

不久前,人力资源社会保障部发布了一种炙手可热的新职业:AI训练师。没想到,浙江大学与阿里安全的人工智能训练师马上创造出一个 “AI训练师助手”,高效打造AI深度模型,应对海量应用场景的增加,让AI训练模型面对新场景时不用从头学习,直接从已经存在的模型上迁移,迅速获得别人的知识、能力,成为全新的AI模型,而且能将模型周期从一个月缩短为一天。随后,阐述这种让AI训练AI,提升模型生产效率的论文被计算机视觉顶会CVPR 2020 接收(Oral)。现在,视频、直播成为互联网内容消费的重要载体,内容创作爆发,创作形式自由度高带来了许多潜在安全威胁。好消息是,AI深度模型被大规模用于多媒体内容的识别、检测、理解上,用以狙击含有不良内容的传播。为了提升检测的准确性,面向不同场景必须使用不同的AI模型。但是,由于媒体场景、细分领域多,如何才能高效生产不同AI 深度模型?目前实现这一目标最流行的方法是迁移学习。浙江大学和阿里安全发现,两个预训练深度模型所提取的特征之间的迁移能力可由它们对应的深度归因图谱之间的相似性来衡量。相似程度越高,从不同的预训练深度模型中获得的特征相关性就越大,特征的相互迁移能力也就越强。而且,“AI训练师助手”还知道从什么模型迁移知识,用模型的哪个部分迁移能最好地完成任务。也就是说,他们发现了让小白模型向AI深度模型学习的高效学习方法。得益于大量高质量标注数据、高容量的模型架构、高效率的优化算法以及高性能计算硬件的发展,过去十年里深度学习在计算机视觉、自然语言处理以及生物信息学等领域取得了举世瞩目的进步。随着深度学习取得了前所未有的成功,越来越多的科研人员和工业工作者愿意开源他们训练好的模型来鼓励业界进一步的研究。目前,预训练好的深度学习模型可以说是无处不在。阿里安全图灵实验室高级算法专家析策认为,我们不仅处在一个大数据时代,同时也正在步入一个“大模型”时代。与大数据相似,海量模型形成的模型仓库也蕴含了巨大的潜在价值。这些预训练的深度模型已经消耗了大量的训练时间以及大规模高质量的标注数据等昂贵的计算资源。如果这些预训练的模型能够被合理地重新使用,那么在解决新任务时的对训练时间以及训练数据的依赖就会显著降低。目前实现这一目标最流行的方法就是迁移学习。在基于深度模型的跨任务的迁移学习中,模型微调是一种使用最广泛并且有效的方法。该方法以一个预先训练的模型作为起点,固定模型的一部分参数以降低模型优化空间,利用新任务有限的数据训练剩余的参数,使得模型能够在新任务上获得成功。虽然这种方法在一些具体问题中取得了一定的成效,但是当前这些迁移学习方法忽略了两个重要的问题:面对海量的预训练好的深度模型,选择哪个模型解决当前任务能够取得最好的效果;给定一个预训练好的模型,应该固定哪些层的参数以及优化哪些层才能够取得最优的迁移效果。目前的模型选择通常是盲目地采用ImageNet的预训练模型。然而,ImageNet预训练的模型并不总是对所有任务产生令人满意的性能,特别是当任务与ImageNet数据上定义的任务有显著差异时。而模型微调时参数优化临界点的选择往往依赖于经验。但是,由于最优的优化临界点取决于各种因素,如任务相关性和目标数据量等,依赖经验做出的选择往往很难保证最优。 不同任务下深度神经网络提取特征的可迁移性为了解决上述问题,浙江大学和阿里安全发起了这项研究:在不同任务下训练的深度神经网络提取的特征之间的可迁移性。Zamir等人[1]对不同任务间的迁移关系作了初步的研究。他们提出了一种全计算的方法,称为taskonomy,来测量任务的可迁移性。然而,taskonomy中有三个不可忽视的局限性,极大地阻碍了它在现实问题中的应用。首先,它的计算成本高得令人望而却步。在计算给定任务集合中两两任务之间的迁移关系时,计算成本会随集合中任务数量的增加而呈平方性地增长,当任务数量很大时,计算成本会变得非常昂贵。第二个限制是,它采用迁移学习来建立任务之间的迁移关系,这仍然需要大量的标记数据来训练转移模型。然而,在许多情况下,我们只能获取训练好的模型,并不能够获取到相应的训练数据。最后,taskonomy只考虑不同模型或任务之间的可迁移性,而忽略了不同层之间的可迁移性,不能够用来解决微调模型时临界点的选择问题。衡量从不同预训练深度模型中提取到特征间的可迁移性,主要障碍是深度模型自身的黑箱性质。由于从不同的预训练深度模型中学习到的特征是不可解释的,而且处在不同的嵌入空间中,直接计算特征间的可迁移性非常困难。为了推导预训练深度模型中提取到特征间的可迁移性,研究者们首先给出了可迁移性的严格定义。在该定义下,预训练模型的选择和模型微调时临界点的选择实际上是该迁移性定义下的两个特例。然后,这篇论文提出了深度归因图谱(DEeP Attribution gRAph, DEPARA)来表示在预训练深度模型中学习到的知识。在深度归因图谱中,节点对应于输入,并由模型在输入数据上归因形成的归因图[2]来表达。边表示输入数据之间的关联,通过它们在预训练深度模型特征空间中的相似度来度量,如图1所示。由于不同预训练深度模型中的深度归因图谱是在相同的输入集上定义的,它们实际上处于相同的空间内,因此两个预训练深度模型所提取的特征之间的迁移能力可直接由它们对应的深度归因图谱之间的相似性来衡量。相似程度越高,从不同的预训练深度模型中获得的特征相关性就越大,特征的相互迁移能力也就越强。这项研究通过大量实验证明了该方法应用于任务间迁移关系度量以及模型微调时临界点选择的有效性。直接计算上述公式定义的迁移性需要大量标注数据且非常耗时。本文提出通过计算影响迁移性的两个重要因素,来做近似估计。
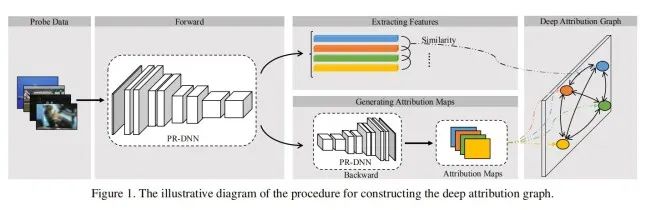
不同任务下深度神经网络提取特征的可迁移性为了解决上述问题,浙江大学和阿里安全发起了这项研究:在不同任务下训练的深度神经网络提取的特征之间的可迁移性。Zamir等人[1]对不同任务间的迁移关系作了初步的研究。他们提出了一种全计算的方法,称为taskonomy,来测量任务的可迁移性。然而,taskonomy中有三个不可忽视的局限性,极大地阻碍了它在现实问题中的应用。首先,它的计算成本高得令人望而却步。在计算给定任务集合中两两任务之间的迁移关系时,计算成本会随集合中任务数量的增加而呈平方性地增长,当任务数量很大时,计算成本会变得非常昂贵。第二个限制是,它采用迁移学习来建立任务之间的迁移关系,这仍然需要大量的标记数据来训练转移模型。然而,在许多情况下,我们只能获取训练好的模型,并不能够获取到相应的训练数据。最后,taskonomy只考虑不同模型或任务之间的可迁移性,而忽略了不同层之间的可迁移性,不能够用来解决微调模型时临界点的选择问题。衡量从不同预训练深度模型中提取到特征间的可迁移性,主要障碍是深度模型自身的黑箱性质。由于从不同的预训练深度模型中学习到的特征是不可解释的,而且处在不同的嵌入空间中,直接计算特征间的可迁移性非常困难。为了推导预训练深度模型中提取到特征间的可迁移性,研究者们首先给出了可迁移性的严格定义。在该定义下,预训练模型的选择和模型微调时临界点的选择实际上是该迁移性定义下的两个特例。然后,这篇论文提出了深度归因图谱(DEeP Attribution gRAph, DEPARA)来表示在预训练深度模型中学习到的知识。在深度归因图谱中,节点对应于输入,并由模型在输入数据上归因形成的归因图[2]来表达。边表示输入数据之间的关联,通过它们在预训练深度模型特征空间中的相似度来度量,如图1所示。由于不同预训练深度模型中的深度归因图谱是在相同的输入集上定义的,它们实际上处于相同的空间内,因此两个预训练深度模型所提取的特征之间的迁移能力可直接由它们对应的深度归因图谱之间的相似性来衡量。相似程度越高,从不同的预训练深度模型中获得的特征相关性就越大,特征的相互迁移能力也就越强。这项研究通过大量实验证明了该方法应用于任务间迁移关系度量以及模型微调时临界点选择的有效性。直接计算上述公式定义的迁移性需要大量标注数据且非常耗时。本文提出通过计算影响迁移性的两个重要因素,来做近似估计。
1. 包含性:要使得特征迁移在目标任务上取得较为理想的效果,源任务的训练的模型生成的特征空间应该包含解决目标任务所需的足够信息。包容性是迁移学习取得成功的一个比较基本的条件。2. 易用性:特征空间应该已经经过充分的学习并抽象到比较高的层次,这样才能够在有限的标注数据下很好地解决目标任务。如果不要求特征的易用性,那么原始的输入总是比经过深度网路处理的特征包含更多的信息。然而由于原始的数据没有经过任何知识提取与抽象,并不能够很好的迁移到新任务中。 深度归因图谱
深度归因图谱 如何利用深度归因图来解决两个迁移性问题
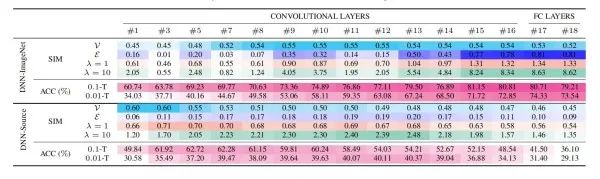
如何利用深度归因图来解决两个迁移性问题 实验上图是对于不同视觉任务所生成的深度归因图的可视化结果。从图中可以看出有一些任务生成非常相似的归因图以及样本之间的关系,然而有些生成的结果则非常不同。例如,Rgb2depth和Rgb2mist生成了非常相似的归因图和关系图,然而它们的结果和自编码器的结果非常不同。事实上,在任务分类法中,Rgb2depth和Rgb2mist彼此间具有很高的迁移性,但它们到自编码器的迁移性相对较低。此外,任务分类法采用层次聚类的方式把任务划分为四组:2D任务(蓝色),3D任务(绿色),几何任务(红色)以及语义任务(品红色)。图中选取了2个3D任务,3个2D任务,2个几何任务以及2个语义任务作可视化。任务分类法在这些任务上生成的任务相似树绘制在任务名称的上方。从图可以看出,在每个任务组内部,深度归因图谱生成较为相似的节点以及边。论文中采用PR曲线来评估方法效果,实验结果如上图,可以看到论文中提出的深度归因图方法(DEPARA)与taskonomy(Oracle)实验的结果具有很高的相似性,且通过消融实验可知,只采用图中节点相似性(DEPARA-V)和只采用图中边相似性(DEPARA-E)计算得到的迁移性准确度都远远不如图相似性(DEPARA),这意味着节点和边都对结果起着重要作用,是不可分割的。另外,论文中的方法(DEPARA)好于SOTA(RSA),证明了这是一种更加有效的计算迁移性的方案。在Syn2Real-C数据集(包含有合成图像的数据域以及真实图像的数据域)上进行层迁移的实验,分别考虑了两种源模型(在合成数据域上训练的模型和在ImageNet[6]上预训练的模型)来进行迁移至真实数据域。在迁移时,只利用了1%(0.01-T)和10%(0.1-T)的标注数据来进行训练,观察迁移效果和深度归因图相似性之间的关系。根据上图中颜色的深浅可知,对于两种不同的源模型,迁移效果越好的层,计算得到的深度归因图相似性越高,迁移效果越差的层,计算得到的深度归因图相似性也越低,验证了论文中方法的准确性。有趣的是,对于在ImageNet上预训练和合成数据域上预训练的源模型来说,尽管具有最好的迁移效果的层并不相同,但是论文中的方法都能很好地进行指示。而且,对于1%和10%两种不同的模式,这种方法通过设定不同的λ超参数,也依旧能挑选出迁移效果最好的那些层。从效果上来看,无论是从节点V还是边E的相似性比较来看,DNN-ImageNet都比DNN-Source具有更好的迁移性,这是因为尽管DNN-Source和目标任务学习的是同一物体的图像,但是他们的数据域相差太大,导致需要花费更多的成本去重建目标任务的特征空间。值得注意的是,有些层用于迁移甚至出现了负迁移的现象,负迁移经常出现在当用于迁移的源数据域和目标数据域相差很大的情况下,这说明在实验中,挑选一个合适的层用于迁移是十分重要的。上图是层迁移实验中的训练曲线,可以看到,由DEPARA挑选出来的层,迁移效果要好于其他层。而且,相比于DNN-Source,DNN-ImageNet中的训练曲线明显更加地平滑,这也恰恰证明了迁移性越好的模型,在迁移时所花费的重训练的成本就越低,也越容易地迁移至目标任务。“在‘AI训练师助手’的指导下,单个AI模型的生产周期从1个月降到1天,我们就能更快地发现不同的内容风险。”析策希望,欺凌、色情、暴力、误导等不良内容不会成为人们消费大量图像视频内容付出的代价,AI 技术可以更快地把不良内容挡在第一线。https://arxiv.org/abs/2003.07496https://github.com/zju-vipa/DEPARA
实验上图是对于不同视觉任务所生成的深度归因图的可视化结果。从图中可以看出有一些任务生成非常相似的归因图以及样本之间的关系,然而有些生成的结果则非常不同。例如,Rgb2depth和Rgb2mist生成了非常相似的归因图和关系图,然而它们的结果和自编码器的结果非常不同。事实上,在任务分类法中,Rgb2depth和Rgb2mist彼此间具有很高的迁移性,但它们到自编码器的迁移性相对较低。此外,任务分类法采用层次聚类的方式把任务划分为四组:2D任务(蓝色),3D任务(绿色),几何任务(红色)以及语义任务(品红色)。图中选取了2个3D任务,3个2D任务,2个几何任务以及2个语义任务作可视化。任务分类法在这些任务上生成的任务相似树绘制在任务名称的上方。从图可以看出,在每个任务组内部,深度归因图谱生成较为相似的节点以及边。论文中采用PR曲线来评估方法效果,实验结果如上图,可以看到论文中提出的深度归因图方法(DEPARA)与taskonomy(Oracle)实验的结果具有很高的相似性,且通过消融实验可知,只采用图中节点相似性(DEPARA-V)和只采用图中边相似性(DEPARA-E)计算得到的迁移性准确度都远远不如图相似性(DEPARA),这意味着节点和边都对结果起着重要作用,是不可分割的。另外,论文中的方法(DEPARA)好于SOTA(RSA),证明了这是一种更加有效的计算迁移性的方案。在Syn2Real-C数据集(包含有合成图像的数据域以及真实图像的数据域)上进行层迁移的实验,分别考虑了两种源模型(在合成数据域上训练的模型和在ImageNet[6]上预训练的模型)来进行迁移至真实数据域。在迁移时,只利用了1%(0.01-T)和10%(0.1-T)的标注数据来进行训练,观察迁移效果和深度归因图相似性之间的关系。根据上图中颜色的深浅可知,对于两种不同的源模型,迁移效果越好的层,计算得到的深度归因图相似性越高,迁移效果越差的层,计算得到的深度归因图相似性也越低,验证了论文中方法的准确性。有趣的是,对于在ImageNet上预训练和合成数据域上预训练的源模型来说,尽管具有最好的迁移效果的层并不相同,但是论文中的方法都能很好地进行指示。而且,对于1%和10%两种不同的模式,这种方法通过设定不同的λ超参数,也依旧能挑选出迁移效果最好的那些层。从效果上来看,无论是从节点V还是边E的相似性比较来看,DNN-ImageNet都比DNN-Source具有更好的迁移性,这是因为尽管DNN-Source和目标任务学习的是同一物体的图像,但是他们的数据域相差太大,导致需要花费更多的成本去重建目标任务的特征空间。值得注意的是,有些层用于迁移甚至出现了负迁移的现象,负迁移经常出现在当用于迁移的源数据域和目标数据域相差很大的情况下,这说明在实验中,挑选一个合适的层用于迁移是十分重要的。上图是层迁移实验中的训练曲线,可以看到,由DEPARA挑选出来的层,迁移效果要好于其他层。而且,相比于DNN-Source,DNN-ImageNet中的训练曲线明显更加地平滑,这也恰恰证明了迁移性越好的模型,在迁移时所花费的重训练的成本就越低,也越容易地迁移至目标任务。“在‘AI训练师助手’的指导下,单个AI模型的生产周期从1个月降到1天,我们就能更快地发现不同的内容风险。”析策希望,欺凌、色情、暴力、误导等不良内容不会成为人们消费大量图像视频内容付出的代价,AI 技术可以更快地把不良内容挡在第一线。https://arxiv.org/abs/2003.07496https://github.com/zju-vipa/DEPARA
关注公众号:拾黑(shiheibook)了解更多
[广告]赞助链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
让资讯触达的更精准有趣:https://www.0xu.cn/

















 AI100
AI100
 关注网络尖刀微信公众号
关注网络尖刀微信公众号





