如何将目标检测和重识别融合进一个框架,帮助解决多目标跟踪任务?华中科技大学和微软亚洲研究院的研究者找出了这一方向的痛点所在,同时提出了一个简单而有效的新方法。该方法以 30 fps 运行时在公开数据集上的性能超越了之前的 SOTA 结果。

近年来,目标检测和重识别均取得长足进步,而它们正是多目标跟踪的核心组件。但是,没有太多研究人员试图用一个框架完成这两项任务,进而提升推断速度。然而最初朝着这个方向努力的研究者得到的结果却是性能下降,因为重识别任务无法得到恰当地学习。近期,华中科技大学和微软亚洲研究院的研究人员对这一失败背后的原因进行了挖掘,进而提出了一个简单的基线方法来解决这些问题。该方法以 30 fps 运行时在公开数据集上的性能超越了之前的 SOTA 结果。

FairMOT 在 MOT 挑战赛测试集上的效果。
多目标跟踪 (MOT) 是计算机视觉领域中的重要任务,当前最优的方法通常使用两个单独的模型:首先用检测模型定位图像中目标的边界框位置,然后用关联模型对每个边界框提取重识别 (Re-identification, Re-ID) 特征,并根据这些特征定义的特定度量将边界框与现有的一个跟踪结果联结起来。近年来,目标检测和 Re-ID 均取得巨大进步,并提升了目标跟踪的性能。但是,现有方法无法以视频帧速率执行推断,因为两个网络无法共享特征。随着多任务学习的成熟,结合目标检测和 Re-ID 的 one-shot 方法逐渐吸引越来越多的注意力。由于这两个模型共享大部分特征,因此它们有可能显著缩短推断时间。但是,one-shot 方法的准确率相比两阶段方法有显著下降,尤其是 ID 转换(identity switch)量大增的情况下。也就是说,把这两个任务合二为一并不简单,需要谨慎看待。哪些因素对目标跟踪结果影响最大?
华中科技大和微软亚研的这项研究没有借助训练 trick 提升跟踪准确率,而是试图分析「二合一」失败的原因,并提出了一种简单而有效的基线方法。
现有的 one-shot 跟踪器 [35,33] 均以锚点为基础,因为它们由目标检测器发展而来。但是,锚点却不适合学习 Re-ID 特征。原因如下:首先,对应于不同图像块的多个锚点可能负责估计同一个目标的 id,这导致严重的歧义(参见图 1)。此外,需要将特征图的大小缩小 1/8,以平衡准确率和速度。对于检测任务而言这是可以接受的,但对于 Re-ID 来说就有些粗糙了,因为目标中心可能无法与在粗糙锚点位置提取的特征一致。该研究对此提出的解决方案是:将 MOT 问题看作在高分辨率特征图上的像素级关键点(目标中心)估计和 id 分类问题。
图 1:(a) 尽管黄色和红色锚点的图像块不同,但它们估计的是同一个 ID(穿蓝色上衣的人)。此外,基于锚点的方法通常在粗糙网格上运行,因此在此类锚点(红色或黄色五角星)处提取的特征大概率无法与目标中心一致。(b) anchor-free 方法的歧义要少一些。这对于 MOT 问题尤其重要,因为 Re-ID 特征需要利用低级和高级特征来适应小型和大型目标。研究者通过实验发现,这对降低 one-shot 方法的 id 转换数量有所帮助,因为它提升了处理尺度变换的能力。之前的 Re-ID 方法通常学习高维特征,在其基准上达到了不错的结果。但是,该研究发现较低维度的特征对于 MOT 任务效果更好,因为该任务的训练图像比 Re-ID 少(由于 Re-ID 数据集仅提供剪裁后的人像,因此 MOT 任务不使用此类数据集)。学习低维特征有助于降低过拟合的风险,并提升目标跟踪的稳健性。首先,采用 anchor-free 目标检测方法,估计高分辨率特征图上的目标中心。去掉锚点这一操作可以缓解歧义问题,使用高分辨率特征图可以帮助 Re-ID 特征与目标中心更好地对齐。然后,添加并行分支来估计像素级 Re-ID 特征,这类特征用于预测目标的 id。具体而言,学习既能减少计算时间又能提升特征匹配稳健性的低维 Re-ID 特征。在这一步中,研究者用深层聚合算子(Deep Layer Aggregation,DLA)[41] 来武装主干网络 ResNet-34 [13],从而融合来自多个层的特征,处理不同尺度的目标。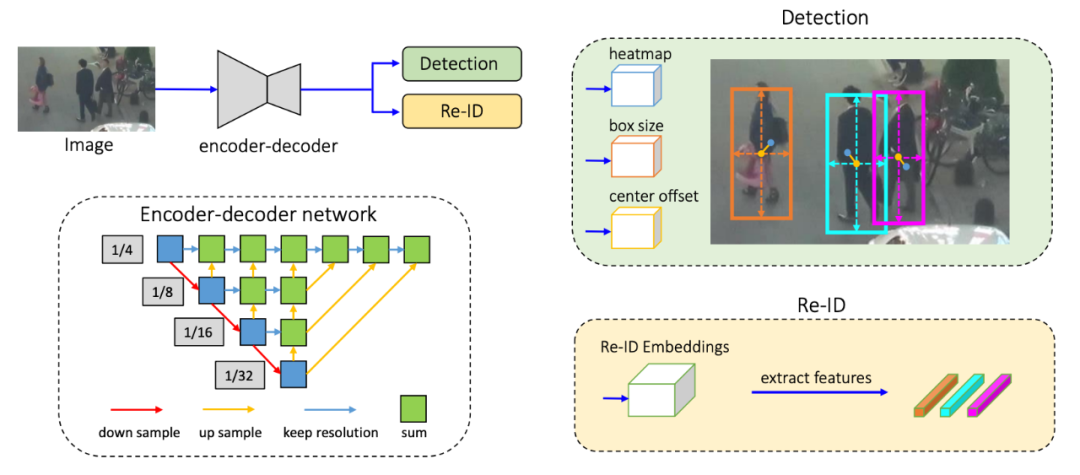
图 2:该研究提出的 one-shot MOT 跟踪器图示。首先将输入图像馈入编码器-解码器网络,以提取高分辨率特征图(步幅=4);然后添加两个简单的并行 head,分别预测边界框和 Re-ID 特征;最后提取预测目标中心处的特征进行边界框时序联结。研究者在 MOT 挑战赛基准上借助评估服务器评估了本文提出的方法。与其他在线跟踪器相比,本文提出的方法在 2DMOT15、MOT16、MOT17 及 MOT20 数据集上均名列第一。此外,在 2DMOT15、MOT16 和 MOT17 数据集上,该方法的性能还优于离线跟踪器(MOT20 是个新数据集,之前研究没有相关结果)。虽然结果比较惊艳,但该方法非常简单,且运行速率为 30 FPS。1. 基于锚点(anchor-based)和无锚点(anchor-free)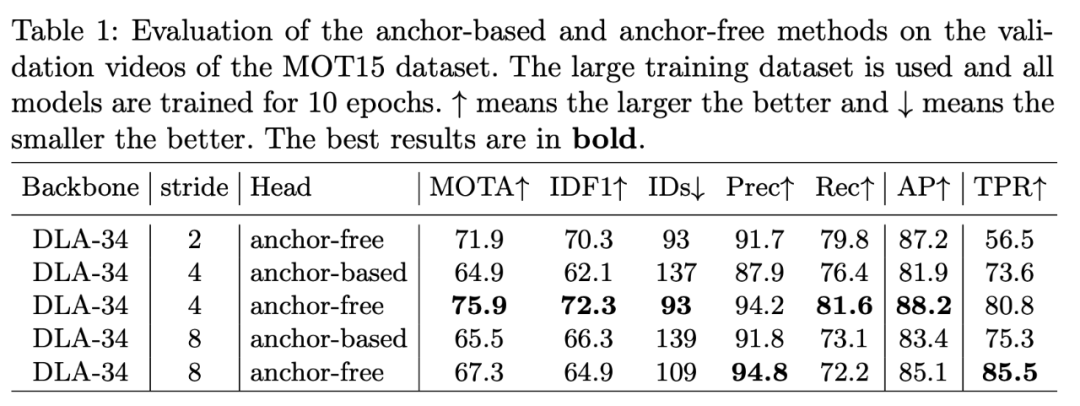
表 1:在 MOT15 数据集上,基于锚点和无锚点方法在验证视频上的评估结果。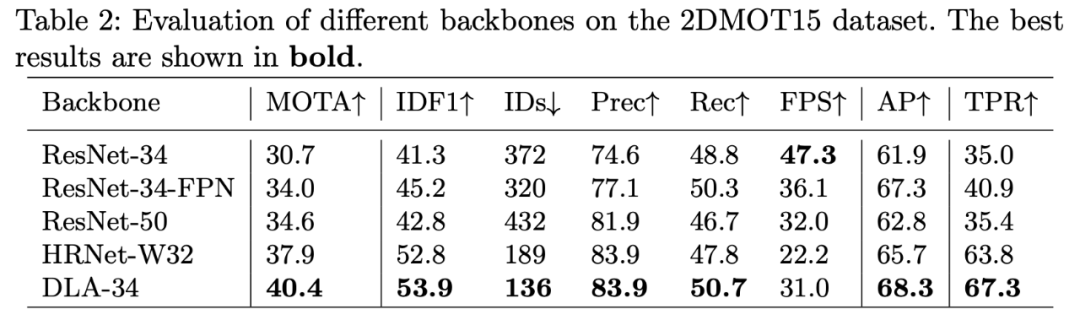
表 2:不同主干网络在 2DMOT15 数据集上的评估结果。
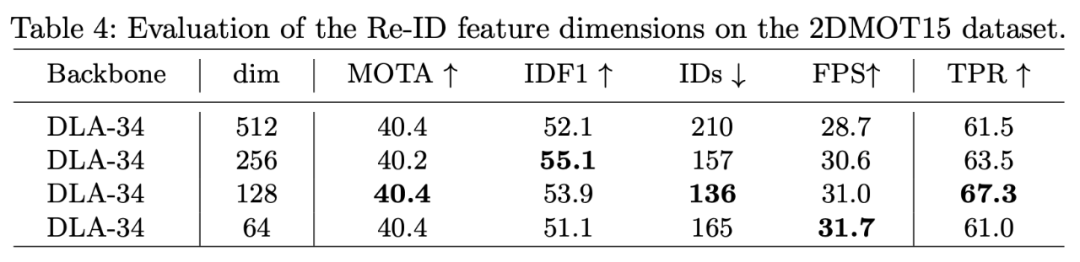
表 4:不同 Re-ID 特征维度在 2DMOT15 数据集上的评估结果研究者将本文提出的方法与当前最佳方法进行了对比,包括 one-shot 方法和 two-step 方法。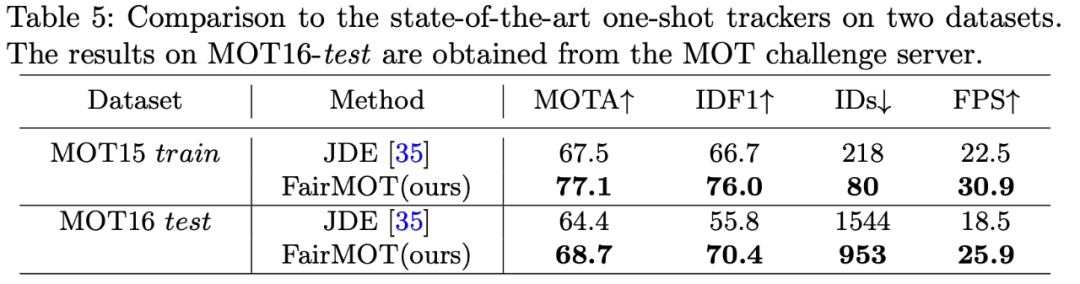
表 5:在两个数据集上与当前最佳 one-shot 跟踪器的对比结果。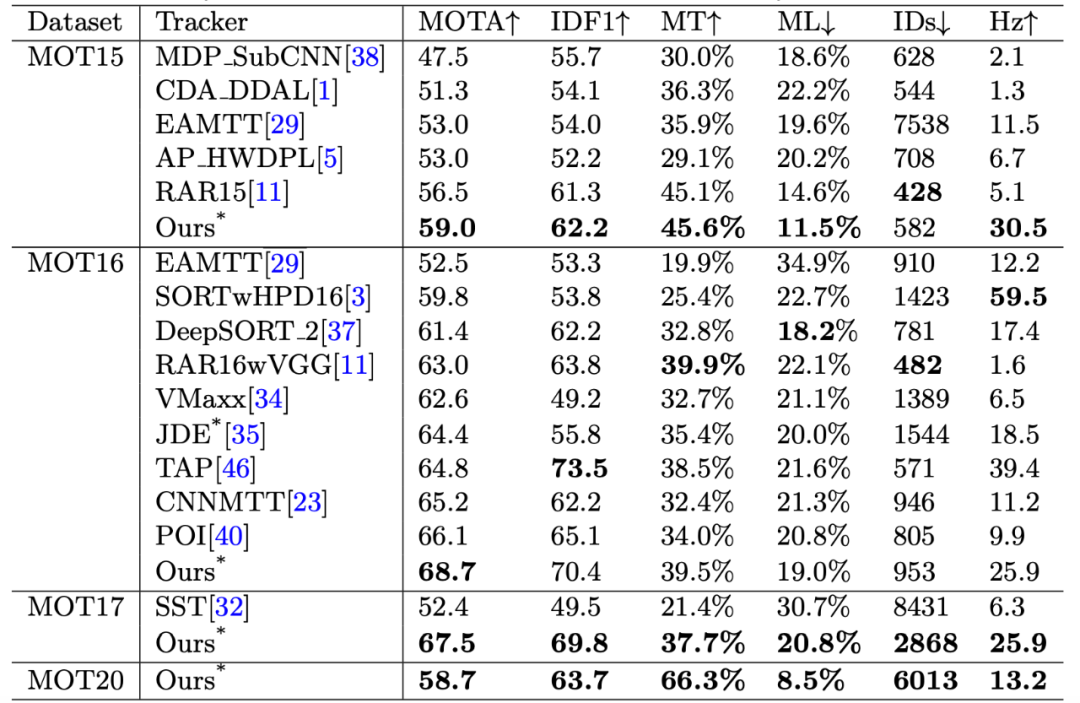
表 6:与「private detector」设定下的 SOTA 结果进行对比。
✄------------------------------------------------加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com投稿或寻求报道:content@jiqizhixin.com广告 & 商务合作:bd@jiqizhixin.com关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/


![不是小luna 虎年大吉 新的一年大家都要旺旺旺 发大财 好运来 [心][心]](https://imgs.knowsafe.com:8087/img/aideep/2022/2/3/dff28a8e50a198b2bf32847fa74799e3.jpg?w=250)



 机器之心
机器之心
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





