
OpenResty 社区王院生:APISIX 的高性能实践

2019 年 7 月 6 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·上海站,OpenResty 软件基金会联合创始人王院生在活动上做了《APISIX 的高性能实践》的分享。
OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。活动将陆续在深圳、北京、武汉、上海、成都、广州、杭州等城市巡回举办。

王院生,OpenResty 社区、OpenResty 软件基金会联合创始人,《OpenResty 最佳实践》主要作者,APISIX 项目发起人和主要作者。
以下是分享全文:
大家好,我是王院生,很高兴来到上海。首先做下自我介绍,我于 2014 年加入奇虎 360,在那时认识了 OpenResty,此前我是一个纯粹的 C/C++ 语言开发者。在 360 工作期间,利用工作闲暇时间写了《OpenResty 最佳实践》,希望能影响更多的人正确掌握 OpenResty 入门。2017 年我作为技术合伙人和春哥(章亦春,agentzh)一起创业。今年我个人的重心有所调整并在今年三月份离职,准备将更多精力投入到开源上,于是发起了 APISIX 这个项目,企业宗旨是依托开源社区,致力于微服务 API 相关技术的创新和实现。
什么是 API 网关
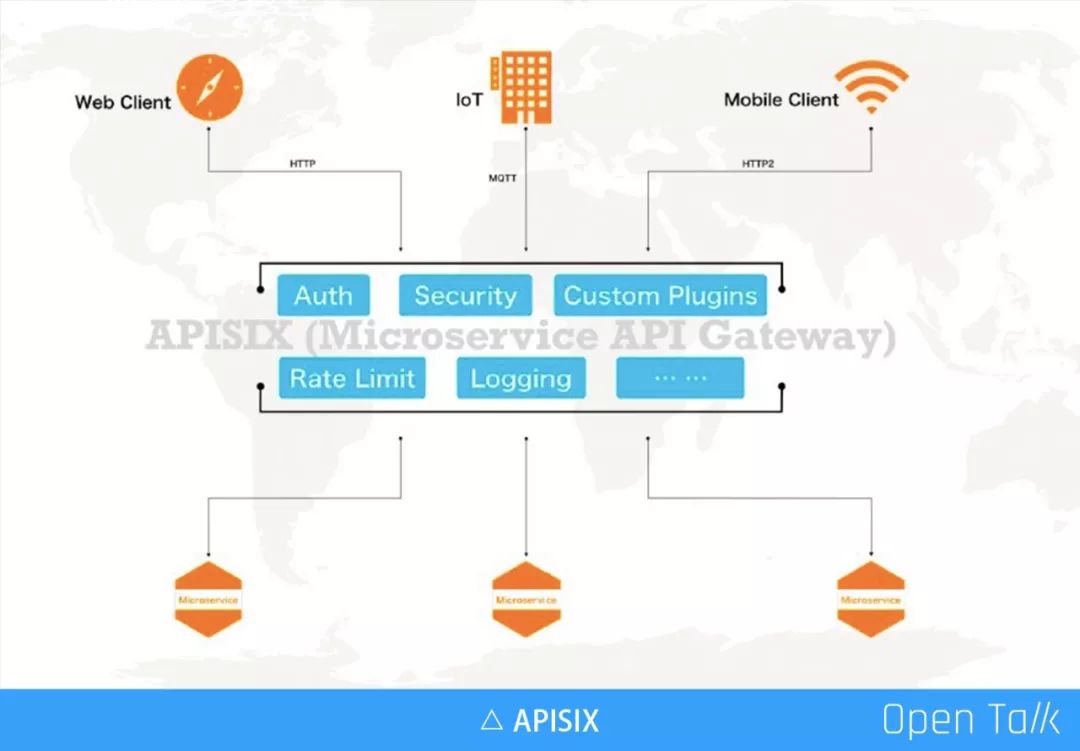
API 网关的地位越来越重要,它几乎劫持了所有流量,内外之间完成了用户的安全控制、审计,通过自定义插件的方式满足企业自身特定需求,最常见的自由身份认证等。随着服务在数量和复杂度上的不断增长,更多的企业采用了微服务的方式,这时通过 API 网关来完成统一的流量管理和调度就非常有必要。
微服务网关和传统意义上的 API 网关有一些不同,主要包括下面几点:
动态更新:在微服务之前,服务不像现在这样经常来回地变化。比如微服务需要做横向扩充,或者故障恢复、热备、切换等,IP 、节点等变动更加频繁。举例如微博上一旦出现了爆点事件,就急速扩充计算点,必须要非常快地扩充新机器来扛压。波峰波谷变化明显,分钟级别的机器动态管理,已经越发是常态。
更低延迟:通常动态就意味着可能会做一些延迟(复杂度增加),在微服务里面,对于延迟要求比较高,尤其对于现在的用户体验,超过 1 秒以上的延迟是完全不可接受的。
用户自定义插件:API 网关是给企业用户使用的,它一定存在私有逻辑(比如特殊的认证授权等),所以微服务网关必须能够支持企业用户自定义插件。
更集中的管理 API:如前面所说 API 网关劫持了用户的所有流量,所以用网关来做统一的 API 管理是非常必要的。在网关角度可以看到 API 是如何设计,是否存在延迟、安全问题,以及响应速度和健康信息等。
我们要做的微服务 API 网关产品,除了上面的基本要求,还有一些是我们区别于其他人的:
通过社区聚焦:通过开源方式聚焦有共同需求的人群,让更多不同公司的人可以一起协作,共同打磨更好的产品,减少冗余开发。
简洁的 core:产品的内核必须是非常简洁的,如果内核复杂,会使得大家的上手成本高很多,望而却步肯定不是我们期望的。
可扩展性、顶级性能、低延迟:这几项都是要同时严格保障的,也是我们会花主要精力保证的。目前 APISIX 项目的性能比空跑 OpenResty 只低 15%,这点还是非常值得傲娇的。
APISIX 高性能微服务网关
APISIX 架构与功能
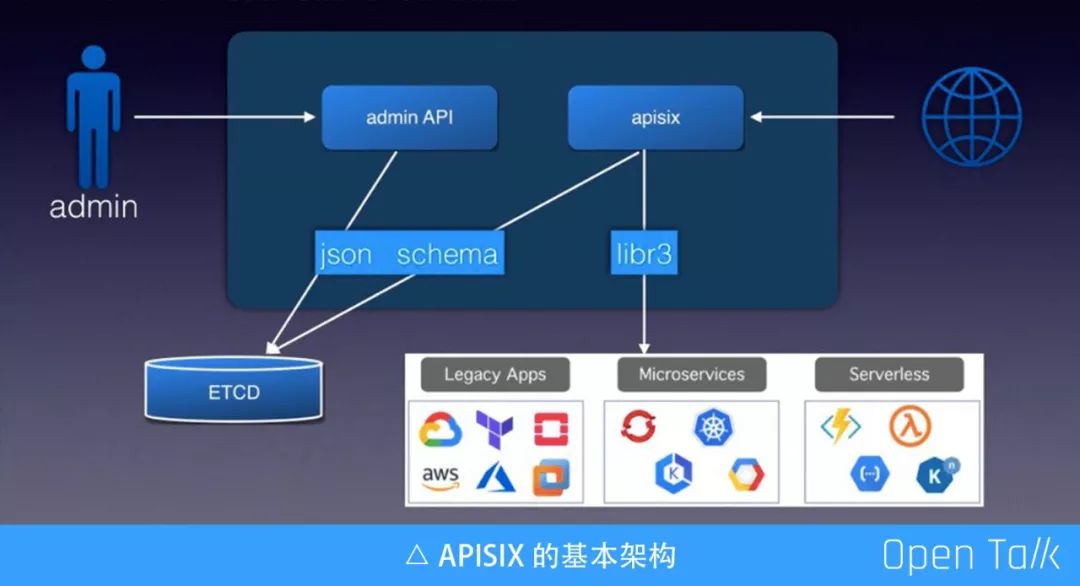
上图是 APISIX 的基本架构,罗列用到的几个基本组件。其中包括 ETCD 可以完成配置存储,由于 ETCD 可以走集群,所以我们可以借用它完成动态伸缩、高可用集群等。ETCD 数据支持通过 watch 的方式增量获取,使得 APISIX 节点规则更新可以做到毫秒级,甚至更低。APISIX 自身是无服务状态的,所以方便横向扩充。
另一个组件是 JSON Schema,它是一个标准协议,主要用来验证数据的有效性。JSON Schema 目前对外公开有四个不同版本,我们最终选用 RapidJSON,因为他对这四个版本都有相对完整的支持。
图中的 Admin API 和 APISIX 可以放在一起,也可以分开。Admin API 接收用户提交的请求,在请求参数保存到 ETCD 之前,会使用 JSON Schema 做一次完整校验,有了校验可以确定到 ETCD 里的都是有效数据。
上图右侧是接收外部用户的真实流量,APISIX 从 ETCD 中订阅所有配置规则,拿到配置规则后给到下面的路由引擎(libr3),目前默认使用的路由引擎是 libr3,我之前在武汉的分享中进行过详细介绍(https://www.upyun.com/opentalk/428.html)。 libr3 是一个路由引擎实现,基于前缀树,由于他还支持正则,所以效率非常高的,同时功能也很强大。
APISIX 的 v0.5 版本具备以下功能:

APISIX 的性能

通常来说,引入了前面提到的十几项功能,会伴随着性能的下降,那么究竟下降了多少呢?这里我做了一个性能的测试对比。如上图,右侧是我为了测试写的一个虚假的服务,这个服务里面空空如也,只是把 ngx_lua 里的一些变量拿出来,然后传给了什么都不做的 fake_fetch,后面的 http filter、log 阶段等一样,没有任何计算量。
然后对 APISIX 和右边的虚假服务分别跑压力测定,对比结果发现 APISIX 的性能仅仅下降了 15%,也就是说在接受了 15% 的性能下降的同时,就可以享受前面提到的所有功能。
说一下具体数值,这里使用的是阿里云的计算平台,单 worker 下可以跑到 23-24k QPS,4 worker 可以跑到 68k 的 QPS。
APISIX 目前的状态
目前最新版本是 v0.5,架构是基于 ETCD+libr3+RapidJSON。这个版本加的最多的是代码覆盖率,v0.4 版本代码覆盖率不超过 5%,但最新版本中代码覆盖率达到 70%,这其中 95% 是核心代码,周边的代码覆盖率相对较低,主要是插件的相关测试有所欠缺。
原本计划在 0.5 版本上线管理界面功能,这样可以降低入门门槛,但是遗憾的是目前还没开发完成,这与我们自身专业有关系,不擅长做前端界面,需要借助前端的专家帮我们实现,我们计划会在 0.6 的版本上线(注:目前已经发布了 v0.6 版本:https://github.com/iresty/apisix/blob/master/CHANGELOG_CN.md#060)。
OpenResty 编程哲学与优化技巧
我从 2014 年开始做 OpenResty 开发,至今已经有六年了。在 OpenResty 的领域里,它的哲学是要学会大事化小,小事化了,因为 Nginx 的内存管理方式是把所有的请求内存默认放到一个内存池里,请求退出的时再把内存池销毁。如果不能很快地一进一出,它就会不停申请,最后释放时资源损耗很大,这是 Nginx 不擅长的。所以用 OpenResty 做长连接就需要非常小心,避免把内存池搞大。
此外,要尽可能少地创建临时对象。这里所指的临时对象有两类,一类是 table 类,一类是字符串拼接,比如某两个变量拼接产生新的字符串,这个看似在其他很多语言都没有问题,但在 OpenResty 里需要尽量少做这种操作。Lua 语言虽然简单,但也是门高级语言,携带了优良的 GC ,让我们无需关心所有变量的生命周期,只负责申请就好了,但如果滥用临时变量等,会让 GC 比较忙碌,付出代价是整体运行效能不高。Lua 擅长动态和流程控制,如果遇到硬核的 CPU 运算任务,还是推荐交给 C/C++ 实现。
今天和大家分享优化技巧,主要还是如何写好 Lua,毕竟他的受众群体更多。在 APISIX 的 core 中,我们使用了一些比较特别的优化技巧,下面逐一给大家介绍。
技巧一:delay_json

先说一下场景:比如上面的这行日志调用,如果当前日志级别是 info ,我们期望会正常 json encode;而当是 error 级别,我们就不期望发生 json encode 操作,如果能自动跳过是最完美了。那我们如何近似的实现这个目的呢?
我们看一下 delay_encode 的实现源码,首先用元方法重载了 tostring ,下面 delay_encode 只是对 delay_tab 的两个对象 data 和 force 做了赋值,然后没有做其他的事情,这与大家平时看到的 json encode 方法都不一样。因为真正在写日志时,如果给定的参数是 table,在 OpenResty 里会把他转成 string 的,过程是检查是否有 tostring 的元方法注册,如果有就调这个方法把它转换成字符串。有了上面的封装,我们就在高性能和易用性上做了很好的平衡。
技巧二:HASH vs 前缀树 vs ?遍历
Lua table 的 HASH:性能最好的匹配方式,缺点是只能做全量匹配。
前缀树:借助 libr3 完成前缀等高级匹配(支持正则)。
遍历:永远是最糟糕的。
在 APISIX 的世界里,我把 HASH 和前缀树做了融合,如果你的请求和路由规则不包含高级规则匹配,会默认走 HASH 来保证效率;但如果有模糊匹配逻辑,则使用前缀树。
技巧三:ngx.log 是 NYI
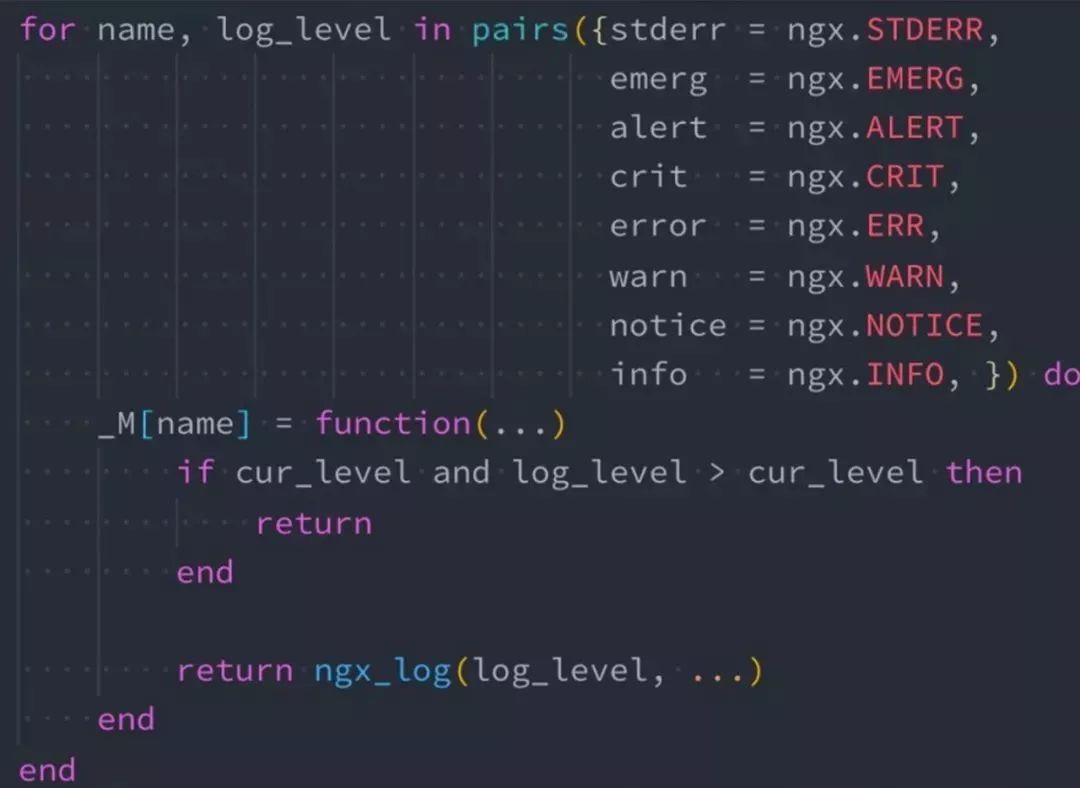
因为 ngx.log 是 NYI,所以我们要尽量减少下面这段代码的触发频率:
return?ngx_log(log_level,…)
要降到最低,需要判断当前日志级别,如果当前的日志级别和你输入的日志级别存在大小比值关系,发现不需要输入就直接 return。避免出现日志处理完,传到 Nginx 内核后再发现不需要写日志,这样就会浪费非常多的资源。
前面提到的压力测试,都是把日志打到 error 级别,加了非常多的调试代码并且保留不删,这些测试代码的存在完全不会影响性能结果。
技巧四:gc for cdata and table
场景:当某个 table 对象被系统回收时,希望触发特定逻辑以释放关联资源。那么我们如何给 table 注册 gc 呢?请参考下图示例:
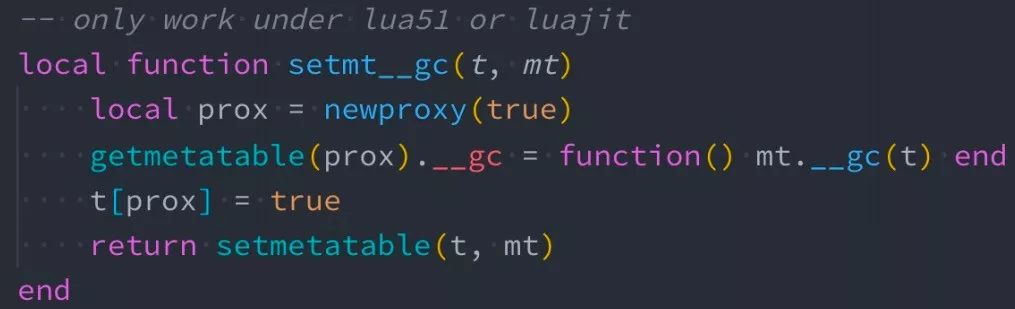
当我们无法控制 Lua table 的整个生命周期,可以用上图的方法去注册一个 GC,当 table 对象没有任何引用时会触发 GC,释放关联资源。
技巧五:如何保护常驻内存的 cdata 对象

我们在使用 r3 这个 C 库时遇到这么一个问题:我们给 r3 添加很多路由规则,然后生成 r3 tree,如果规则没有变化 r3 将被反复使用,由于 r3 内部没有申请额外的内存存储,只是引用指针地址。但外面传入的 Lua 变量可能是临时变量,引用计数为 0 后会被 Lua GC 自动回收。导致的现象是 r3 内部引用的原有内存地址内容突然发生变化,最后致使路由匹配失败。
知道了问题原因,解决方法就比较简单了,只需要避免变量 A 提前释放,让 Lua 里面变量 A 的生命周期和 r3 对象的生命周期保持一致即可。
技巧六:ngx.var.* 是比较慢的
大家知道 C 是不支持动态的,它是编译性语言。ngx.var.* 的内部实现可以查看 Nginx 源代码,或者通过火焰图的方式可以看到他内部的实现方式。为了完成动态获取变量,内部必须通过一次 hash 查找,到后用内部的规则把变量值读出。
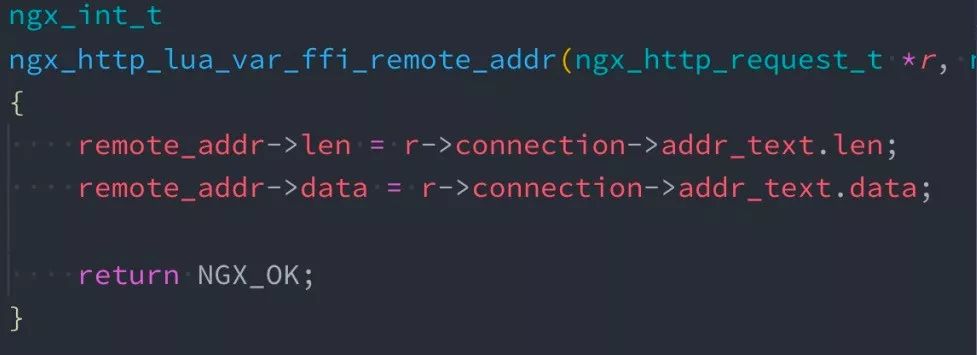
解决方案是用上图这个库(github.com/iresty/lua-var-nginx-module),非常简单没有技术含量的办法。比如要获取客户端的 IP,在 C 里面直接把代码摘出来,然后通过 Lua FFI 方式读取变量的值,就是这么一段小代码可以让 APISIX 性能有 5% 提升。这么做缺点是必须要对 OpenResty 编译时添加这个第三方模块,上手成本略高。
技巧七:减少每请求的垃圾对象
我们要尽可能降低每请求产生的垃圾对象的数量,作为 OpenResty 开发者,如果把这句话理解透彻,基本上可以进阶到前 50% 的行列。
减少不必要的字符串的拼接,并非意味着在需要做拼接字符串的时候不要拼接,而是需要在脑子里一直有这个意识,把无效的拼接降低下来,当这些小细节累积下来,性能提升就会非常大。
技巧八:重用 table
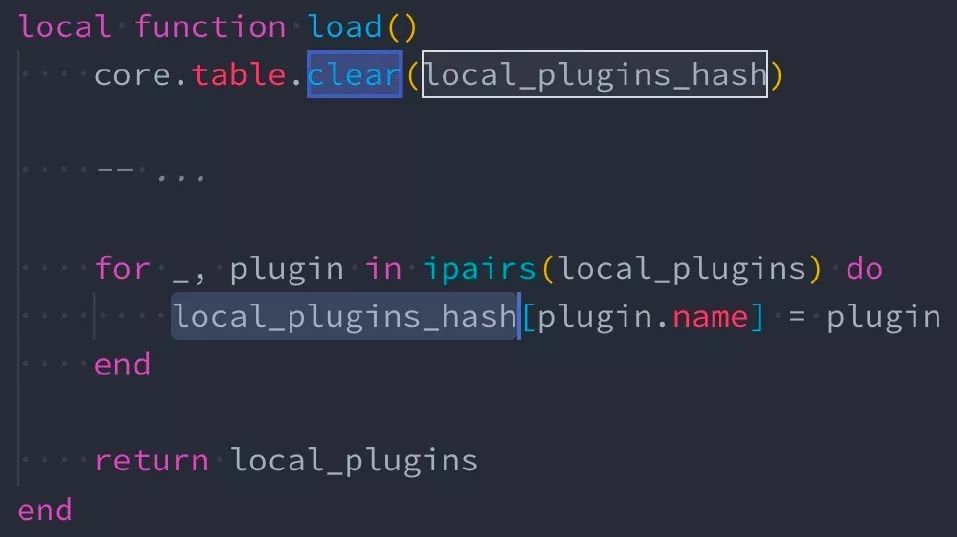
首先介绍下初级版的 table.clear。当需要使用一个临时 table,大家习惯性的写法是
local?t?={}
我们来聊聊这么做的缺点,如果在开头创建了一个临时的 table t,当函数退出的时候,t 会被回收;下次再进来这个函数,又会产生一个临时的 table t。在 Lua 世界,table 的产生和销毁是非常耗资源的,因为 table 是一个复杂对象,它不像 number、字符串等简单对象,申请和释放可以用一个结构体搞定,它会让你的 GC 一下子变得非常忙碌。
如果 worker 里只需要一个唯一实例 table 对象,那么就可以使用 table.clear 方式来反复使用这个临时表,比如上图的临时表 local_plugins_hash。
重用 table :进阶版 table.pool

有些 Lua table 的生命周期是每请求的,通常是请求进入申请对象,请求退出释放对象,这时候使用 table.pool 会非常合适。tablepool 中文翻译过来是表池,里面放的是可以重用的 table。官方文档可以到 https://github.com/openresty/lua-tablepool#synopsis 查看,结合 APISIX 的业务使用代码,更容易理解。
在 APISIX 中最集中使用的是两个地方,除了上图这里做回收,还有是申请的地方。在回收之后,这些 table 可以被其他请求所复用,由 tablepool 做统一控制,在 pool 里维持的对象可能就固定的几十、几百个,会反复使用,不存在销毁的情况。这个技巧的正确使用,性能至少可以提升 20%,提升效果非常明显。
技巧九:Irucache 的正确姿势
简单介绍下 Irucache,Irucache 可以完成在 worker 内的数据的缓存和复用,Irucache 有一个非常大的优势是可以存储任何对象。而共享内存则是完成不同 worker 之间的数据共享,但它只能存储简单对象,有些东西是不能跨 worker 共享,比如 function、cdata 对象等。
对 Irucache 进行二次封装,封装的内容主要包括:
key 要尽量短、简单:我们在写 key 时最重要的是要简单,key 最糟糕的设计是里面东西很长,但是有用信息不多。key 理论上大家都喜欢用字符串,但他可以是 table 等对象,key 尽量做到明确,只包含你感兴趣的内容,能省略的尽量省略,降低拼接成本。
version 可降低垃圾缓存:这点算是我在做 APISIX 的突破:提取出了 version, Irucache+ version 这套组合,可以极大地降低垃圾缓存。
重用 stale 状态的缓存数据。
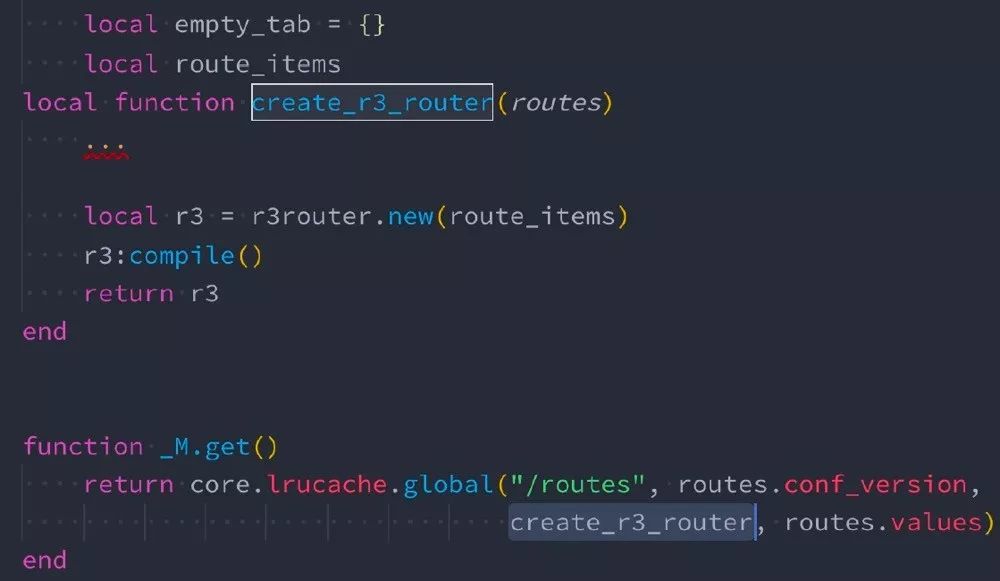
上图是 lrucache 的封装,从下往上看,key 是 /routes,它跟的版本号是 conf_version,global 函数里做的事情是根据 key+version 的方式,去查找有无陈旧数据的缓存,如果有就直接返回,如果没有就调 creat_r3_router 完成创建,creat_r3_router 是负责创建一个新的对象,它只接受一个传参 routes,这个传参是由 routes.values 传进去的。
这层封装,把 Irucache new、数量等都隐藏起来,这样很多东西我们看不到,当我们需要自定义的时候可能还是需要关心这些。APISIX 为了简化插件开发者对各种东西的理解,所以必须要做一层封装,简化使用。
观看视频和 ppt 下载,请点击阅读原文!
快 来 找 又 小 拍

推?荐 阅 读



?告 诉 大 家 你 “在 看” 这 篇 文 章???
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 又拍云
又拍云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩






- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675