可微网络架构搜索能够大幅缩短搜索时间,但是稳定性不足。为此,UCLA 基于随机平滑(random smoothing)和对抗训练(adversarial training),提出新型 NAS 算法。
可微网络架构搜索(DARTS)能够大幅缩短搜索时间,但是其稳定性受到质疑。随着搜索进行,DARTS 生成的网络架构性能会逐渐变差。最终生成的结构甚至全是跳过连接(skip connection),没有任何卷积操作。在 ICML 2020 中,UCLA 基于随机平滑(random smoothing)和对抗训练(adversarial training),提出了两种正则化方法,大幅提升了可微架构搜索算法的鲁棒性。
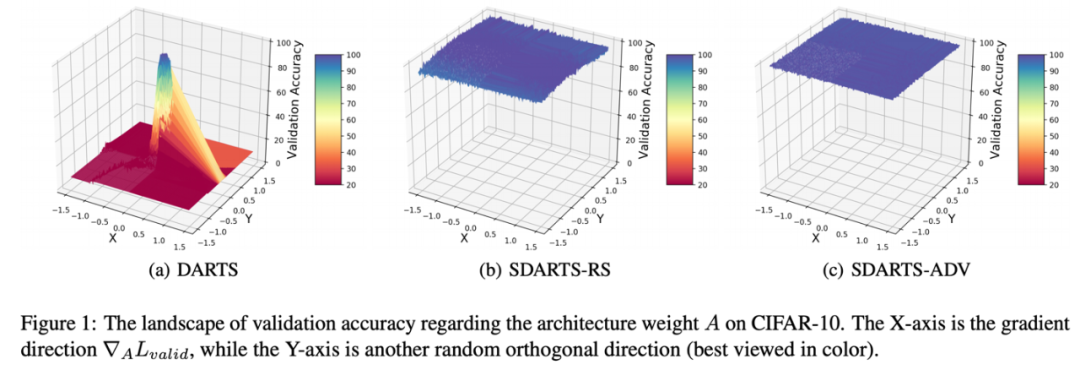
近期,可微架构搜索算法将 NAS 搜索时间缩短至数天,因而备受关注。然而,其稳定生成高性能神经网络的能力受到广泛质疑。许多研究者发现随着搜索进行,DARTS 生成的网络架构反而越来越差,最终甚至会完全变为跳过连接(skip connection)。为了支持梯度下降,DARTS 对于搜索空间做了连续化近似,并始终在优化一组连续可微的框架权重 A。但是在生成最终框架时,需要将这个权重离散化。本研究作者观察到这组连续框架权重 A 在验证集上的损失函数非常不平滑,DARTS 总是会收敛到一个非常尖锐的区域。因此对于 A 轻微的扰动都会让验证集性能大幅下降,更不用说最终的离散化过程了。这样尖锐的损失函数还会损害搜索算法在架构空间中的探索能力。于是,本文作者提出了新型 NAS 框架 SmoothDARTS(SDARTS),使得 A 在验证集上的损失函数变得十分平滑。提出 SDARTS,大幅提升了可微架构搜索算法的鲁棒性和泛化性。SDARTS 在搜索时优化 A 整个邻域的网络权重,而不仅仅像传统可微 NAS 那样只基于当前这一组参数。第一种方法优化邻域内损失函数的期望,没有提升搜索时间却非常有效。第二种方法基于整个邻域内的最差损失函数(worst-case loss),取得了更强的稳定性和搜索性能。
在数学上,尖锐的损失函数意味着其 Hessian 矩阵范数非常大。作者发现随着搜索进行,这一范数极速扩大,导致了 DARTS 的不稳定性。而本文提出的两种框架都有数学保障可以一直降低 Hessian 范数,这也在理论上解释了其有效性。
最后,本文提出的方法可以广泛应用于各种可微架构算法。在各种数据集和搜索空间上,作者发现 SDARTS 可以一贯地取得性能提升。
传统 DARTS 使用一组连续的框架权重 A,但是 A 最终却要被投射到离散空间以获得最终架构。这一步离散化会导致网络性能大幅下降,一个高性能的连续框架并不意味着能生成一个高性能的离散框架。因此,尽管 DARTS 可以始终减少连续框架在验证集上的损失函数,投射后的损失函数通常非常不稳定,甚至会突变得非常大。因此作者希望最终获得的连续框架在大幅扰动,例如离散化的情况下,仍然能保持高性能。这也意味了损失函数需要尽可能平滑,并保持很小的 Hessian 范数。因此本文提出在搜索过程中即对 A 进行扰动,这便会让搜索算法关注在平滑区域。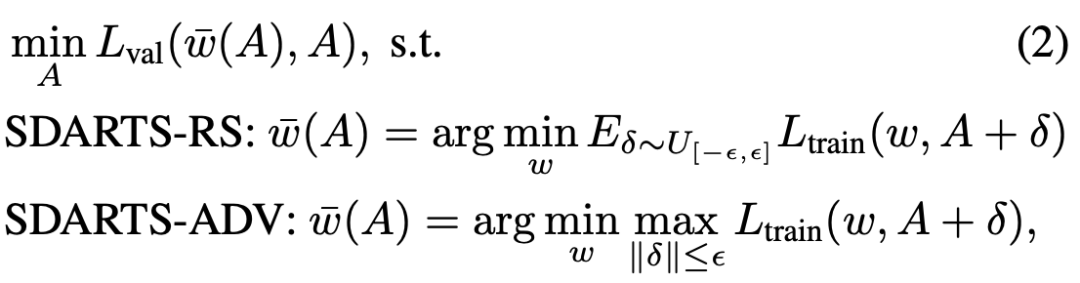
SDARTS-RS 基本随机平滑(random smoothing),优化 A 邻域内损失函数的期望。该研究在均匀分布中采样了随机噪声,并在对网络权重 w 进行优化前加到连续框架权重 A 之上。这一方法非常简单,只增加了一行代码并且不增加计算量,可作者发现其有效地平滑了在验证集上的损失函数。SDARTS-ADV 基于对抗训练(adversarial training),优化邻域内最差的损失函数,这一方法希望最终搜索到连续框架权重 A 可以抵御最强的攻击,包括生成最终架构的离散化过程。在这里,我们使用 PGD (projected gradient descent)迭代获得当前最强扰动。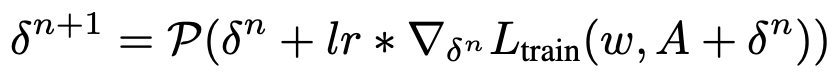
整个优化过程遵循可微 NAS 的通用范式,交替优化框架权重 A 和网络权重 w。
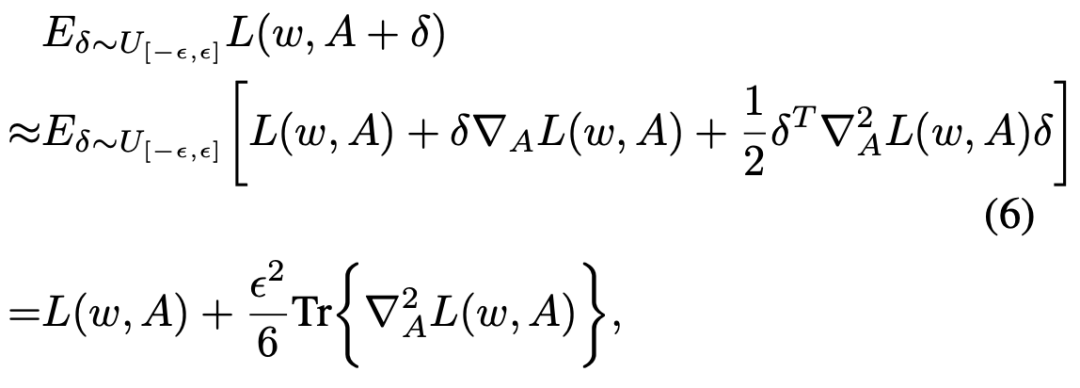
对 SDARTS-RS 的目标函数进行泰勒展开,作者发现这在搜索过程中,Hessian 矩阵的 trace norm 也在被一直减小。如果 Hessian 矩阵近似 PSD,那么近似于一直在减小 Hessian 的正特征值。相似地,在通常的范数选择下(2 范数和无穷范数),SDARTS-ADV 目标函数中第二项近似于被 Hessian 范数 bound 住。因此它也可以随着搜索降低范数。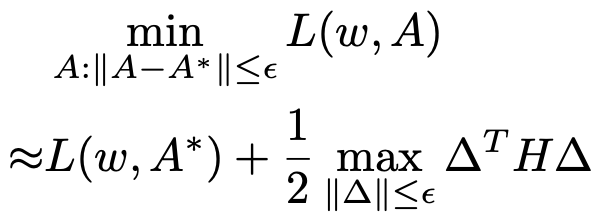
这些理论分析进一步解释了为何 SDARTS 可以获得平滑的损失函数,在扰动下保持鲁棒性与泛化性。这个 benchmark 含有 3 个不同大小的搜索空间,并且可以直接获得架构的性能,不需要任何训练过程。这也使本文可以跟踪搜索算法任意时刻得到架构的精确度,并比较他们的稳定性。如图 4 所示,DARTS 随着搜索进行生成的框架不断变差,甚至在最后的性能直接突变得很差。近期提出的一些新的改进算法,例如 NASP 与 PC-DARTS 也难以始终保持高稳定性。与之相比,SDARTS-RS 与 SDARTS-ADV 大幅提升了搜索稳定性。得益于平滑的损失函数,该研究提出的两种方法还具有更强的探索能力,甚至在搜索迭代了 80 轮之后仍能持续发现精度更高的架构。另外,作者还在图 5 中跟踪了 Hessian 范数的变化情况,所有 baseline 方法的范数都扩大了 10 倍之多,而本文提出的方法一直在降低该范数,这与上文的理论分析一致。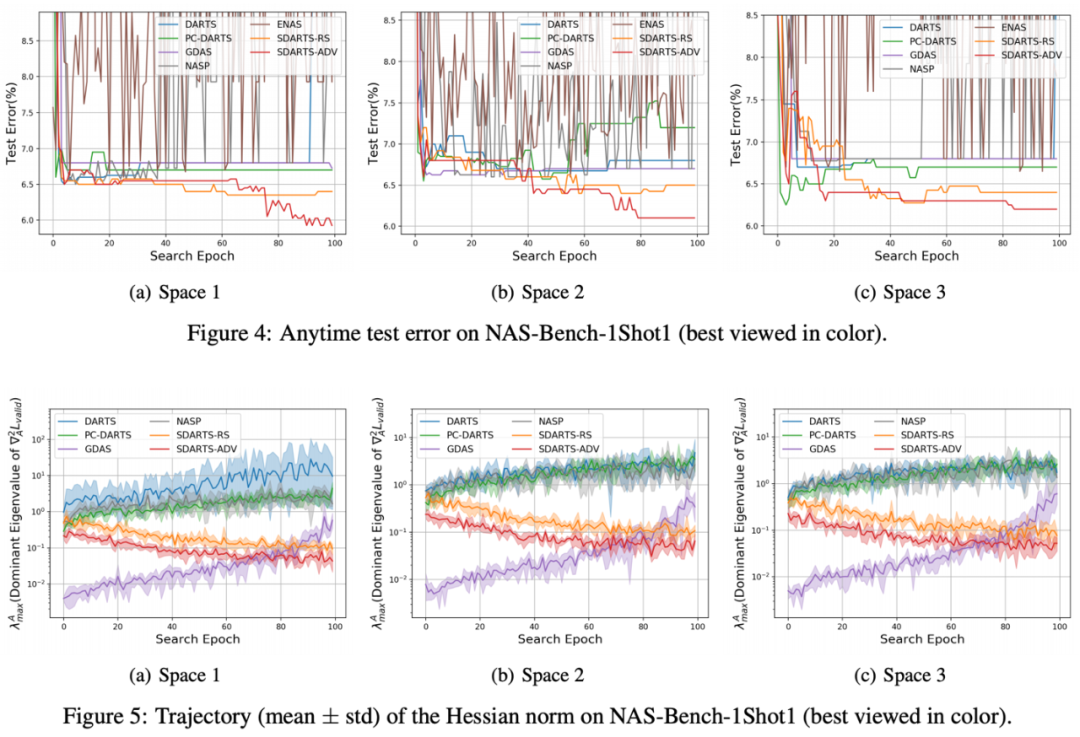
作者在通用的基于 cell 的空间上进行搜索,这里需要对获得架构进行 retrain 以获得其精度。值得注意的是,除了 DARTS,本文提出的方法可以普遍适用于可微 NAS 下的许多方法,例如 PC-DARTS 和 P-DARTS。如表 1 所示,作者将原本 DARTS 的 test error 从 3.00% 减少至 2.61%,将 PC-DARTS 从 2.57% 减少至 2.49%,将 P-DARTS 从 2.50% 减少至 2.48%。搜索结果的方差也由于稳定性的提升而减小。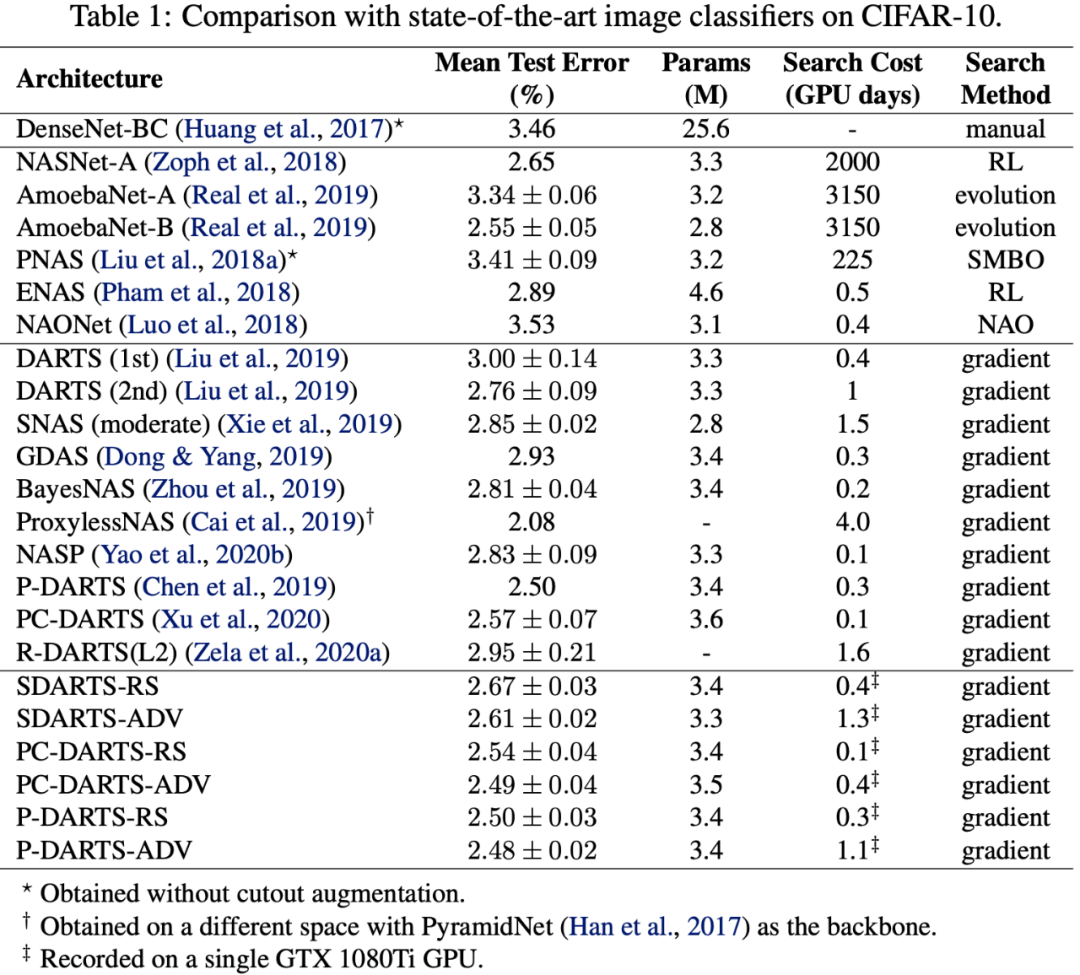
为了测试在大数据集上的性能,作者将搜索的架构迁移到 ImageNet 上。在表 2 中,作者获得了 24.2% 的 top1 test error,超过了所有相比较的方法。
作者还在另外 4 个搜索空间 S1-S4 和 3 个数据集上做实验。这四个空间与 CIFAR-10 上的搜索空间类似,只是包含了更少的操作,例如 S2 只包含 3x3 卷积和跳过连接,S4 只包括 3x3 卷积和噪声。在这些简化的空间上实验能进一步验证 SDARTS 的有效性。
如表 4 所示,SDARTS 在这 12 个任务中的 9 个中包揽了前两名,SDARTS-ADV 分别平均超过 DARTS、R-DARTS (L2)、DARTS-ES、R-DARTS (DP) 和 PC-DARTS 31.1%、11.5%、11.4%、10.9% 和 5.3%。7 月 23 日 20:00-21:00,小视科技副总裁、AI 研究院院长胡建国将带来线上分享,为大家详解这一工业级静默活体检测算法,期待与广大业内开发者和爱好者共同交流。识别海报二维码,添加机器之心小助手,进群一起看直播。

关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/






 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





