
七牛云大数据平台建设实践 | ECUG Con 精粹系列
2017 年 1 月 14、15日,为期 2 天的 ECUG Con 十周年大会在深圳圆满结束,会上七牛云 CEO 许式伟做了题为《七牛大数据平台建设实践》的演讲,首次披露七牛云在大数据方向的产品思路,以下是对他本次的演讲实录。


Q:数据类型有很多种,我们公司目前仅仅是做日志分析。在收集数据的时候,可能会关注哪一部分的数据? 许式伟:这和需求有密切关系。你的分析一定是跟需求相关的,比如说游戏,你希望分析道具相关的,你就需要把道具相关的数据导到平台里面。 Q:数据来源可以是多方面? 许式伟:对。埋点部分是没有办法解决的,这是要到业务系统中去做的事情。 Q:这个产品的定位,会考虑部署到企业内部?因为这个数据很多用户可能对数据比较敏感,希望用你这个产品功能,但是不需要把数据放到上面? 许式伟:我们是可以支持部署到客户 IDC 的,但是是有条件的。我们认为云计算最大的变化是由软件变成服务,所以我们希望 Pandora 的发布形态不是个软件。在这个前提下更多细节可以再讨论。 注:本文整理自许式伟在七牛云主办的 ECUG 十周年大会上的演讲,转载请注明出处 Pandora 处于内测阶段,点击「阅读原文」,咨询详情。
许式伟 七牛云创始人、CEO
从连接到智能
我们都说现在是移动互联网时代,移动互联网时代我们随时随地能够上网,面向连接的革命诞生了很多有意思的应用,包括滴滴打车、外卖,这些都是在连接的时效性基础上做的应用。在有关于连接的革命以后,下一个阶段就是面向智能的革命。滴滴打车这样的场景未来会越来越智能,当然百度外卖号称现在在怎么送外卖这个事情上已经有一些智能,但这些只是开始。每一个应用会沉淀越来越多的数据,它成为这些数据唯一的 Owner。大家应该意识到一点,围绕着数据的深度应用让 App 变得智能,这件事有非常大的空间,无论你在什么领域。在我看来,这个智能不是云计算厂商或者大厂玩智能,未来所有的 App 都会玩智能。 在十年前,大家听到「云计算」,大部分人觉得是不靠谱的,全球第一个云服务也就是 AWS 对象存储,07 年刚刚发布,国内没有人知道,那时候的「云计算」概念虽然已经产生了,但是大家对云计算的认知非常不清楚。当时很多人会把它和网格计算的概念关联起来,而网格计算的概念昙花一现,最后消失了,大家认为云计算是新瓶装旧酒,是网格计算。但在今天看来,云计算本质上是一个 IT 的革命,把 IT 的交付方式由软件变成了服务,这是一个非常巨大的变革。这个变革背后的推动力其实是与移动互联网的兴起有关的。移动互联网的兴起意味着大量新兴机会的涌现,大家拼命地都要跑得更快。这些新兴的公司选择合作伙伴更希望是服务的合作伙伴,而不是软件合作伙伴。软件外包失败的概率是很大的,但是云计算解决了底层基础的 IT 技术外包成功率的问题,这也是云计算兴起的根源。 今天我们听到很多公司谈智能,忽悠的成分可能多于实际。而大部分公司认为智能跟自己没有关系,但是我认为接下来十年智能是非常重要的事情。 智能为什么会兴起?大部分的公司接下来十年都会开始充分利用互联网这个生产力工具,把他们的业务从线下搬上了线上,这意味着他和客户的连接其实是越来越数字化的。所谓的数字化,是指所有的沟通过程都会被记录,这种被记录的过程其实是很可怕的,因为你对用户前所未有地了解。但是如果让这些数据躺在你的计算机里或者删掉,意味着你相比以前纯粹地把业务跑在线下没有本质的进步。将来各行各业的竞争一定是面向数据的竞争,数据累计得越多,你对用户越了解,你对用户行为的挖掘,通过智能的提取,你会让 App 越来越具有独特性。前面李玥介绍了 Linkedin 如何使用数据,那是非常好的一个案例。Linkedin 本质上来讲是一个猎头公司,虽然它比很多大家认知的猎头公司要牛多了。但在本质上来讲,它是颠覆猎头行业的,新的猎头和老的猎头效率差距无比巨大。Linkedin 仅数据产品相关的团队就有 150 人,这是很恐怖的数字,可以看出硅谷公司是怎样的重视数据。企业面临的挑战
- 观念带来的挑战。我们作为一个云计算厂商来看,多数公司的数据都不愿意存,认为数据是负担、是成本。但是在未来十年面向智能的时候,你应该认为数据是资本、是财产。这个观念的转念是非常巨大的。中国公司数据仓库存数十 PB,会觉得每个月要花掉好多钱。多数公司认为数据是成本,这是观念的挑战,可能也是未来最大的挑战。
- 数据产生价值链条长。不知道数据怎么用,或者没有支撑的数据平台。对于很多公司来说,把数据变成数据产品的链条是非常长的。整个数据从埋点、采集、分析、形成一系列产品,整个链条涉及的部门和工种非常多。涉及到业务部门、数据平台部门、数据分析与数据产品部门,而后又回到业务部门作用到线上,这个周期非常长。这决定了要让数据产生价值很困难。
- 多元化的场景。不同的公司业务场景不同,导致我们的数据产品很难用统一的模式产生。这与七牛的非结构化数据相比非常明显。七牛的数据是图片、音频、视频,围绕这些富媒体为存储的核心对象来构建场景,它的应用场景非常集中。非常集中就是说可预测性非常强,虽然我未必知道你的 App 是做什么的,但是我很清楚你的图片是用来做什么、你的视频用来做什么,业务场景比较容易清晰地呈现。但是大数据产品的业务场景非常是多元化的,不同的数据产品,面向的场景很不一样。
七牛大数据平台 - Pandora
- Pandora 是什么
- Pandora 有什么
 图 1
图 1
- Pandora 产品架构图
 图 2
图 2
- Pipeline——数据总线
- Kodo+XSpark——离线计算
 图 3
图 3
- TSDB——时序数据库
图 4
TSDB 是我们自己的一套时序数据库,可以通过各种 SQL 查询,支持高速读写,十分符合实时监控的场景。值得一提的是,我们定制了 Grafana,使得 Grafana可以直接对接 TSDB,使用起来非常方便。- LogDB——日志搜索引擎
- Pandora 的基础逻辑
- 基于 Pandora 的应用场景
- 直播质量的实时报告
 图 5
图 5
图 6
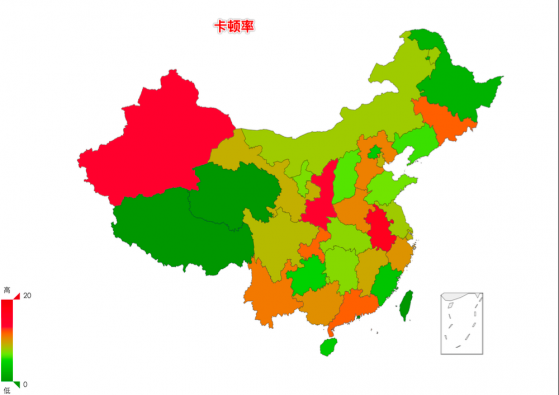
卡顿率也是直播质量考量的一个维度,如图 6 所示,我们可以看到关于卡顿率的热点图。站在全国的维度来看卡顿率,图中越红的地方表示卡顿率越高,质量越差。- 日志搜索
图 7
日志搜索主要是面向客服的场景,比如说某一个主播有卡顿,我们需要找到这个主播相关的条件去搜索,最后把服务端甚至客户端即 SDK 端报上来的数据整合,来看问题到底发生在哪里。我们用了什么
基本上把 Pandora 的服务都用了:- Pipeline: 数据总线、对数据做基础的聚合(1 min,1 day);
- TSDB:实时数据分析;
- LogDB:日志搜索;
- XSpark:高级离线数据分析(各厂商的质量评估)。
Q:数据类型有很多种,我们公司目前仅仅是做日志分析。在收集数据的时候,可能会关注哪一部分的数据? 许式伟:这和需求有密切关系。你的分析一定是跟需求相关的,比如说游戏,你希望分析道具相关的,你就需要把道具相关的数据导到平台里面。 Q:数据来源可以是多方面? 许式伟:对。埋点部分是没有办法解决的,这是要到业务系统中去做的事情。 Q:这个产品的定位,会考虑部署到企业内部?因为这个数据很多用户可能对数据比较敏感,希望用你这个产品功能,但是不需要把数据放到上面? 许式伟:我们是可以支持部署到客户 IDC 的,但是是有条件的。我们认为云计算最大的变化是由软件变成服务,所以我们希望 Pandora 的发布形态不是个软件。在这个前提下更多细节可以再讨论。 注:本文整理自许式伟在七牛云主办的 ECUG 十周年大会上的演讲,转载请注明出处 Pandora 处于内测阶段,点击「阅读原文」,咨询详情。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 七牛云
七牛云
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩
赞助链接






排名
热点
搜索指数
- 1 习近平将发表二〇二六年新年贺词 7904141
- 2 2026年国补政策来了 7808738
- 3 东部战区:开火!开火!全部命中! 7712893
- 4 2026年这些民生政策将惠及百姓 7616985
- 5 小学食堂米线过期2.5小时被罚5万 7519709
- 6 解放军喊话驱离台军 原声曝光 7428214
- 7 为博流量直播踩烈士陵墓?绝不姑息 7327605
- 8 每月最高800元!多地发放养老消费券 7238391
- 9 数字人民币升级 1月1日起将计付利息 7141831
- 10 2026年1月1日起 一批新规将施行 7040675