谷歌,再次把AI作画卷出新高度
点击上方蓝色字体“腾讯创业” 选择关注公众号
创投圈大小事,你都能尽在掌握

腾讯创业 | ID:qqchuangye
“谷歌AI作画自己卷自己。”
本文来源 “量子位”(ID:QbitAI),腾讯创业经授权后转载。
文/杨净 金磊 发自 凹非寺
Pneumonoultramicroscopicsilicovolcanoconiosis.

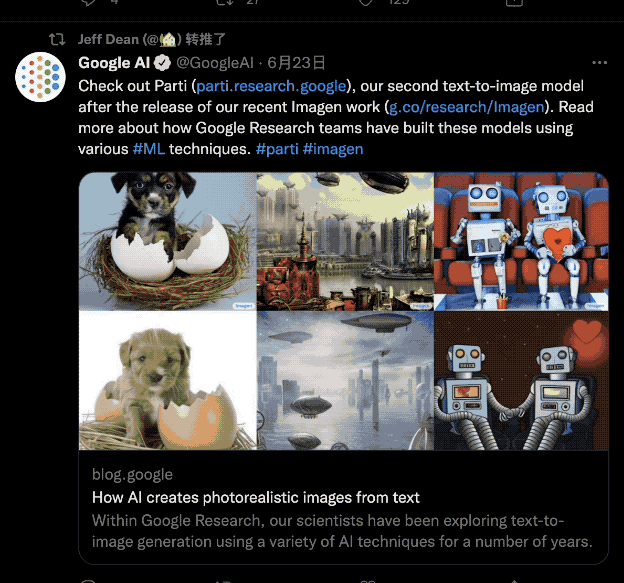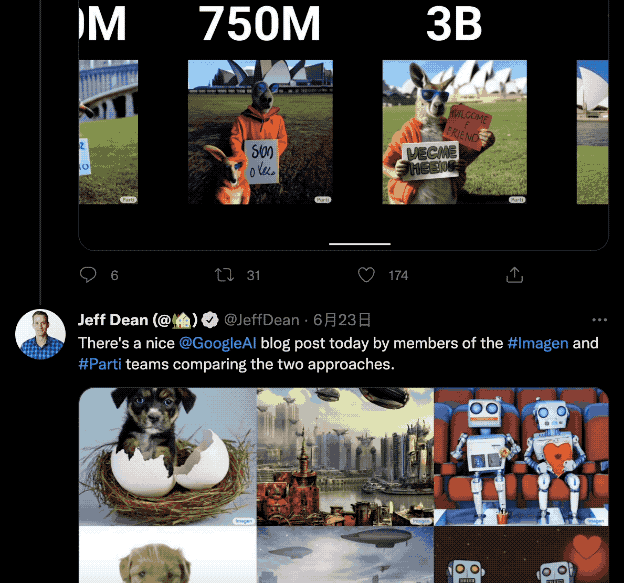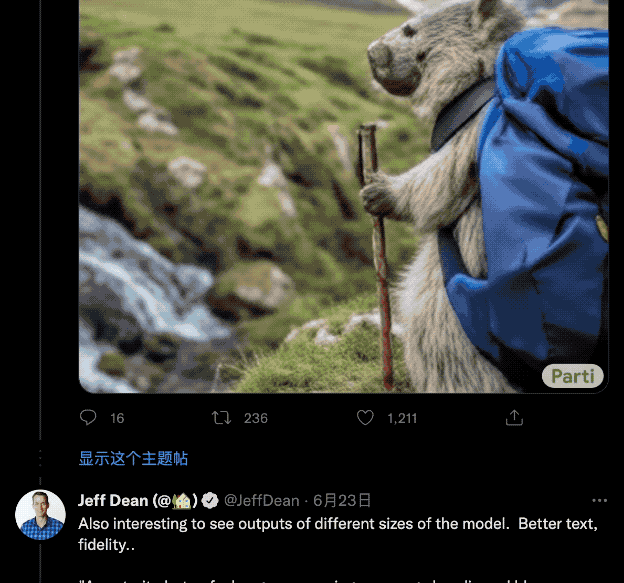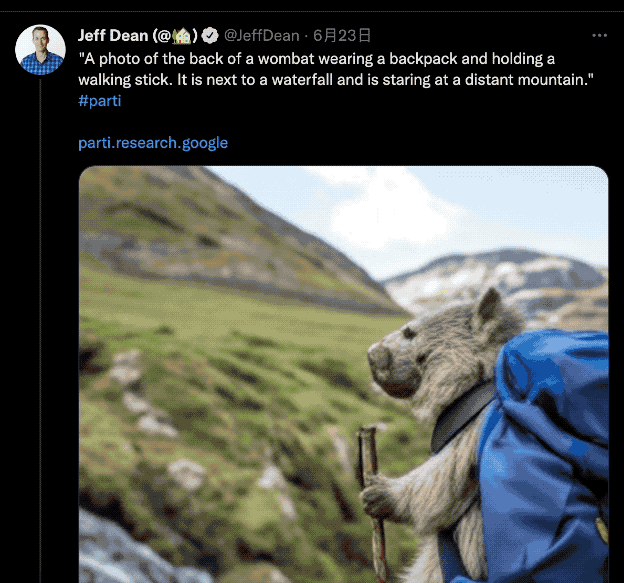
在把这个单词“投喂”给Parti后,它就能有模有样地生成多张合情合理的肺部疾病图片:
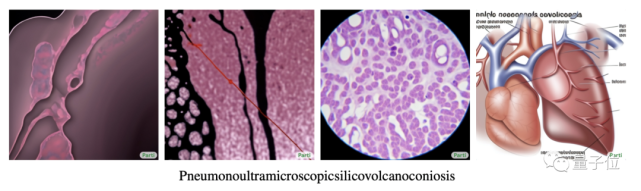
但这只是Parti小试牛刀的能力,据谷歌介绍,它是目前最先进的“文本转图像”AI。
例如,跟它说句:“把悉尼歌剧院和巴黎铁塔做个结合”,输出结果是这样的:

而且在算法路数上,还不同于谷歌自家的Imagen,Parti可以说是把“AI作画”卷出了新高度。

1
可扩展到200亿参数:更逼真,更“聪明”
事实上,Parti的能力还不止于此。
得益于模型可扩展到200亿参数,一方面,它生成的图像更加细节逼真。
不管是短短几个字,还是五十多个个单词的小段落,都能清晰展现出来。
比如,The back of a violin,小提琴的背面。



还有像“浣熊穿正装,头戴礼帽,拄着拐杖,拿着个垃圾袋”这种奇特的描述,它也能在整出花活的同时还不落细节。
风格上,则有梵高风、埃及法老风、像素风、中国传统绘画风、抽象主义风……


(Toad’ay,癞蛤蟆)
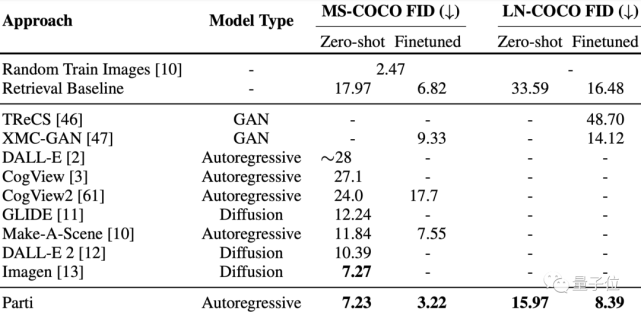
具体在测试结果上,MS-COCO、Localized Narrative(LN,4倍长的描述)上FID分数,Parti都取得了最先进的结果。
2
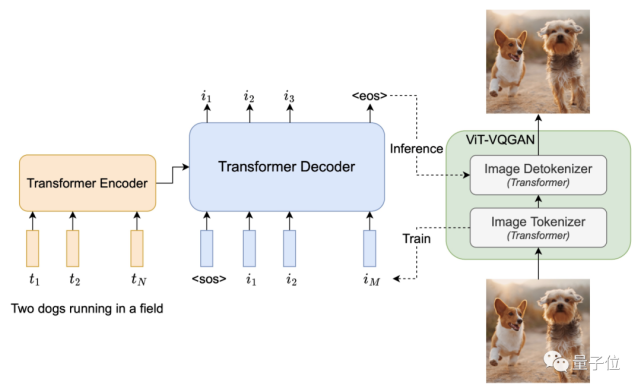
所有组件都是Transformer
时隔一个月,谷歌再把AI作画卷出新高度,结果作者却说:秘诀很简单。

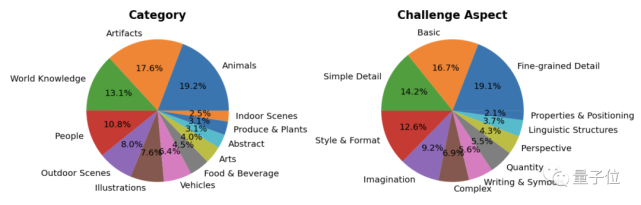


3
谷歌“自己卷自己”

 △左:Yuanzhong Xu;右:Thang Luong
△左:Yuanzhong Xu;右:Thang Luong

4
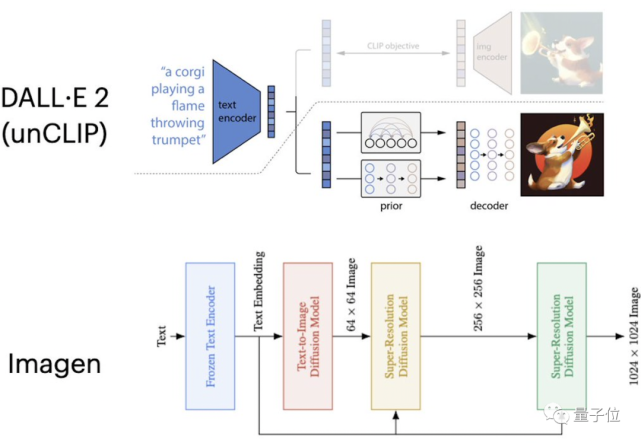
One More Thing
 △图:Imagen作画
△图:Imagen作画
 △ DALL·E作画
△ DALL·E作画

不过回归到这次的Parti,好玩归好玩,但还是有网友提出了“直击灵魂”的问题:

END
你怎么看谷歌的AI作画?
欢迎评论区留言,与大家分享。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 腾讯创业
腾讯创业
 关注网络尖刀微信公众号
关注网络尖刀微信公众号随时掌握互联网精彩







- 1 做大做强港口 4954847
- 2 525到底是什么日子 4954924
- 3 演员杜旭东疑似又为电诈拍广告背书 4802062
- 4 中国数字经济“长”得快 4788517
- 5 江西公交车失控坠落至平台 9人受伤 4627143
- 6 国防部:直至完全统一! 4543099
- 7 QQ的大哥官宣将关闭 4401460
- 8 江西公交坠落事故事发瞬间曝光 4388915
- 9 通渭县国际机场奠基?谣言! 4288137
- 10 83岁白胡子爷爷龙舟跳艄火遍全网 4113535