴费信息。

谈到摄像头,我们在安防领域有一些应用,摄像头拍摄人脸识别后会转成结构化数据,做查询、分析时可以用到。

总结来说,HaseData 的优势是,我们把它放在对象存储,成本降下来了,同时保证性能不变。
同时我们继承了云的特点,通过鼠标操作就可以在几分钟内把集群起起来,不需要花一两天的工夫安装部署。技术生态秉承了原来 GreenPlum、PostgreSQL 这种用 SQL 解决问题的思路。弹性,我们支持在线扩容,如果 10 个节点计算不够,可以扩到 20 个,需要多少用多少。
更多详情请扫码或点击阅读原文查看

K8S 落地实践系列技术沙龙:

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 QingCloud
QingCloud
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675