自 2017 年被提出以来,Transformer 已经席卷了整个 NLP 领域,红极一时的 BERT、GPT-2 都采用了基于 Transformer 的架构。既然这么好用,为什么不用到 CV 里?最近,Facebook AI 的研究者就进行了这方面的尝试,把 Transformer 用到了目标检测任务中,还取得了可以媲美 Faster R-CNN 的效果。
近年来,Transformer 成为了深度学习领域非常受欢迎的一种架构,它依赖于一种简单但却十分强大的机制——注意力机制,使得 AI 模型有选择地聚焦于输入的某些部分,因此推理更加高效。Transformer 已经广泛应用于序列数据的处理,尤其是在语言建模、机器翻译等自然语言处理领域。此外,它在语音识别、符号数学、强化学习等多个领域也有应用。但令人意外的是,计算机视觉领域一直还未被 Transformer 所席卷。为了填补这一空白,Facebook AI 的研究者推出了 Transformer 的视觉版本——Detection Transformer(以下简称 DETR),用于目标检测和全景分割。与之前的目标检测系统相比,DETR 的架构进行了根本上的改变。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。在性能上,DETR 可以媲美当前的 SOTA 方法,但架构得到了极大简化。具体来说,研究者在 COCO 目标检测数据集上将 DETR 与 Faster R-CNN 基线方法进行了对比,结果发现 DETR 在大型目标上的检测性能要优于 Faster R-CNN,但在小目标的检测上性能不如后者,这为今后 DETR 的改进提供了新的方向。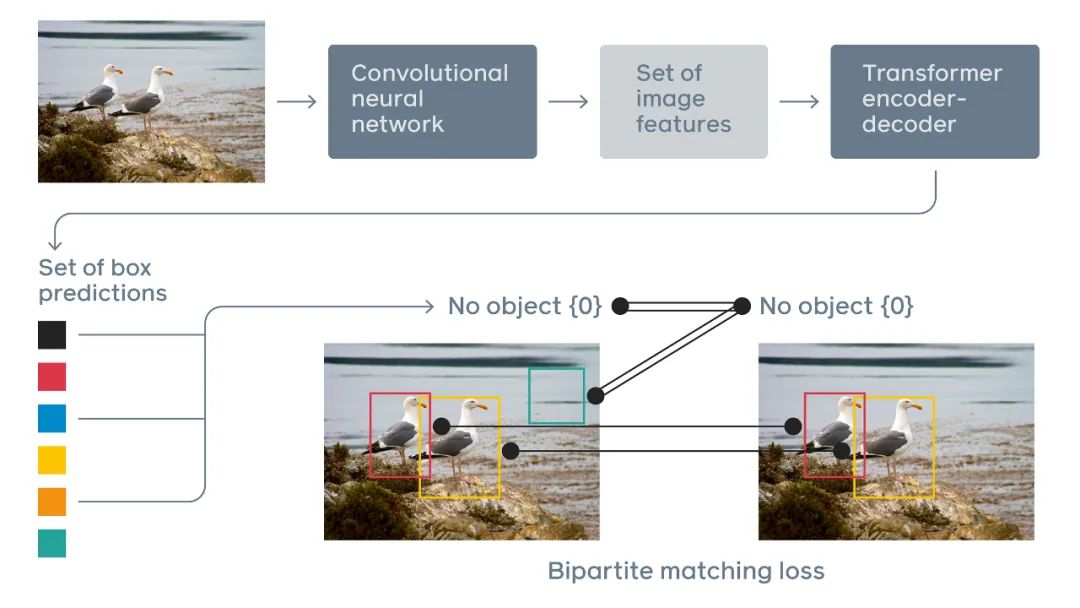
DETR 通过将一个常见 CNN 与 Transformer 结合来直接预测最终的检测结果。在训练期间,二分匹配(bipartite matching)向预测结果分配唯一的 ground truth 边界框。没有匹配的预测应生成一个「无目标」的分类预测结果。DETR 提供了一个更加简单、灵活的 pipeline 架构,需要的启发式更少。使用基本的架构块可以将推理压缩为 50 行简单的 Python 代码。此外,由于 Transformer 已经在多个领域被证明是一个强大的工具,Facebook 的研究者相信,如果进行进一步调参,DETR 的性能和训练效率还能得到进一步提升。论文链接:https://arxiv.org/pdf/2005.12872v1.pdf为了方便大家复现 DETR 的结果,Facebook 还在 GitHub 上开源了该模型的代码和预训练模型。项目地址:https://github.com/facebookresearch/detrFacebook 表示,基线 DETR 在单节点 8 个 V100 GPU 上训练了 300 个 epoch,每个 epoch 需要花费 28 分钟,因此训练 300 个 epoch 大约需要 6 天。他们在 GitHub 中提供了 150 个 epoch 的训练结果和日志供大家参考。另外,研究者还提供了 Colab Notebook,我们可以上传自己的图片进行预测。
不过,也有人对研究结果提出了质疑:「Faster RCNN 算哪门子 SOTA?」
的确,在目标检测领域,Faster RCNN 已经太老了,比最近的 ResNeSt 不知差了多少,拉这个出来对比性能确实有些牵强。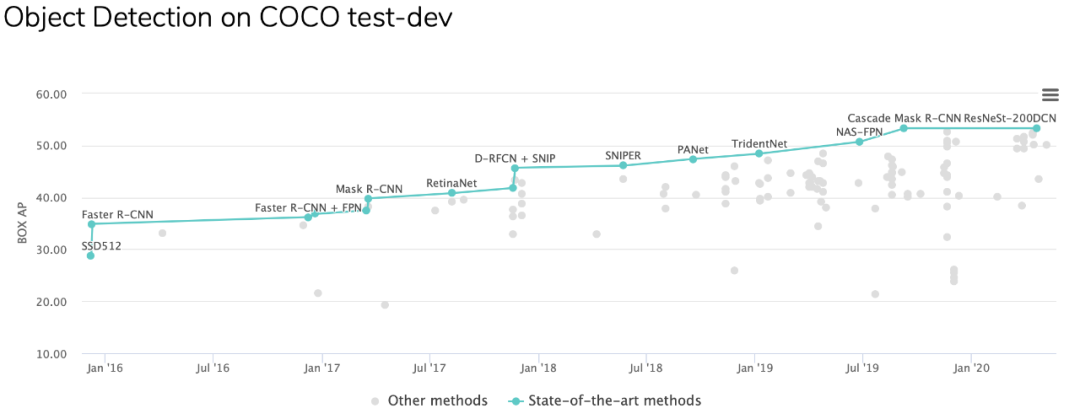
不过也有人认为,我们更应该看到的是论文创新的一面,毕竟作者在一个新的方向上做了尝试,而且也有一定的应用场景(如同时处理图像和文字这种多模态任务)。DETR 将目标检测任务视为一种图像到集合(image-to-set)的问题。给定一张图像,模型必须预测所有目标的无序集合(或列表),每个目标基于类别表示,并且周围各有一个紧密的边界框。这种表示方法特别适合 Transformer。因此,研究者使用卷积神经网络(CNN)从图像中提取局部信息,同时利用 Transformer 编码器-解码器架构对图像进行整体推理并生成预测。在定位图像中的目标以及提取特征时,传统计算机视觉模型通常使用基于自定义层的复杂且部分手动操作的 pipeline。DETR 则使用更为简单的神经网络,它可以提供一个真正的端到端深度学习解决方案。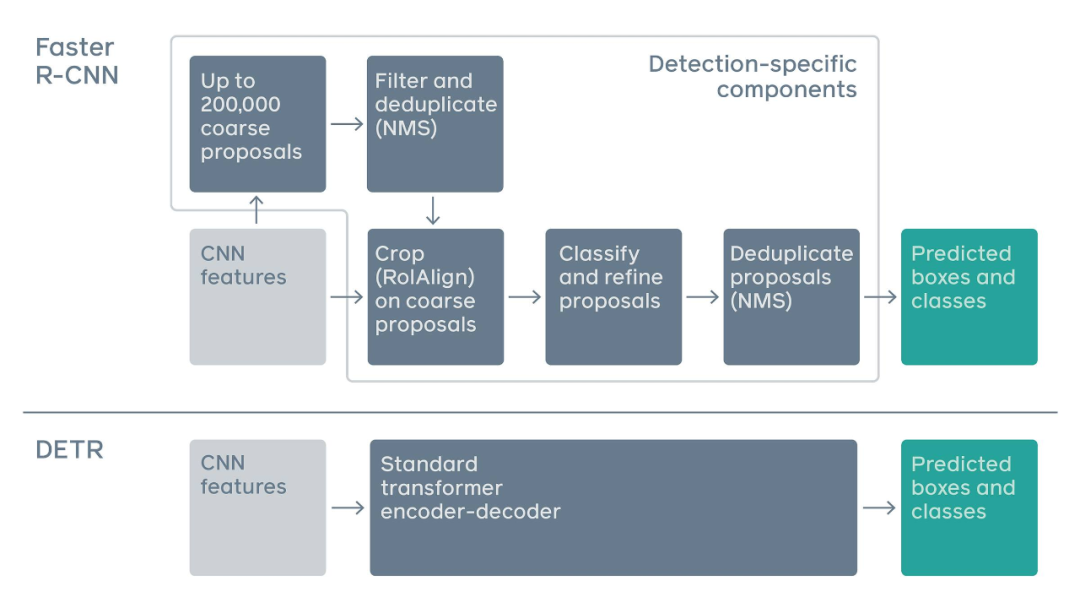
传统两阶段检测系统,如 Faster R-CNN,通过对大量粗糙候选区域的过滤来预测目标边界框。与之相比,DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。DETR 框架包含一个通过二分匹配做出独特预测的基于集合的全局损失,以及一个 Transformer 编码器-解码器架构。给定一个小集合固定的学得目标查询,DETR 对目标和全局图像背景的关系作出推理,从而直接并行输出最终的预测集。之前有研究者尝试将循环神经网络等架构用于目标检测,但由于这类架构是按序列而非并行做预测,因而速度慢且有效性低。Transformers 的自注意力机制使得 DETR 可以在图像以及预测的特定目标上执行全局推理。例如,该模型可以观察图像的其他区域以帮助确定边界框中的目标。此外,DETR 还可以基于图像中目标间的关系或相关性做出预测。举例而言,如果 DETR 预测到图像中包含一个站在沙滩上的人,那么它也会知道部分被遮挡的目标更有可能是冲浪板。相比之下,其他检测模型只能孤立地预测每个目标。研究者表示,DETR 还可以扩展至其他相关任务,比如全景分割,该任务旨在分割明显前景目标的同时为背景中的所有像素打上标签。从研究创新和信息推理方式两方面来说,将 Transformers 应用于视觉领域有助于缩小 NLP 和计算机视觉社区的差距。人们对同时处理视觉和文本输入这类型的任务有着很大的兴趣,比如 Facebook 最近推出的恶意模因挑战赛(Hateful Memes Challenge,检测恶意图文)。众所周知,传统架构处理这类双模态任务非常困难。DETR 的新型架构有助于提升计算机视觉模型的可解释性,并且由于其基于注意力机制,所以当它做预测时,很容易就能观察到网络正在查看图像的哪部分区域。最后,Facebook AI 的研究者希望 DETR 可以促进目标检测领域的进展,并开发出处理双模态任务的新方法。研究者将 DETR 得到的结果与 Faster R-CNN 在 COCO 数据集上进行了量化评估。之后为展示 DETR 的多功能与可扩展性,研究者提供了其在全景分割中的结果,在实验中保持 DETR 模型的权值不变,仅对一小部分扩展模块进行训练。下表展示了在 COCO 验证集上,DETR 与 Faster R-CNN 进行对比的结果。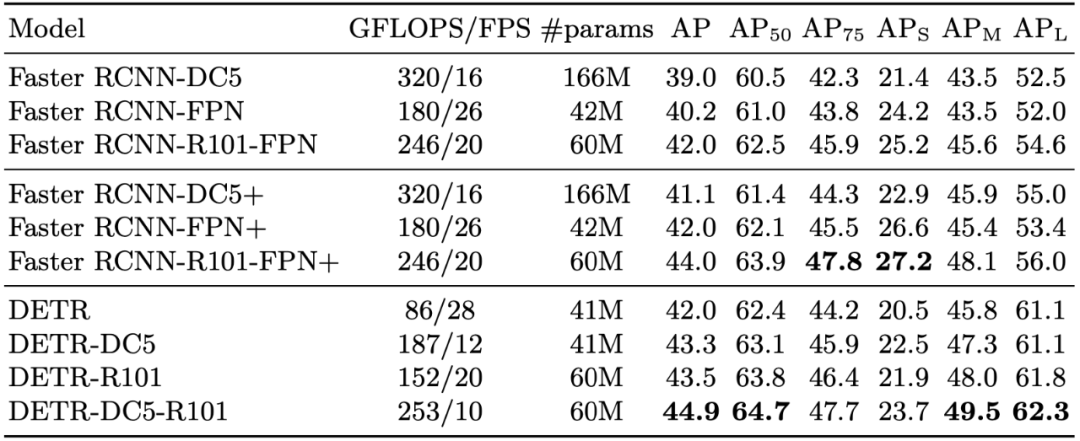
表 1:在 COCO 验证集上与 Faster R-CNN 的对比结果。结果表明,DETR 在大目标的检测中性能表现较好,在小目标的检测中表现较差。全景分割最近在计算机视觉社区受到了广泛关注。类似于 Faster R-CNN 的扩展 Mask R-CNN,DETR 同样能够很方便地通过在解码器输出顶端添加 mask head 来进行扩展。下图展示了 DETR 在全景分割任务中的量化结果。可以看到,DETR 以统一的方式为物体与材料(things and stuff)生成了匹配的预测蒙版。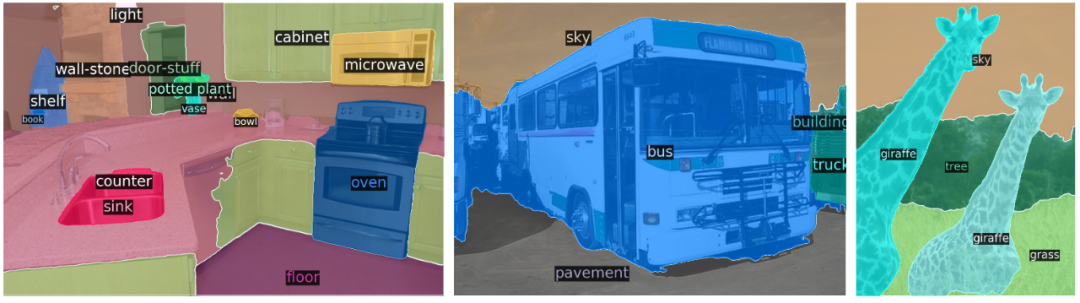
结果显示 DETR 尤其擅长对材料分类,研究者推测,解码器注意力机制具有的全局推理特性是产生这一结果的关键因素。在下表中,研究者将自己所提出的统一全景预测方法与区分物体和材料的其他方法进行了比较。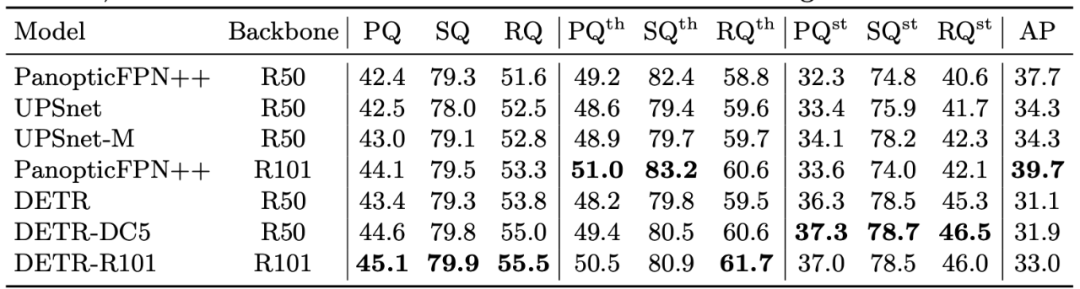
表 5:在 COCO 验证集上,将 DETR 与目前的 SOTA 方法进行比较。参考链接:https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers首届「马栏山」杯国际音视频算法大赛正在火热进行中。大赛聚焦图像和推荐、画质优化三大领域,设置包括视频特定点位追踪、视频推荐、画质损伤修复三大赛题。优秀参赛者不仅可获得奖金,获奖解决方案还有机会被应用于芒果 TV 核心领域,在校学生还将可能加入芒果 TV「青芒计划」,发放「special offer」。
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/







 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





