
超强图形性能护航5G时代,解析ARM Valhall GPU 架构及Mali-G77
ARM今年的新品不但有新的CPU架构,还有全新的GPU架构。在今年的年度发布会上,ARM公布了全新的GPU架构,也带来了全新的GPU型号Mali-G77。随着移动产品的应用范围和适应场景不断扩大,ARM也在积极调整产品以满足越来越大的计算量需求。Valhall GPU架构和Mali-G77就是为应对这样的情况而生的。本文将带来ARM这一新架构的深入解读。

▲ARM Mali-G77正式发布
ARM上次发布新的GPU架构还是在大约3年前。随着近年来技术和应用的发展,ARM是时候推出全新架构了,这就是我们今天要谈的“Valhall”架构。从ARM给出的资料来看,Valhall架构在性能、密度和效率方面有着重大改进。虽然部分改进在去年的Mali-G76上就已经出现,但是架构级别的全面改进,则在采用Valhall架构的Mali-G77上才会全部显现。
实话实说,ARM在移动GPU设计上的底蕴并不深厚,一个典型的例证就是ARM前几代移动GPU无论是架构还是产品的表现都不够出色,这样的情况一直持续到Biforst架构出现,但是Biforst架构的前两款产品依旧存在不少问题。

首款Biforst架构的GPU是Mali-G71,它发布于2016年,华为海思旗下的麒麟960和三星Exynos 8895两款SoC使用了这款GPU。当时人们对这款GPU报以非常高的期望,毕竟这是ARM在GPU架构上做出的重大变化—Biforst是ARM首个标量GPU架构,彻底改变了之前的矢量GPU设计。
在桌面GPU上,类似的改变这发生得比较早,包括英伟达在大约十年前推出的Tesla(GT200系列)架构以及AMD在大约五年前推出的GCN架构,都是由矢量转换为标量计算,基础架构的变化代表的是未来的发展方向。
Biforst也做出了这样的变化,但是Biforst架构的产物Mali-G71和Mali-G72表现并不出色,甚至对三星和华为的产品规划带来了负面影响,比如麒麟960和麒麟970在GPU性能方面的表现令人失望,尤其是面对来自高通骁龙的同代次产品时。
好在ARM也看到了这样的情况,在Biforst架构的最后一次迭代也就是第三款产品上,解决了部分问题,带来了性能的飞跃。Mali-G76的表现大大提升了ARM GPU在消费者心中的地位,并且改善了Exynos 9820和麒麟980的性能,使得这两款SoC能够更好地面对激烈的市场竞争。
但是,Biforst架构的迭代和Mali-G76的出现,并不意味着ARM在移动GPU市场中的情况变得更好了。实际上,其竞争对手的进步速度更快。高通的Adreno移动GPU架构一直以来都在引领着移动GPU的发展,尽管今年的Adreno 640并没有取得令人印象深刻的性能改进,但是它的能效比、密度和绝对性能依旧领先ARM的相应产品。另外,苹果全新A12 SoC的GPU能效比表现更是相当出色,远远领先目前市面上的几乎所有竞争对手,包括高通和ARM。移动SoC市场的竞争激烈程度可见一斑。
Valhall在架构层面带来了全新的变化,包括新的ISA和计算核心设计。这些设计可以解决Biforst的主要缺点,并且看起来它和其他移动GPU供应商的设计思路更为相似了。Valhall的第一次迭代产品就是Mali-G77,接下来本文将讨论Valhall架构的设计和改进方向。

▲Valhall带来了大量全新特性和全新的Mali-G77
根据ARM提供的数据,Mali-G77相比前代产品Mali-G76,其能效比提升30%,面积密度提升30%,机器学习性能提升60%。综合性能增加40%。另外值得一提的是,由于下一代SoC在工艺上进步不大,因此其性能提升主要来自架构设计,也就是Valhall和Mali-G77的架构优势。

▲Mali-G77的性能提升情况
全新的Valhall架构和前代产品存在显著差异,虽然其架构本质依旧采用了标量涉及,但和Biforst异常狭窄的4宽度和8宽度不同的是,Valhall的执行核心架构更类似于AMD和英伟达的桌面GPU产品。

▲Valhall架构总览
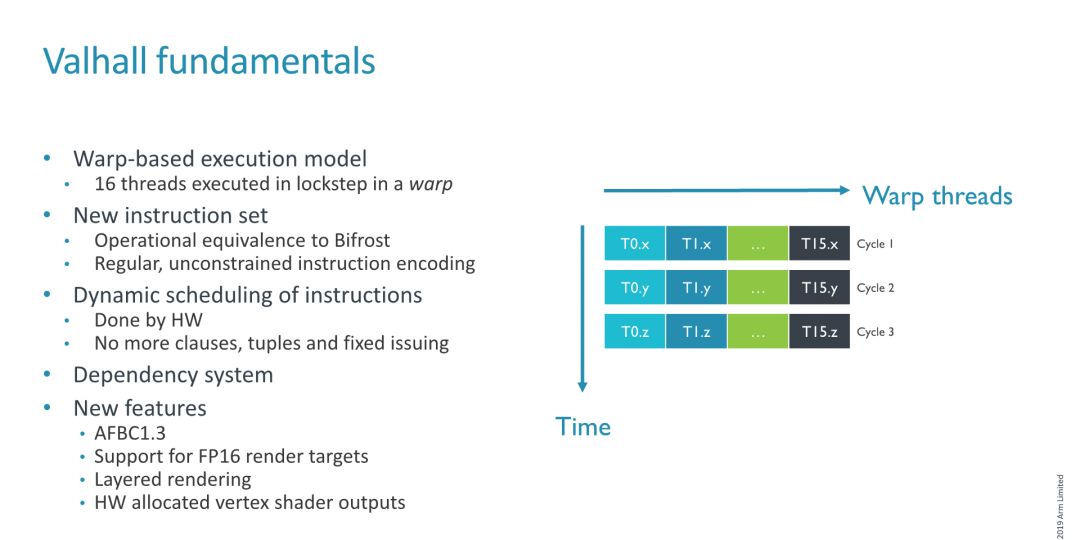
前代Biforst架构的Mail-G71和Mali-G72在核心执行架构上的设计比较紧凑,采用了4宽度的SIMD单元组成,其波前阵列(warp)宽度也为4。在Mali-G76上,ARM将波前阵列尺度提升至8,相比前代产品翻了一倍。所谓波前阵列宽度,是指处理器一次能够吞吐多少数据。
在计算中,数据的长度往往会根据实际计算而变化,可能是2、4、8、16等,逻辑控制单元需要拆分、合并一个或者多个计算数据,并打包成波前阵列所需要的长度后,才会将数据导入波前阵列,等待进入计算单元。如果波前阵列设计得过宽,那么在面临大量小数据计算并存在一定相关性时,可能无法完全填充GPU核心,造成浪费。
较小的波前阵列可以避免这个问题,在某些情况下能够提高单元工作效率,但是在大量长度较长的数据来临时,较小的波前阵列设计反而会成为计算瓶颈,逻辑控制单元需要不断拆分数据以适应较小的波前阵列设计,瓶颈将转移至逻辑控制单元。此外,较小的波前阵列需要更多的逻辑控制单元才能满足控制需求,更为耗费晶体管资源。
以当时的眼光来看,移动GPU计算中并没有太高的性能需求,在Biforst时代采用较窄的、4宽度的波前阵列设计能够有效降低ALU上的空闲周期量,同时ARM希望以更多的逻辑控制单元来实现更好的ALU利用率。但是在数年后,这种设计显得有些落伍。
现在来看,移动游戏正在迅速地向更高的计算复杂程度迈进,大量PC移植游戏的存在,以及移动游戏本身对Shader的要求日益提升,加上更多的多线程需求,都使得更宽的波前阵列设计逐渐成为主流。
在这种情况下,新的Valhall架构顺势采用了16宽度的波前阵列。虽然相比英伟达和AMD的32宽和64宽,16宽依旧显得小了一些,但是考虑到这是一款移动GPU并且上代产品只采用了4宽度,这样的改进还是颇为显著了。
▲Valhall架构的基本改进一览
除了波前阵列外,新架构在执行引擎的设计上也有所调整。之前Biforst GPU甚至Midgard GPU在设计上采用的是多执行引擎方案,每个执行引擎将拥有自己的专用数据路径和控制逻辑,自己的调度程序、指令缓存、寄存器文件和消息传递模块,这自然会带来大量的晶体管开销。
在高端GPU上,这样的设计就显得颇为浪费,因为高端GPU往往会采用更多的执行引擎,如果都采用多执行引擎设计的话,每一个执行引擎都有自己的一套“班子”且会进行重复的工作,晶体管会被大量浪费。
Mali-G77改变了这种状况。Mali-G77将前几代的小型执行引擎整合在一个带有共享控制逻辑的大型IP模块中。新引擎的IP设计依然存在一些重复的地方,比如ALU流水线被划分为两个“群集”,每个群集都有自己的16宽度的FMA单元以及相应的执行单元。相比前代方案,这样的设计大幅度降低了晶体管使用量,能够让更多晶体管投入到有效的计算中去。
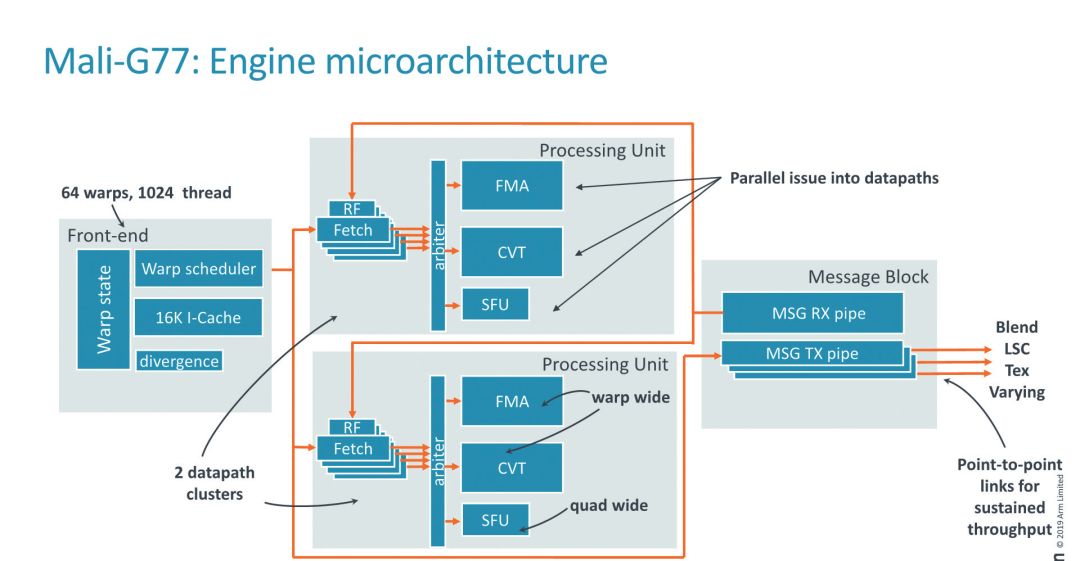
▲Mali-G77的引擎微架构简图
它在ISA方面也有所改变,ARM简化了很多指令。目前还没有更多细节可供参考,但新的ISA更容易编译,并经过重新设计和调整,使得其可以更好地与现代API,比如Vulkan保持一致。和之前在Biforst中使用的ISA相比,新ISA采用了一部分新编码,更为规整和易用。
另外,新ISA在指令调度上带来了重大改进。Valhall架构所采用的新ISA摆脱了固定的issue调度、clauses子句和tuples元组。在Biforst中,ARM将指令的调度委托给编译器,并且将指令分组到所谓的子句中。这种做法在实际应用中的效果尚可,但需要在编译器上投入大量工作才能隐藏指令和数据访问之间的延迟,因此颇为麻烦。在Valhall中,这些编译器的复杂工作都将不复存在。因为ISA的调度将完全由硬件完成,更类似乱序执行的CPU的工作方式。这种设计还意味着ISA和微架构的脱节,更具前瞻性。
新ISA带来了一些其他方面的优化,包括纹理增强能力的加强,几何流的优化和ARM帧缓冲压缩技术的优化等(版本升级至1.3)。进一步深入研究执行引擎的话,可以发现执行引擎分为四个块,分别是:波前阵列调度程序、指令缓存的前端、两个相同的数据路径集群(处理单元)以及和消息块连接的加载/存储单元、固定功能模块等。
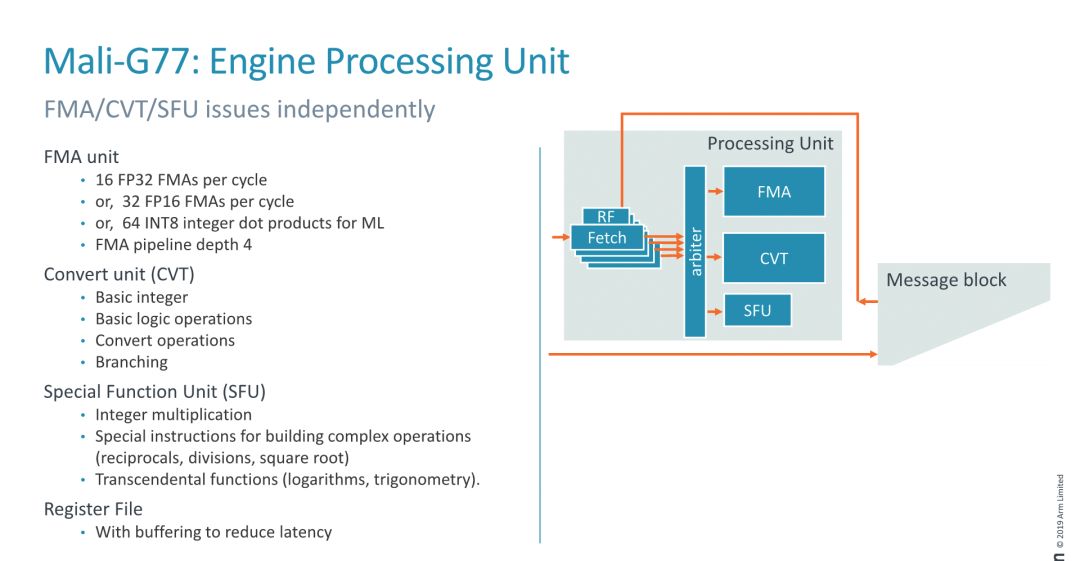
▲Mali-G77的引擎计算单元设计
Mali-G77的前端最多支持64宽的波前阵列和1024个线程。每个处理单元具有3个ALU:FMA和CVT的波前阵列都是16宽度,而特殊的SFU波前阵列采用了4宽度。SFU并不是常用的单元,因此并不需要太大的吞吐量。
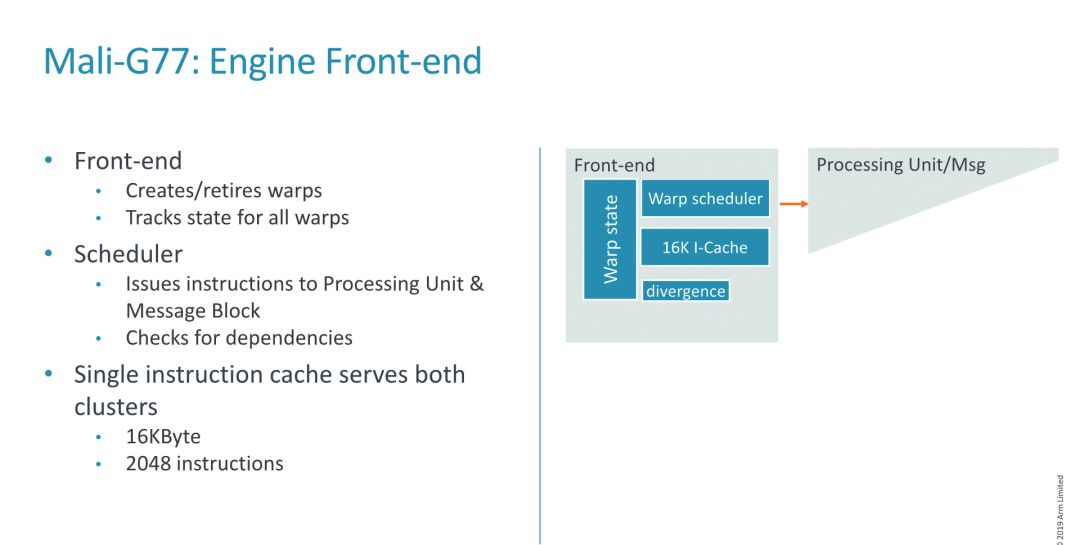
▲Mali-G77的前端设计
Mali-G77的前端可以创建或者退回波前阵列数据,并且为所有的波前阵列进行状态跟踪。另外,Mali-G77前端还增加了一个动态调度功能,这个功能可以决定每个波前阵列将执行哪些指令,还可以将等待中的相关联波前阵列替换为准备执行的无关联波前阵列,尽可能提高执行效率。
指令缓存方面,Mali-G77的前端指令缓存采用的是共享设计模式,并且是16KB、4路关联的方式,支持2048个指令,每周期可以发出4个指令。在实际的处理单元(集群)中,Mali-G77设计了4个可以发送指令到算术单元的拾取单元。每个拾取单元都设计了一个精密耦合的寄存器,以及一个用于减少访问寄存器文件延迟的转发缓冲区。FMA ALU每周期支持16个FP32 FMA,是FP16的2倍,也是INT8点阵的2倍。转换单元处理基本整数操作和自然类型转换操作,同时也会被用作分支端口。
总的来看,相比Mali-G76,Mali-G77的执行引擎资源更为丰富,类似于一台发动机和三台发动机之间的区别。Mali-G77的引擎在主数据路径上有更多的资源,并且控制和指令缓存所占据的空间更少,从而提高了整个计算模块的面积效率。

▲Mali-G77对比之前的Mali-G76
在延迟方面,新架构的ALU延迟将变为4个周期深度,之前的产品为8个周期。这样的变化可以在没有链路操作时提高性能。此外,新核心具有类似超标量的功能,而不是过去的管状设计。由于延迟降低,整个核心流水线必须进行重新设计,这也是编译器简化的重要原因之一,因为编译器不需要再匹配同时发出的指令,大大降低了复杂程度。
受篇幅影响,在后续的文章中,我们将为大家解读ARM Mali-G77架构,及ARM Valhall GPU架构、Mali-G77的设计在转化为性能、效率等各方面的表现,敬请关注。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 微型计算机
微型计算机
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675