TiFlash 源码阅读(八)TiFlash 表达式的实现与设计
TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件,TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。在上一期的源码阅读中,大家应该对 TiFlash Proxy 模块的实现,即 TiFlash 副本是如何被添加以及获取数据有了一定的了解。
本文主要介绍的是 TiFlash 表达式的实现与设计,系统性地介绍了 TiFlash 表达式的基本概念,包括表达式体系,标量函数、聚合函数等,以期望读者能够对 TiFlash 的表达式计算有一个初步的了解。
本文作者:黄海升,TiFlash 研发工程师
表达式概要
表达式是承载 SQL 大部分逻辑的一个重要部分。SQL 中的表达式和编程语言中的表达式并没有差异。表达式可以大致分为函数、常量、列引用。如 select a + 1 from table 中的 a + 1 是一个表达式,其中 + 是函数,1 是常量,a 是列引用。
在 SQL 中,表达式会归属在不同的算子里执行,以 select a + b from tests.t where c > 0 为例,大家可以从下图看到不同的表达式归属在哪些算子里。
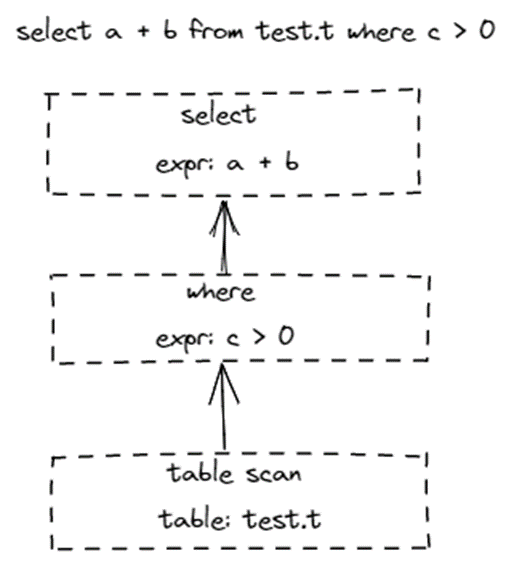
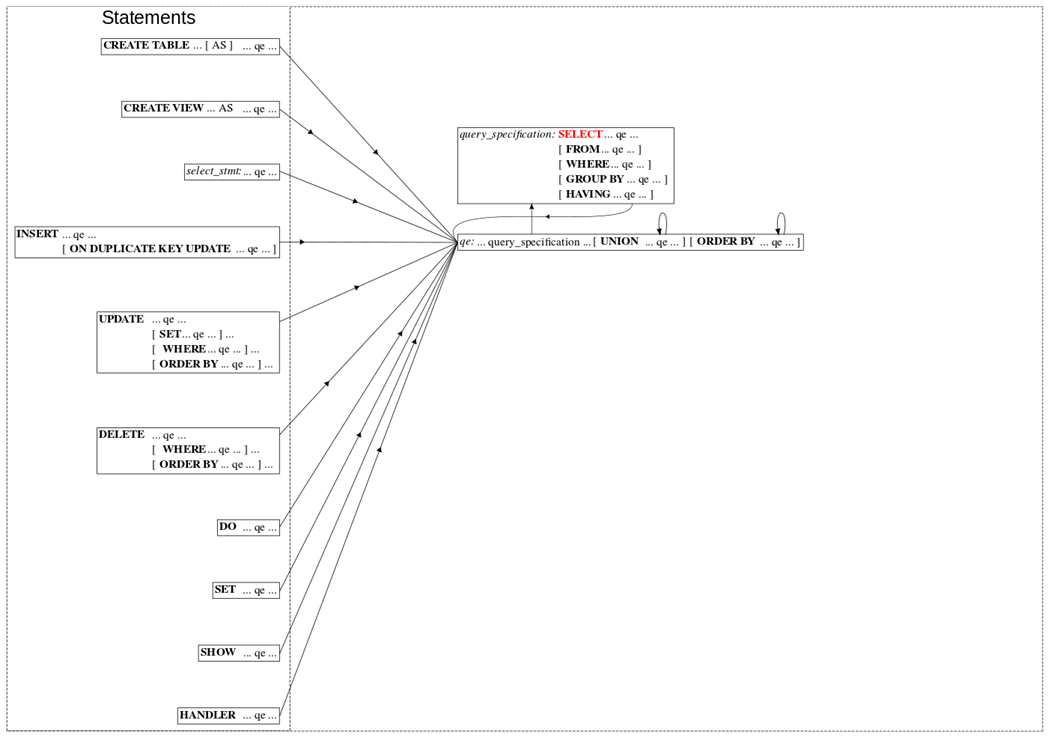
表达式在 SQL 中如何划分出来,并且归属在哪些算子里,是由一套语法规则决定的。下图是 MySQL 8.0 Parser 的语法规则简图,里面大号粗体的是算子标识符,后面跟着的小号字段是归属这个算子的表达式。
在了解了什么是表达式之后,我们来了解一下表达式在 TiFlash 里执行的情况。
在 TiDB HTAP 的体系里,TiFlash 的表达式是由 TiDB 下推给 TiFlash 执行的。首先我们来回顾下 TiDB 计算下推 TiFlash 的流程。

TiDB 接收 MySQL Client 发送的 sql,经由 Parser 和 Optimizer 解析成算子,在之后将算子下推到 TiFlash 里执行。与此同时,算子内部的表达式也会跟随一起下推到 TiFlash 里执行。
如下图所示,如果某个算子带有 TiFlash 不支持的函数,就会导致一连串的算子都无法下推到 TiFlash 里执行。算子内部的表达式都可以下推执行,是算子下推的必要条件。

在算子和表达式下推到 TiFlash 后,TiFlash 会用向量化执行引擎来执行这些算子和表达式。在谈到 TiFlash 的向量化执行引擎之前,我们先来讲一下执行引擎的一个经典模型 Volcano Model。
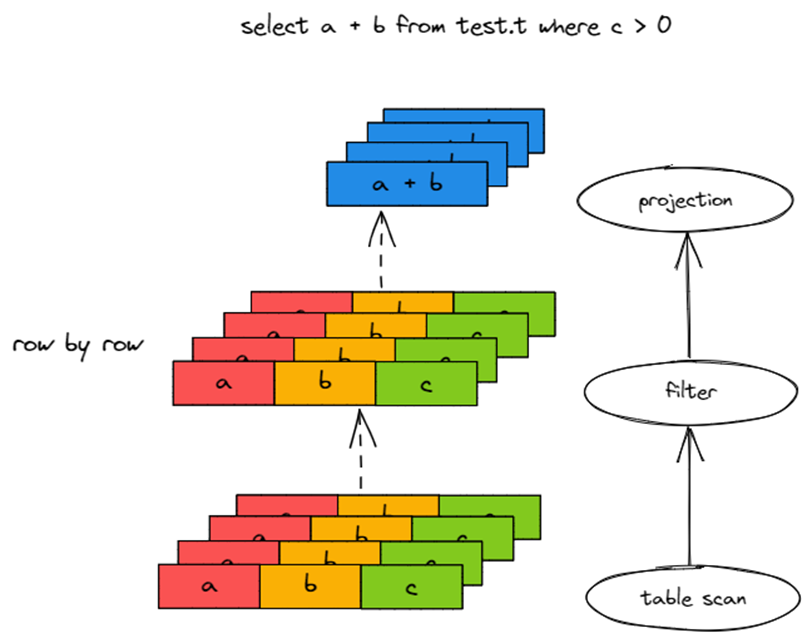
Volcano Model 源自 1994 年的论文 Volcano-An Extensible and Parallel Query Evaluation System。Volcano Model 将 SQL 分解为若干个独立的 Operator,Operator 串联成一棵 Operator Tree。
如上图所示,从最源头的 Table Scan Operator 开始,一行一行地读取数据,Operator 处理后,传给上游 Operator。最终 Operator Tree 一行一行地输出结果。
下面是对 Operator 接口的一个简单的伪代码描述。
struct Operator
{
Row next()
{
Row row = child.next();
....
return row;
}
}
Volcano Model 提供了一个非常简洁的执行模型,在工程上也非常容易实现。但是 Volcano Model 在现代编译器和硬件下运行得慢。在后续几年了诞生了对 Volcano Model 的两个改进方案,Codegen 和 Vectorized。TiFlash 就是使用的 Vectorized 即向量化执行。
向量化执行与 Volcano Model 基本一致,区别在于 Block by Block。
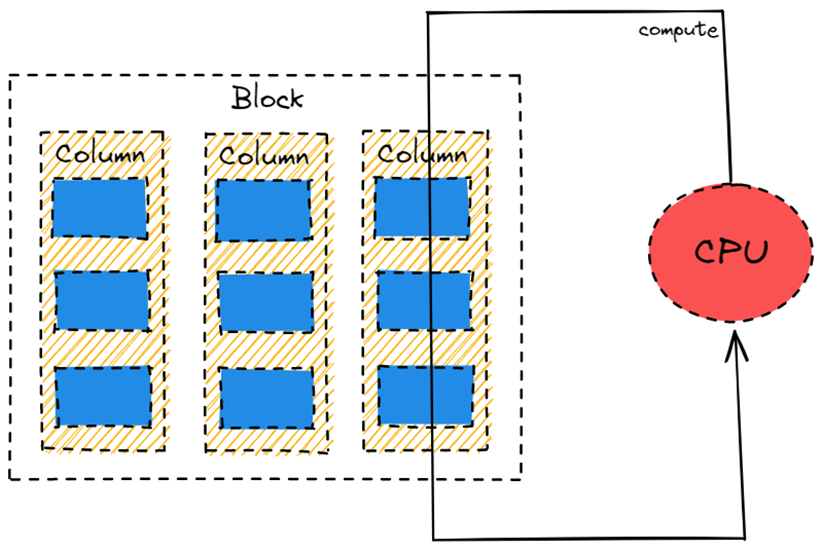
Block 是若干 Row 组合在一起的数据块,Block 内部按 Column 保存数据。
这样设计的好处有几个:
虚函数调用的开销会被减小为 1 / (Block Size)。Volcano Model 中的 Operator 和表达式通常都是用多态来实现的,在其中就会引入虚函数调用。每次 Operator Tree 和内部的表达式被调用就是一系列的虚函数调用,在数据量大的情况下,虚函数开销甚至会成为一个不可忽视的点。Block by Block 可以让 Operator Tree 和内部的表达式的一次调用处理多行而不是一行数据,从而均摊了虚函数开销。
Cache Friendly。把会被连续处理的数据放在一个数据块里,提高在 Cache 上的空间局部性。
TiFlash 表达式体系 ExpressionActions
除了向量化执行外,TiFlash 在表达式执行上还有一套独立的执行体系 ExpressionActions,不同于 TiDB 源自 Volcano Model 的 ExpressionTree。
这两个表达式体系在逻辑语意上是一致的,仅仅在执行过程上有差别。
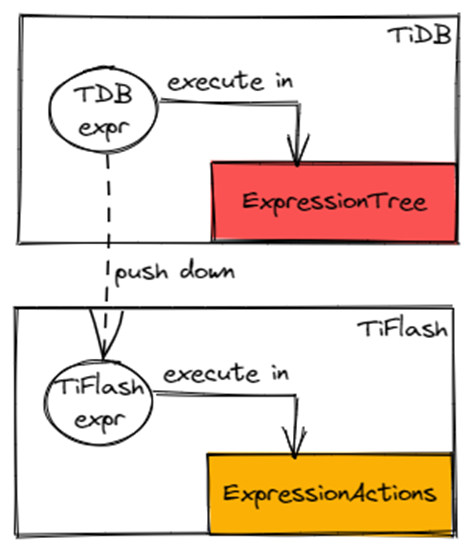
如上图所示,同样的表达式在 TiDB 和 TiFlash 里会分别在不同的表达式体系里执行。
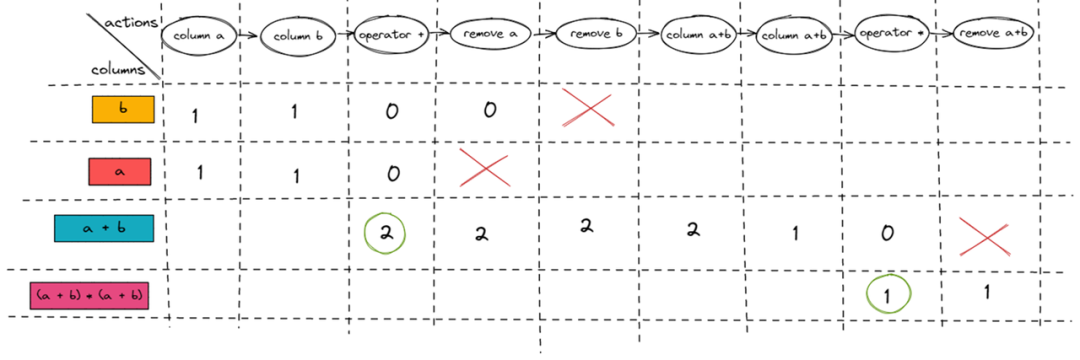
接下来以 (a + b) * (a + b) 为例子来讲述一下两个表达式体系执行的差异。
首先从 TiDB ExpressionTree 讲起。(a + b) * (a + b) 会被分解成一棵 Expression Tree,每一个 Expression 都是一个节点。从 Column Expression 和 Literal Expression 开始读取数据,遍历整棵 Expression Tree,最终得出表达式结果。
如下图所示,沿着图中的箭头方向,就可以从 Input 计算得出 (a + b) * (a + b) 的结果 Output。
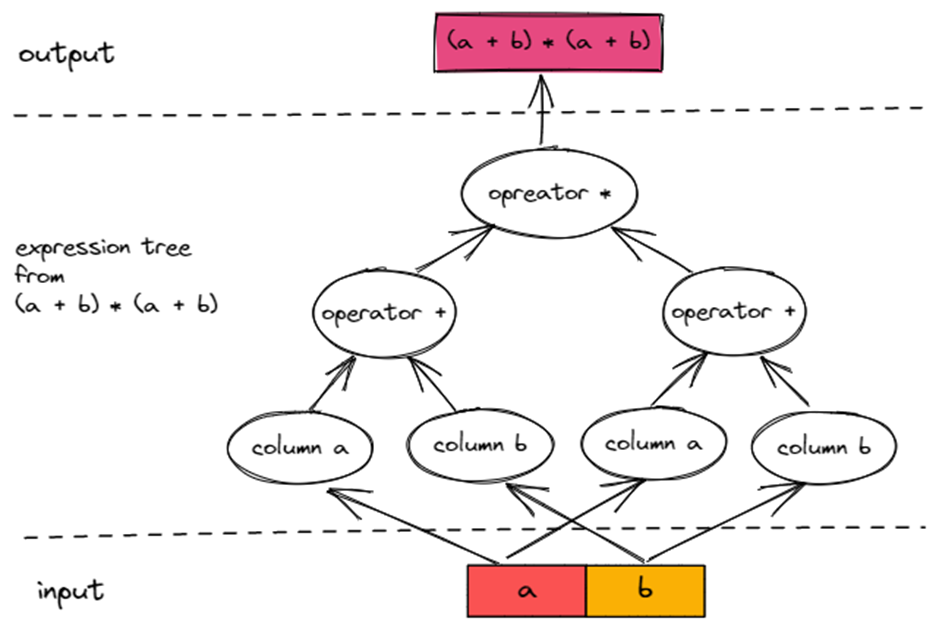
在图中大家可以发现 (a + b) 这个子树出现了两次,也就意味着 (a + b) 本身执行了两次,那么可不可以复用 (a + b) 的计算结果,如下图所示连线?哪怕这样就不是一棵树了。
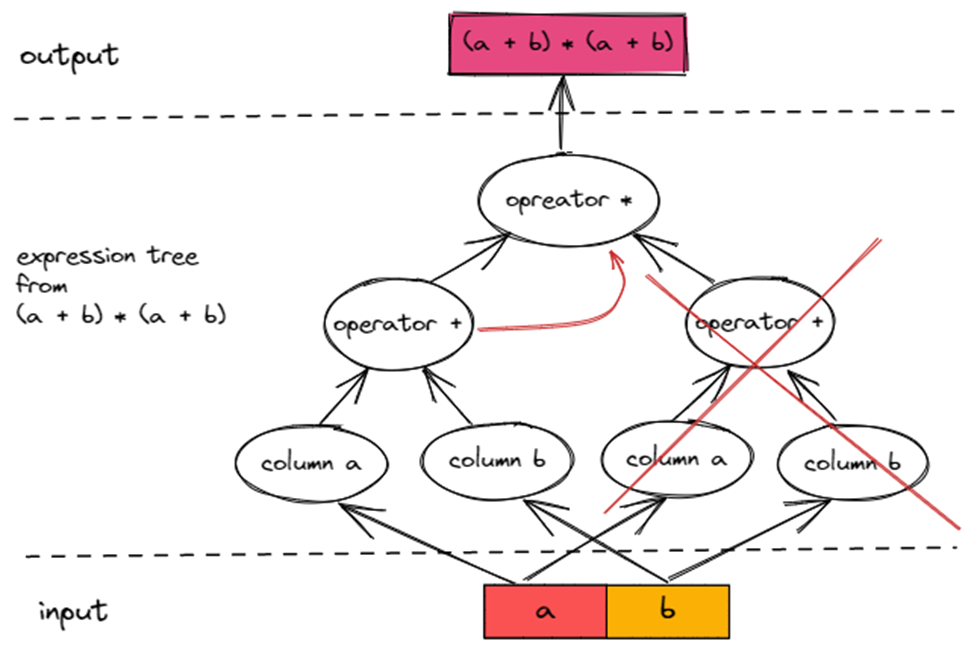
事实上是可以的,这也是 TiFlash ExpressionActions 的设计初衷: 中间计算结果复用。
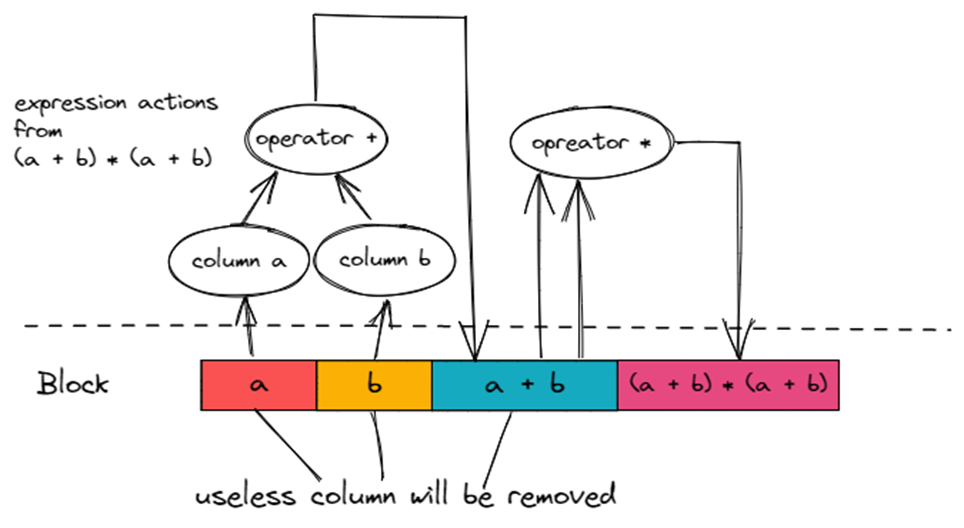
在 TiFlash ExpressionActions 下,中间计算的临时结果会作为 Column 会被写到 Block 里,同时我们会通过 Column Name 获取 Block 中对应的 Column。
如上图所示,沿右图箭头方向遍历 Expression Action,即可得出 (a + b) * (a + b) 的计算结果。可以看到,同样是 (a + b) * (a + b),TiFlash ExpressionActions 里的 (a + b) 只计算了一次。下面是 ExpressionActions 的执行分解图,从左到右。大家可以对照一下分解图,大概了解一下 ExpressionActions 的执行过程。


左右滑动查看
ExpressionActions 究竟做了些什么。class ExpressionActions
{
public:
void execute(Block & block) const
{
for (const auto & action : actions)
action.execute(action);
}
void add(const ExpressionAction & action);
void finalize(const Names & output_columns);
private:
std::vector<ExpressionAction> actions;
}
以上是 ExpressionActions 接口的简化代码。有三个主要方法:
execute
对
ExpressionAction::execute的包装。用于执行表达式。
add
用于外部组装出一个 ExpressionActions。
ExpressionActions会维护一个 Sample Block,在 Add Action 的过程中 Sample Block 会不断更新,模拟实际 Block 的变化情况。在 Add 的过程中,重复的 Action 会被跳过。重复 Action 的判断条件是,该 Action 的执行结果是否已经出现在 Sample Block 里了。

finalize
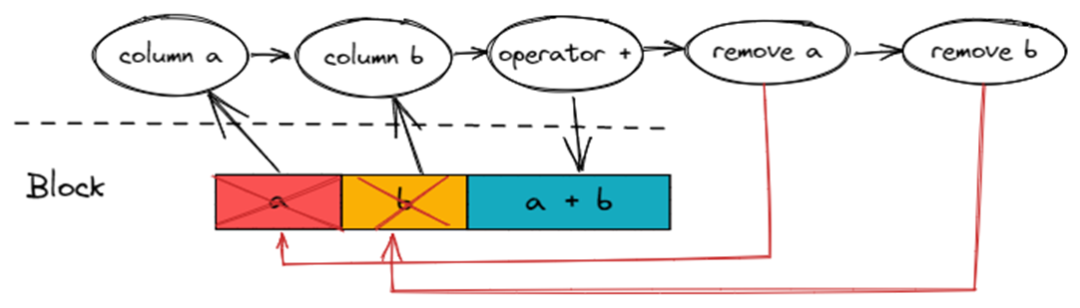
分析 Block 内的 Column 引用情况,在合适的位置插入 Remove Action 来移除无用的 Column。
在 Column 引用数归 0 的时候,就会插入对应 Column 的 Remove Action。
下图是 (a + b) * (a + b) 的引用数分析和 Remove Action 插入情况。
ExpressionAction 是 ExpressionActions 内部的执行单元。
struct ExpressionAction
{
Type type;
…
void execute(Block & block) const
{
switch (type)
{
case: APPLY_FUNCTION:
…
case: REMOVE_COLUMN:
…
case: ADD_COLUMN:
…
}
}
}ExpressionAction 有不同的 Type 用于对 Block 进行不同的处理
REMOVE_COLUMN
即前文所讲的 Remove Action
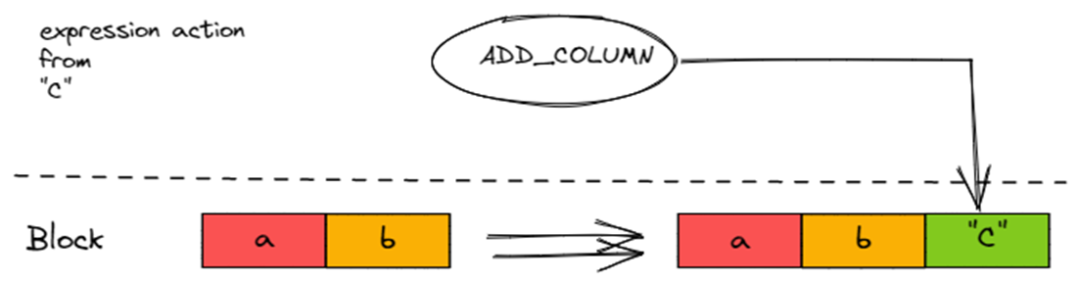
ADD_COLUMN
用于执行 Literal Expression,在 Block 插入一个 Const Column。
ADD_COLUMN会在 Block 中插入一个 Column。对于 Literal,插入的会是 ColumnConst,即常量 Column。block.insert({added_column->cloneResized(block.rows()), result_type, result_name});
APPLY_FUNCTION
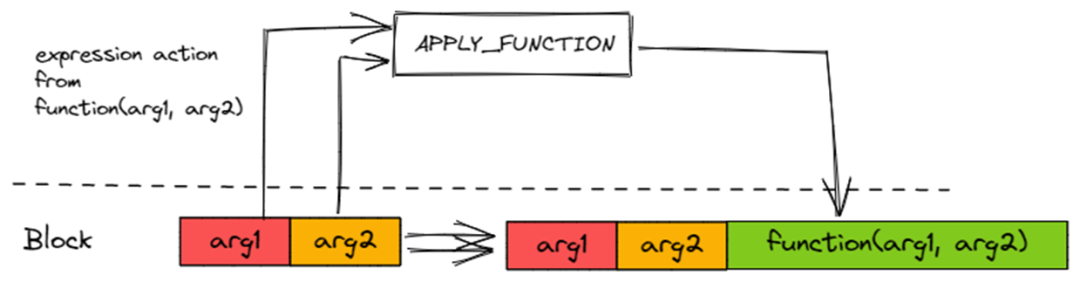
用于执行 Function Expression,由 ExpressionAction 持有的
IFunction执行
APPLY_FUNCTION会读取 Block 中的 Argument Columns 传给IFunction做计算。计算出结果 Column 后,插入到 Block 中。
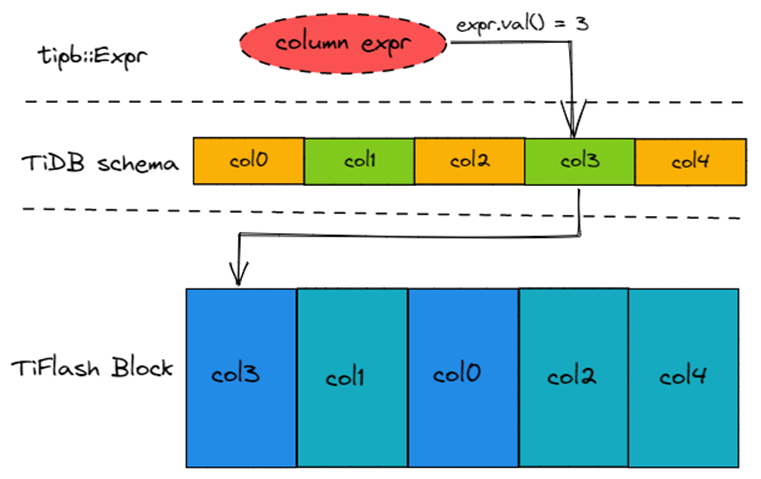
Column Expression 没有对应的 Action Type,直接执行 Block::getPositionByName 获取 Column 在 Block 里的下标。但是从 TiDB 获得的 Column Expression 计算得出的并不是 Column 在 Block 中的 Column Name,而是 Column 在 TiDB Schema 中的下标。所以 TiFlash 会维护 TiDB Schema (std::vector<String>) 来桥接 TiDB Column Index 和 TiFlash Column Name,如下图所示。
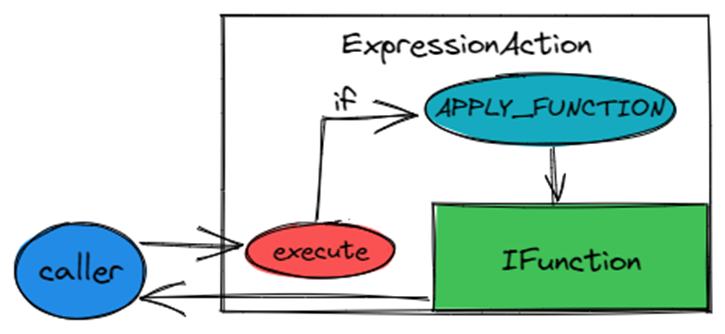
标量函数在 TiFlash 中的编译与执行
当 ExpressionAction 的 Type 为 APPLY_FUNCTION时,ExpressionAction内部会持有IFunction。对ExpressionAction::execute的调用都会转发给IFunction执行。IFunction是 TiFlash 向量化标量函数的基类。
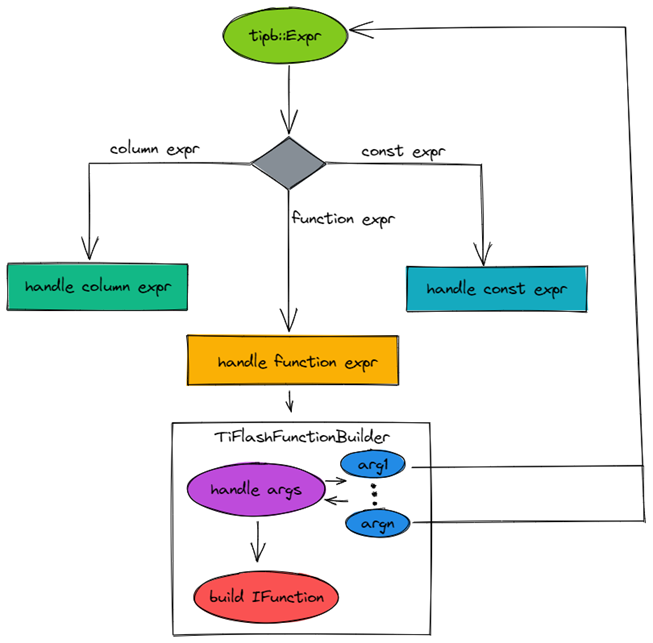
首先我们从函数在 TiFlash 中的编译讲起。tipb是 TiDB 与 TiFlash 之间的序列化协议,下图的tipb::Expr等同是 TiDB 里的 Expression。
对于传入的一个 tipb::Expr,首先分门别类,按照 Column,Literal,Function 分别处理。
如果是 Function,首先处理 Function 的所有参数。参数本身也是 tipb::Expr,所以也会按照对应的tipb::Expr处理流程处理。在处理完 Function 的所有参数后,就可以去构建IFunction本身,然后塞入ExpressionAction,返回处理结果。
TiDB 对函数的标识是 tipb::ScalarFuncSig,而 TiFlash 使用 Function Name 作为函数的标识。在 TiFlash 里,我们会用映射表的形式将 tipb::ScalarFuncSig 映射成 Function Name。再根据 Function Name 找到对应的 TiFlash Function Builder。
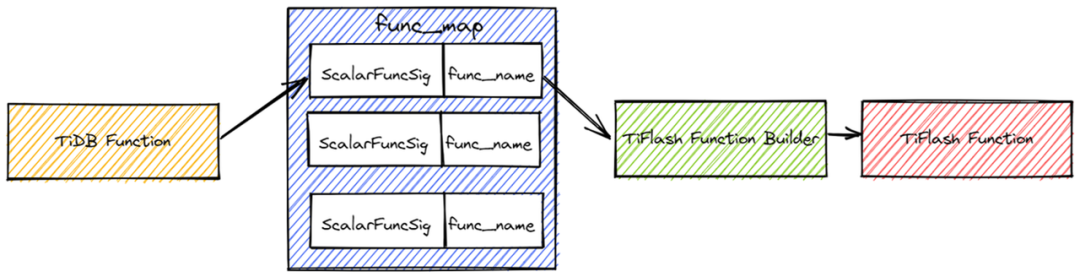
对于窗口函数、聚合函数、distinct 聚合函数、标量函数都有各自的映射表。
const std::unordered_map<tipb::ExprType, String> window_func_map({
{tipb::ExprType::Rank, "rank"},
...
});
const std::unordered_map<tipb::ExprType, String> agg_func_map({
{tipb::ExprType::Count, "count"},
...
});
const std::unordered_map<tipb::ExprType, String> distinct_agg_func_map({
{tipb::ExprType::Count, "countDistinct"},
...
});
const std::unordered_map<tipb::ScalarFuncSig, String> scalar_func_map({
{tipb::ScalarFuncSig::CastIntAsInt, "tidb_cast"},
...
});
IFunction 实现。TiFlash 有两类 Function Builder: Default Function Builder 和 Special Function Builder。前者是用于处理大多数 Function,后者处理某些特殊情况。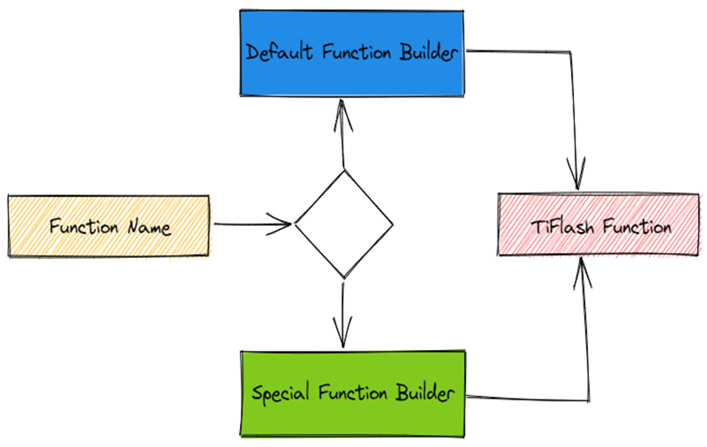
String DAGExpressionAnalyzerHelper::buildFunction(
DAGExpressionAnalyzer * analyzer,
const tipb::Expr & expr,
const ExpressionActionsPtr & actions)
{
const String & func_name = getFunctionName(expr);
if (function_builder_map.count(func_name) != 0)
{
return function_builder_map[func_name](analyzer, expr, actions);
}
else
{
return buildDefaultFunction(analyzer, expr, actions);
}
}
Default Function Builder 的处理本身很简单,就是先处理所有的函数入参,然后调用 applyFunction 生成对应的 IFunction 实现。
String DAGExpressionAnalyzerHelper::buildDefaultFunction(
DAGExpressionAnalyzer * analyzer,
const tipb::Expr & expr,
const ExpressionActionsPtr & actions)
{
const String & func_name = getFunctionName(expr);
Names argument_names;
for (const auto & child : expr.children())
{
String name = analyzer->getActions(child, actions);
argument_names.push_back(name);
}
return analyzer->applyFunction(func_name, argument_names, actions, getCollatorFromExpr(expr));
}
对某些函数,有些特殊处理,这时就会使用到 Special Function Builder。
特殊处理的 Function Builder 会放在表里,遇到对应的函数,会转发过来。
下面是一些函数的特殊处理映射。
FunctionBuilderMap DAGExpressionAnalyzerHelper::function_builder_map(
{...
{"ifNull", DAGExpressionAnalyzerHelper::buildIfNullFunction},
{"multiIf", DAGExpressionAnalyzerHelper::buildMultiIfFunction},
...
{"bitAnd", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
{"bitOr", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
{"bitXor", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
{"bitNot", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
{"bitShiftLeft", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
{"bitShiftRight", DAGExpressionAnalyzerHelper::buildBitwiseFunction},
...
});
一个特殊的处理的情况是复用函数实现。某些函数可以由另一个函数来代理执行,比如
leftUTF8(str, len) = substrUTF8(str, 1, len)。如果让 substrUTF8 来代理执行 leftUTF8,那么就可以省掉leftUTF8本身的开发实现工作。下面是leftUTF8(str, len) = substrUTF8(str, 1, len)的代理实现代码。为substrUTF8生成第二个参数1后,将leftUTF8的两个参数传入substrUTF8,substrUTF8就可以代理leftUTF8执行。
String DAGExpressionAnalyzerHelper::buildLeftUTF8Function(
DAGExpressionAnalyzer * analyzer,
const tipb::Expr & expr,
const ExpressionActionsPtr & actions)
{
const String & func_name = "substringUTF8";
Names argument_names;
// the first parameter: str
String str = analyzer->getActions(expr.children()[0], actions, false);
argument_names.push_back(str);
// the second parameter: const(1)
auto const_one = constructInt64LiteralTiExpr(1);
auto col_const_one = analyzer->getActions(const_one, actions, false);
argument_names.push_back(col_const_one);
// the third parameter: len
String name = analyzer->getActions(expr.children()[1], actions, false);
argument_names.push_back(name);
return analyzer->applyFunction(func_name, argument_names, actions, getCollatorFromExpr(expr));
}
接下来我们来看一下 IFunction 本身的接口。
class IFunction
{
public:
virtual String getName() const = 0;
virtual DataTypePtr getReturnTypeImpl(const DataTypes & /*arguments*/) const;
virtual void executeImpl(Block & block, const ColumnNumbers & arguments, size_t result) const;
};
IFunction 有三个主要方法
getName: 返回 Function 的 Name,Name 是作为 TiFlash 向量化函数的唯一标识来使用。getReturnTypeImpl: 负责做向量化函数的类型推导,因为输入参数数据类型的变化可能会导致输出数据类型变化。executeImpl: 负责向量化函数的执行逻辑,这也是一个向量化函数的主体部分。一个 TiFlash 向量化函数够不够"向量化",够不够快也就看这里了。
接下来以 jsonLength(string) 为例子,讲一下向量化函数的执行
从 Block 中获取 Json Column
创建同等大小的 Json Length Column
Foreach Json Column,获取每一个行的 Json
调用 GetJsonLength(Json)获取 Json Length,将结果插入 Json Length Column 中的对应位置。
将 Json Length Column 插入到 Block 中,完成单次计算

void executeImpl(Block & block, const ColumnNumbers & arguments, size_t result) const override
{
// 1. 获取 json column,json column 本身是 String 类型,所以 json column 用的是 ColumnString 这个 column 实现
const ColumnPtr column = block.getByPosition(arguments[0]).column;
if (const auto * col = checkAndGetColumn<ColumnString>(column.get()))
{
// 2.创建 json len column, json len 本身是 UInt64 类型,用的是 ColumnUInt64 这个 column 实现
auto col_res = ColumnUInt64::create();
typename ColumnUInt64::Container & vec_col_res = col_res->getData();
{
// 3. 遍历 json column,ColumnString 提供了一些裸操作内部 string 的方法,可以提高效率
const auto & data = col->getChars();
const auto & offsets = col->getOffsets();
const size_t size = offsets.size();
vec_col_res.resize(size);
ColumnString::Offset prev_offset = 0;
for (size_t i = 0; i < size; ++i)
{
// 4. 调用 GetJsonLength,计算出 json 的 length,插入到 json len column 中。
std::string_view sv(reinterpret_cast<const char *>(&data[prev_offset]), offsets[i] - prev_offset - 1);
vec_col_res[i] = GetJsonLength(sv);
prev_offset = offsets[i];
}
}
// 5. 将 json len column 插入到 Block 中,完成单次计算。
block.getByPosition(result).column = std::move(col_res);
}
else
throw Exception(fmt::format("Illegal column {} of argument of function {}", column->getName(), getName()), ErrorCodes::ILLEGAL_COLUMN);
}
前段时间 TiFlash 有个社区活动,号召大家来参与 TiFlash 函数下推的工作。
以上关于标量函数的内容在社区活动的两篇文章 TiFlash 函数下推必知必会 和 手把手教你实现 TiFlash 向量化函数 都有包含,大家可以通过这两篇文章了解更多关于 TiFlash 标量函数的内容。也欢迎小伙伴们也参与到 TiFlash 函数下推的工作中来。
聚合函数在 TiFlash 中的编译与执行
聚合函数不同于标量函数的点在于输入 m 行数据输出 n 行数据,且有 m >= n。
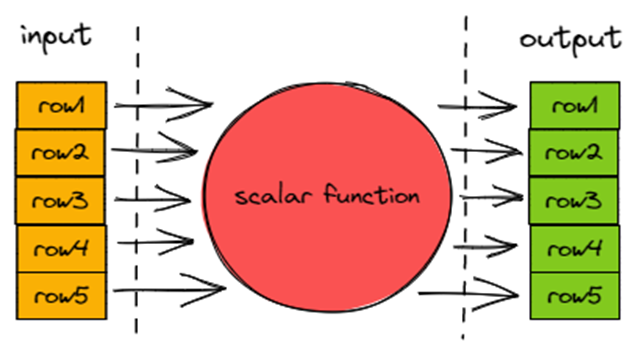
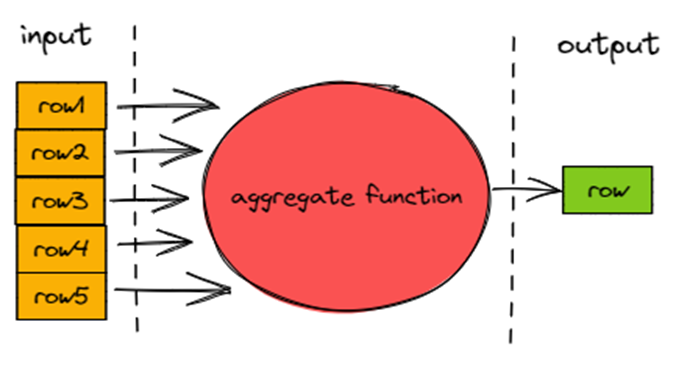
所以聚合函数不会使用 ExpressionActions 和 IFunction,而是有独立的执行体系。
聚合函数本身由 Aggregate 算子来执行,Aggregate 算子负责管理聚合函数的执行步骤,执行并发度等等。
Aggregate 算子的执行有两部分
前者 ExpressionActions 用于执行标量函数的部分。
后者 Aggregator 用于执行聚合函数的部分。
如下图所示,对于select max(a+b),ExpressionActions执行a+b,Aggregator执行max。
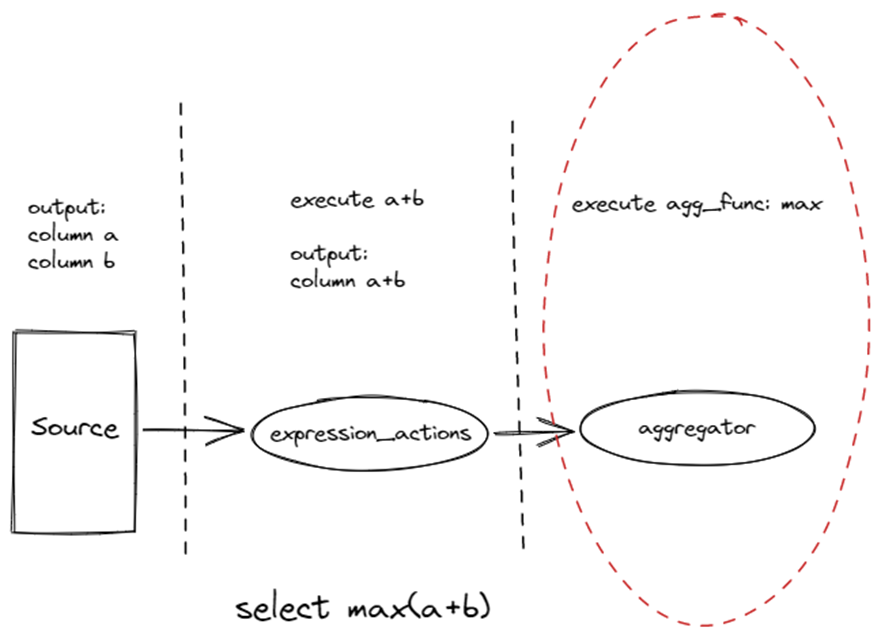
下面详细来说一说 Aggregator是如何执行聚合函数的。首先Aggregator会多线程从 Input 读取 Block,调用executeOnBlock写入 Thread LocalAggregatedDataVariants。AggregatedDataVariants内部会保存当前线程的部分聚合计算结果。在executeOnBlock阶段完成后,Aggregator会调用mergeAndConvertBlocks将多个AggregatedDataVariants合并成一个,输出最终聚合的结果给 Output。
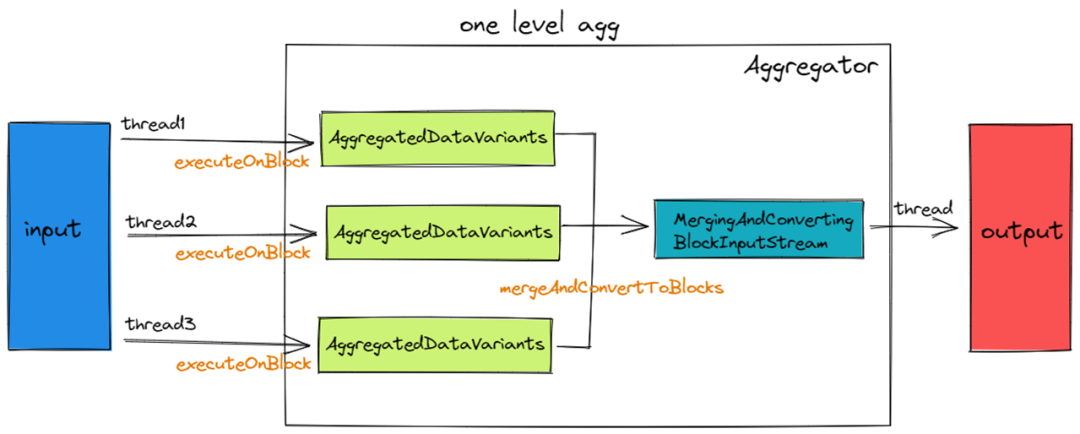
Aggregator::executeOnBlock 会对每一个 Key 都会创建一个 Aggregate Data。
输入的 Row 会根据 Key 找到对应的 Aggregate Data, 调用 IAggregateFunction::add,更新 Agg Function 保存在 Aggregate Data 里的聚合结果。
如下图所示,Row1 和 Row4 经由 Aggregate Function 计算后,更新 Key1 保存的 Aggregate Data;Row2 经由 Aggregate Function 计算后,更新 Key2 保存的 Aggregate Data;Row3 和 Row5 经由 Aggregate Function 计算后,更新 Key3 保存的 Aggregate Data。

在 executeOnBlock 完成后,每个线程都会有一个独立的 Aggregate Data。
在 mergeAndConvertBlocks 阶段会把其他 Aggregate Data 都合并到 Aggregate Data0 上面。
IAggregateFunction::merge 用于执行把所有线程计算的部分聚合结果聚合成一个最终聚合结果。
如下图所示,Aggregate Data 在合并的时候,同一个 Key 的数据会合并到一起,与其他 Key 互不干扰。

IAggregateFunction 是聚合函数的实现基类。接下来我们来看一下 IAggregateFunction 本身的接口。
class IAggregateFunction
{
public:
String getName() const = 0;
DataTypePtr getReturnType() const = 0;
void add(AggregateDataPtr __restrict place, const IColumn ** arg_columns, size_t row_num, Arena * arena) const = 0;
void merge(AggregateDataPtr __restrict place, ConstAggregateDataPtr rhs, Arena * arena) const = 0;
void insertResultInto(ConstAggregateDataPtr __restrict place, IColumn & to, Arena * arena) const = 0;
};add用于计算聚合结果并更新到place上merge用于将rhs里的聚合结果合并到placeinsertResultInto用于将place里保存的聚合结果输出成 Block
接下来我们以 Sum 这个聚合函数为例子来看一下聚合函数的执行过程。
template <typename T>
using AggregateFunctionSumSimple =
AggregateFunctionSum<T, typename NearestFieldType<T>::Type, AggregateFunctionSumData<typename NearestFieldType<T>::Type>>;
template <typename T, typename TResult, typename Data>
class AggregateFunctionSum final : public IAggregateFunctionDataHelper<Data, AggregateFunctionSum<T, TResult, Data>>
{
public:
void add(AggregateDataPtr __restrict place, const IColumn ** columns, size_t row_num, Arena *) const override
{
this->data(place).add(column.getData()[row_num]);
}
void merge(AggregateDataPtr __restrict place, ConstAggregateDataPtr rhs, Arena *) const override
{
this->data(place).merge(this->data(rhs));
}
};
template <typename T>
struct AggregateFunctionSumData
{
T sum{};
template <typename U>
void add(U value) { AggregateFunctionSumAddImpl<T>::add(sum, value); }
void merge(const AggregateFunctionSumData & rhs) { AggregateFunctionSumAddImpl<T>::add(sum, rhs.sum); }
}
template <typename T>
struct AggregateFunctionSumAddImpl
{
static void NO_SANITIZE_UNDEFINED ALWAYS_INLINE add(T & lhs, const T & rhs) { lhs += rhs; }
};实际的 Sum 实现带有很多优化,这里选择最简化的实现
对于 Sum,AggregateData 的实现是
AggregateFunctionSumData,内部维护一个T Sum保存聚合结果对于 Sum,
add和merge都是执行 += 操作。
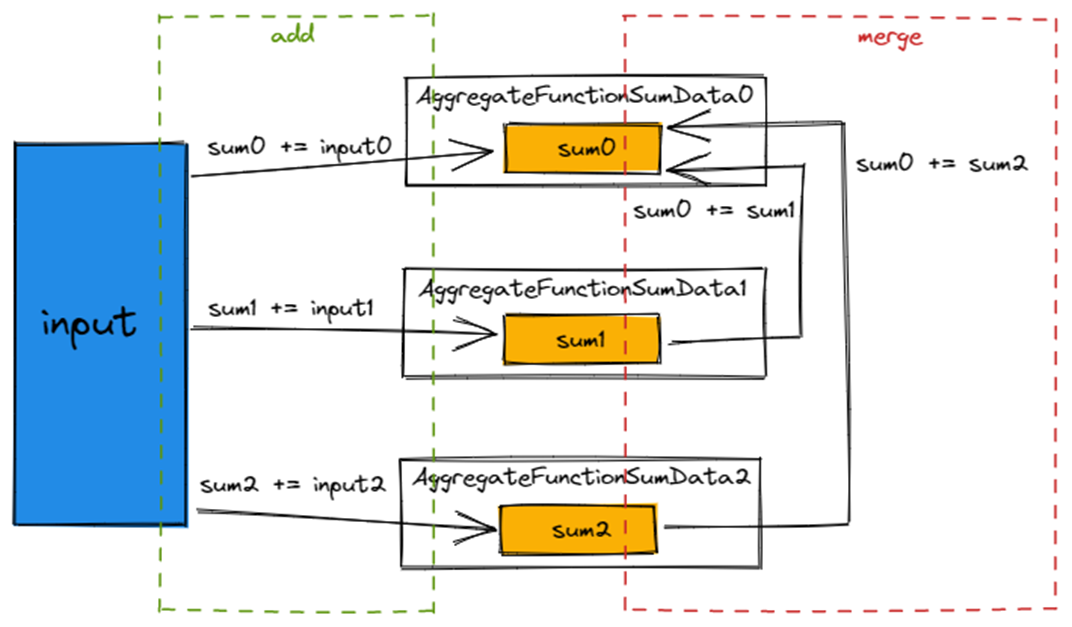
下图是对 Sum 执行过程的一个简化描述图。
add 阶段,Aggregator 会从 Input 读取数据,执行 sum += input,更新 Aggregate Data 里的聚合结果。在 add 完成后,会执行 sum0 += sum1 和 sum0 += sum2,将聚合结果合并成一个。最终输出 sum0 作为最终结果。
关注公众号:拾黑(shiheibook)了解更多 [广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 PingCAP
PingCAP
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 习近平对高速塌方灾害作出重要指示 4969486
- 2 恒山景区落石砸中游客致1死5伤 4999100
- 3 河南大学大礼堂着火 消防通报 4851238
- 4 “五一”假期各地“烟火气”升腾 4751371
- 5 小众城市突然爆红 4661662
- 6 昆明蓝莓12元1盒震惊外地游客 4572497
- 7 TVB视帝郭晋安官宣离婚 4492295
- 8 网友晒299元买朱珠价值5千二手包 4332591
- 9 广州地铁辟谣沥滘站漏雨 4231194
- 10 梅大高速塌方已致48人死亡 4129546